| 这个项目属于哪个课程 | 2024数据采集与融合技术实践 |
|---|---|
| 组名、项目简介 | 组名:scrapy能帮我爬到美味蟹黄堡的秘方吗 项目需求:文物不能很好的融入我们的生活,它们仿佛一具冰冷的尸体躺在博物馆的展示柜中,静静地接受着岁月的侵蚀和尘埃的覆盖。 项目目标:赋予文物新的生命力,让它们“动”起来。通过人工智能技术,为文物创造更加精彩动人的故事,生成曼妙的声音,制作生动震撼的展示视频,让历史以全新的方式触动人心。 技术路线:vue3前端web网站搭建,python flask后端,华为云平台(服务器接口调用),阿里云平台(部分数据存储),kimi背景故事AI生成,百度ai文本转语音,快手可灵ai平台对口型视频生成和通过接口实现视频生成 |
| 团队成员学号 | 曹星才-072208130 张诗悦-052205144 朱佳杰-012202239 黄悦佳-102202142 詹镇壕-102202149 |
| 这个项目目标 | 将静止的文物与现代科技相结合,赋予它们新的生命和表现力。我们通过先进的人工智能技术,让文物“动”起来,呈现出它们沉睡千年的故事与情感。AI将为每件文物创作更加丰富和感人的背景故事,让它们不再只是历史的见证者,而是活生生的叙述者。同时,通过AI生成曼妙的声音,让这些故事更加生动,引人入胜;借助视觉技术,生成精美的展示视频,生动再现文物的诞生过程、文化背景与历史场景。最终,我们希望通过这一系列创新方式,让更多人触及文物的灵魂,感受历史与文化的魅力。 |
| 其他参考文献 | https://element-plus.org/zh-CN/component/overview.html https://cn.vuejs.org/guide/introduction w3school 在线教程 uiverse.io Apache ECharts https://docs.qingque.cn/d/home/eZQClW07IFEuX1csc-VejdY2M?identityId=1oEG9JKKMFv#section=h.a6acy8mosh |
| 码云链接(代码已汇总,各小组成员代码不分开放) | 前端:综合设计实践——前端 ·2022级数据采集与融合技术 - 码云 - 开源中国 后端:综合设计实践——后端 ·2022级数据采集与融合技术 - 码云 - 开源中国 爬虫:https://gitee.com/jia1666372886/museumspider/tree/master/ |
一、项目背景
文物不能很好的融入我们的生活,它们仿佛一具冰冷的尸体躺在博物馆的展示柜中,静静地接受着岁月的侵蚀和尘埃的覆盖。那些曾经承载着历史脉络与文化荣光的物品,如今只剩下了沉默的外壳,无法向我们诉说它们曾经的故事。它们被时间的长河淹没,渐渐失去了与我们生活的联系,变成了一个个静止的符号,等待着被无数的目光定格,却难以真正融入现代人的日常。
这些文物或许曾在千百年前激荡起社会的波澜,或许曾是某个伟大文明的象征,但如今它们的存在仿佛和现代世界隔绝了。我们虽然能够从它们的外观上看到历史的痕迹,感受到当时的技艺与智慧,却难以触摸到那段历史背后的人情冷暖、风云变幻。它们不再是生活的一部分,而是被孤立在某个遥远的过去,只是某种文化的遗物。
然而,尽管它们远离了现代的喧嚣,文物依然是人类历史与文化的见证者。每一件文物都有自己独特的生命力,它们承载着前人的思想、情感和智慧。要想让文物重新焕发出活力,我们需要跨越时空的藩篱,用现代科技去唤醒它们沉睡的记忆。通过人工智能、虚拟现实等技术,文物可以不再是冰冷的展品,而是成为我们与过去沟通的桥梁。它们能够重新讲述那个时代的故事,带领我们走进千年之前的世界,让我们重新感受到历史的脉搏和文化的力量。
在这个数字化、智能化的时代,我们不妨通过创新的方式,去打破文物与现代生活之间的隔阂,让这些承载着历史与文明的珍宝重新走进我们的生活,让它们不再只是博物馆里的静物,而是活跃在我们日常的对话和思考之中。
二、项目分工
| 成员 | 任务 |
|---|---|
| 曹星才 | 前端页面设计,接口调度与路由跳转逻辑,js代码编写 |
| 张诗悦 | 前端页面设计,web原型设计,css样式与html框架设计 |
| 朱佳杰 | 文物信息爬取 |
| 黄悦佳 | 后端服务器搭建与数据库管理 |
| 詹镇壕 | 后端服务器搭建与api接口编写 |
三、个人贡献
在本次小组实践当中,我负责的主要任务如下:
1.华为弹性云服务器配置搭建,并配置python和mysql环境。
由于我们的项目服务器的性能需求要求不高与经济原因,选择4G(运存)2核的鲲鹏通用计算增强型CPU框架,基本上能满足我们的后端运行的需求。

然后,进行python和Mysql环境的配置
分别选择兼容性较强的python3.8和mysql5.7版本

分别通过Xshell,Vscode上的远程连接mysql插件在服务器进行操作
2.后端python-flask框架的云服务器配置运行,并进行日常维护,更新。
管理并运行python——flask后端框架

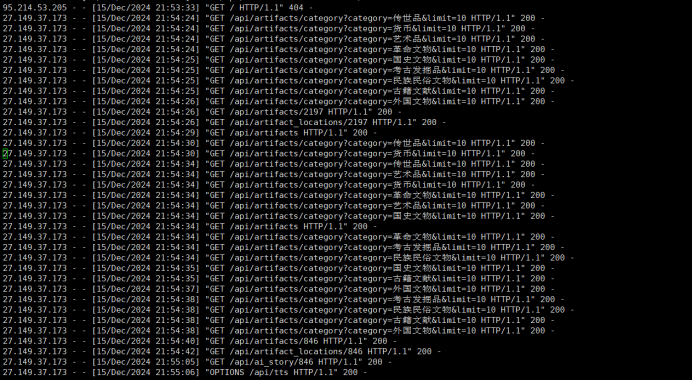
通过log日志发现并修复开发中遇到的种种问题,保证服务端的正常运行
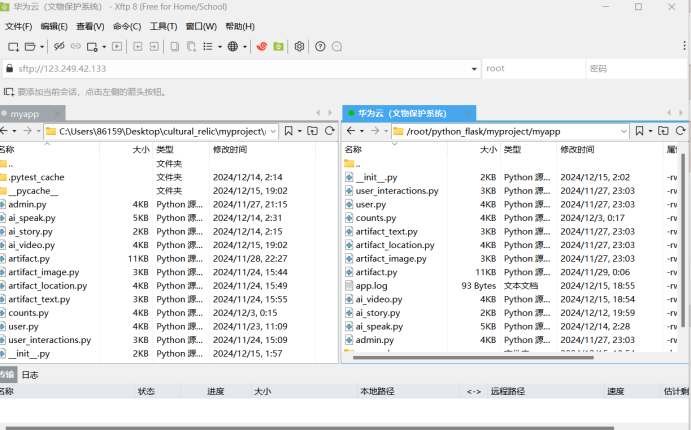
使用Xftp工具实现本地与服务器之间快捷的文件传输,便于后端的更新维护
3.文物故事文字转语音api接口配置及代码编写测试。
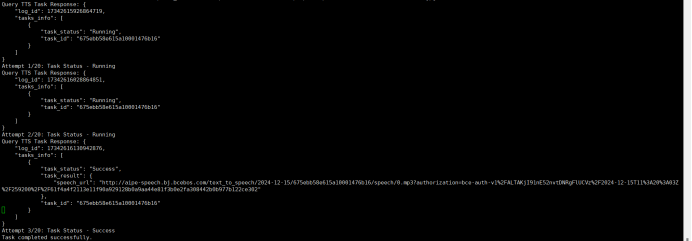
采用百度千帆大模型的语音合成api接口来实现实时文物故事转语音功能
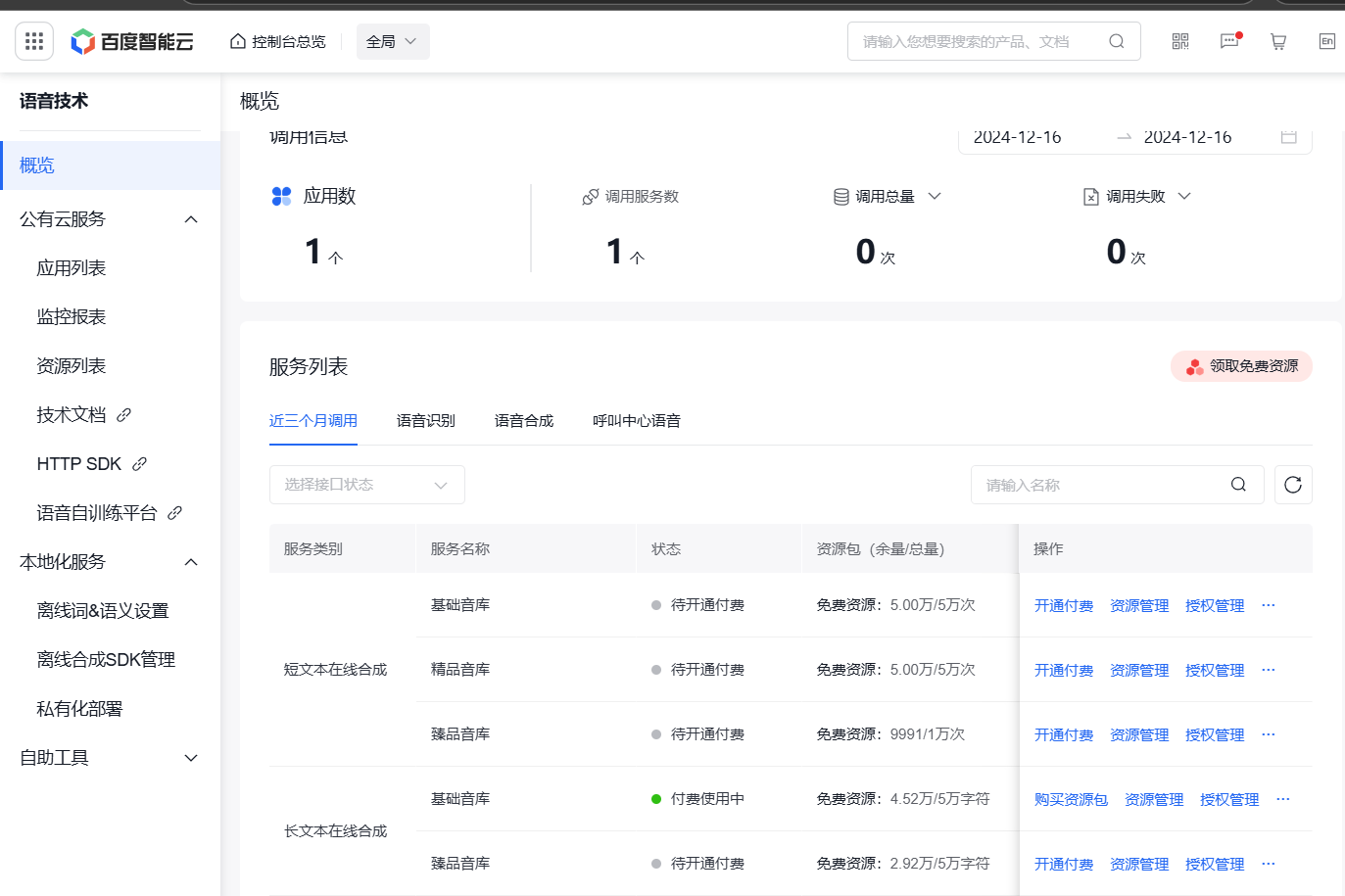

4.同时,我协助詹镇壕同学进行flask后端接口的一系列测试和
python-flask后端框架
接口测试代码

四、收获
个人能力的提升
- 1.掌握小型应用服务器搭建配置流程,配置所需的语言环境,搭建数据库,并尝试学习了flask框架服务器的运行和维护。
- 2.调用了百度的api接口实现文字实时转语音功能,对AI大模型有了进一步的了解。
- 3.模块化的代码以及测试程序编写,将应用的功能分解,不仅有利于减小程序设计的难度,同时也方便了bug的查询与修改,测试程序则有利于后端开发成员之间的交流,也有利于前端理解api接口的具体情况并进行调用。
团队协助意识的培养
- 在本次小组实践中,我们采用前后端以及数据采集分离的方式进行开发。在同一分工小组中,我们要积极交流合作,共同推进任务,和其他小组对接时,也需要积极沟通,前端遇到问题,及时反馈并解决,这样的合作开发模式大大提高了工作完成的速度,也帮助我们了解不同部分的职能,加强团队合作精神意识的培养。
对大数据技术的深入了解
- 在本次项目中,我进一步了解了大数据技术在应用项目开发中发挥的作用。大数据技术作为关键支撑,在数据采集、处理、存储以及分析中扮演了至关重要的角色。数据采集技术是大数据技术的基石,在此基础上,一系列大数据分析处理才能展开。在未来,结合AI技术与云平台,相信在大数据技术一定能作为一股更强大的动力,推动行业发展。
五、个人总计
- 通过这次的综合实践,我不仅在个人技术能力方面得到提升,也增添了团队合作的经验和意识,更对ai大模型和大数据技术有了更深入的理解,相信这次的经历不仅对当下,也对未来的自己产生积极正面的影响。