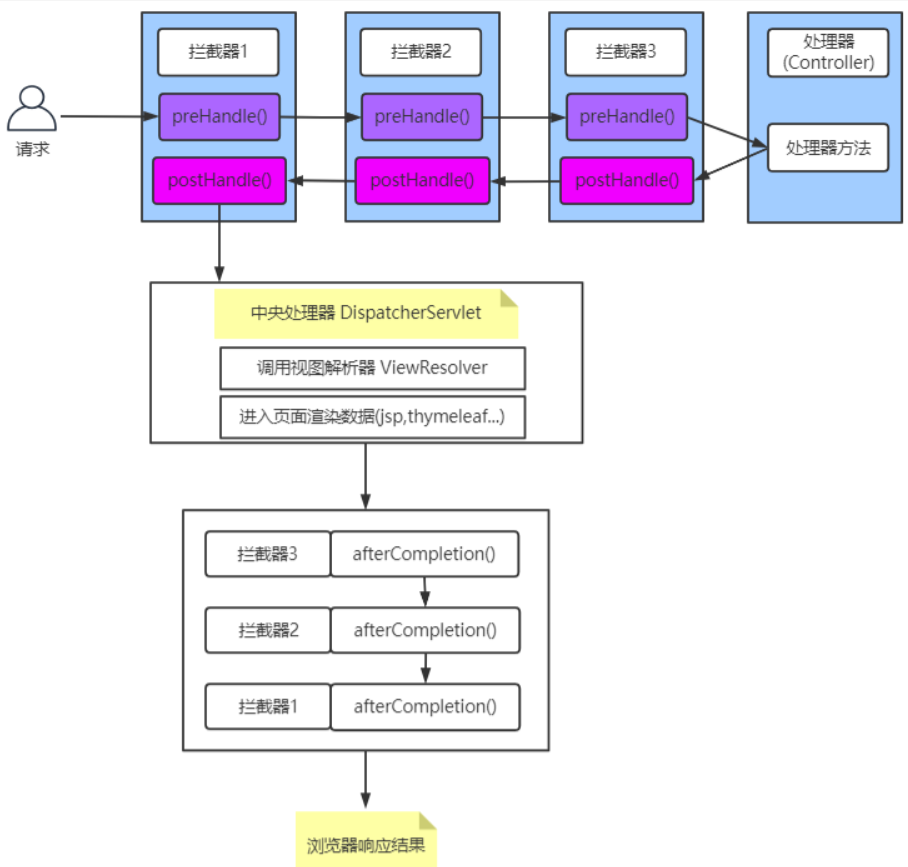
线程
页表
每个进程都有一个虚拟地址空间,虚拟地址通过页表的映射找到对应的物理地址。那页表是如何完成虚拟地址到物理地址的映射的呢?其实一个程序在磁盘上的时候就以4KB为单位被划分成块,每一块称为页帧;而物理内存同样是以4KB为单位被划分,每一块称为页框。所以程序都是以4KB大小为单位被加载到内存。在32位平台下有232个虚拟地址,如果将这些地址都放到页表中,光是页表都会占用不少空间。因此,为了节省内存空间页表不可能只有一张,它其实是一个多级页表。以二级页表为例,它会将32个比特位划分为10,10,12的形式。前10位放在一张表中,称为页目录;下个10位存放在另一张表中,称为页表;最后12位存放的其实是在物理内存中的偏移量,因为212刚好是4KB,而物理内存又是以4KB为一个单位,当通过前20个比特位找到在哪一个页框后,然后通过后12位找到具体位置。
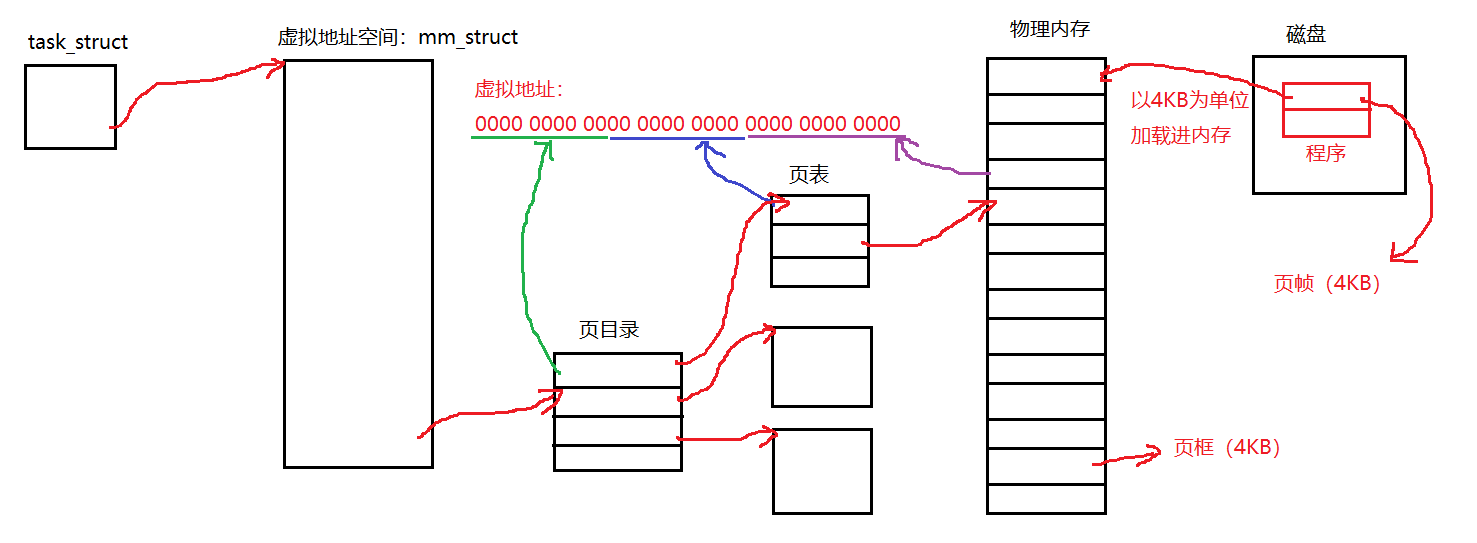
关于地址空间和页表有如下结论:
- 地址空间是进程能看到的资源窗口。
- 页表决定进程真正拥有资源的情况。
- 合理的对地址空间+页表进行资源划分,我们就可以对一个进程的所有资源进行分类。
认识线程
什么是线程
线程其实就是进程内部的一个执行流,在进程的地址空间内运行,拥有该进程的一部分资源。有了线程之后,线程成了CPU调度的基本单位,进程是承担系统资源分配的基本实体。
那么如何理解进程和线程呢?这就好比有一个项目小组,你是这个组的组长,当项目资金不够时,组员并不会直接向老板申请资金,而是向你申请,由你去向老板申请;当资金下来的时候,再由你去进行分配。在这个例子中,你就相当于进程,而组员是线程。
Linux下的线程
线程被创建出来就是为了被执行和被调度的,它同样有自己的id,状态,优先级,上下文等属性。单纯从线程调度角度,线程和进程有很多地方是重叠的。所以在Linux中为了更简单方便的管理线程,并没有给线程再设计对应的数据结构,而是直接复用进程PCB,用进程PCB来表示Linux内部的“线程”。所以在Linux内部并没有真正意义上的线程,它只是用进程PCB来模拟线程,模拟出来的线程比传统意义上的进程更加轻量化,称为轻量级进程。
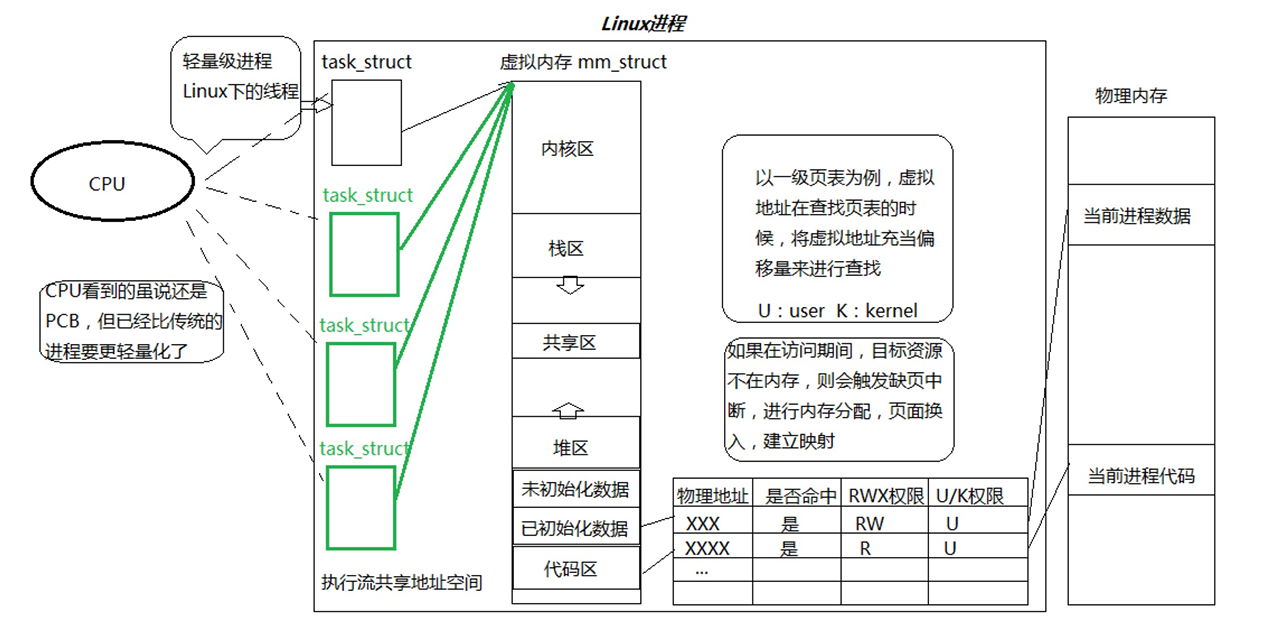
在Linux中创建线程其实就是创建了很多个PCB(task_struct),这些PCB指向同一个虚拟内存,然后我们通过虚拟地址空间+页表的方式对进程进行资源划分,让每个PCB都拥有该进程的一部分资源去完成不同的任务。
线程的私有属性
进程的多个线程共享同一地址空间,所以代码段,数据段都是共享的。比如定义一个函数,在各个线程中都可以调用,如果定义一个全局变量,在各个线程中也都可以访问到。除此之外线程还共享如下资源:
- 线程共享进程打开的文件描述符。
- 线程共享进程的信号处理函数设置。
- 线程共享所属进程的进程 ID 和父进程 ID。
- 线程共享进程的当前工作目录。
当然线程也有自己的私有属性,比如:
-
PCB内的属性私有。
在多线程环境下,虽然线程共享进程的很多资源,但每个线程在 PCB 中有自己的一些私有属性。这些属性主要用于记录线程自身的执行状态,例如线程的执行状态(就绪、运行、阻塞等)是线程私有的。因为每个线程的执行进度和等待原因可能不同,所以需要单独记录这些信息来实现线程的独立调度。不同的线程可以有不同的优先级,而这些优先级信息是每个线程独立维护在 PCB 中的,以确保每个线程能够按照其优先级参与系统的调度过程。
-
有自己的私有上下文结构。
线程的上下文包括了程序计数器、寄存器值等信息。线程有自己的私有上下文结构,这是因为每个线程的执行路径和执行状态是不同的。例如,当一个线程在执行一个复杂的函数调用,在函数执行的中途被切换出去,它的上下文(如当前正在执行的指令地址,即程序计数器的值,以及寄存器中存储的函数局部变量的值等)需要被保存起来。当这个线程再次被调度执行时,通过自己的私有上下文结构可以恢复到之前的执行状态,继续执行函数调用,而不会与其他线程的执行状态混淆。
-
有自己独立的栈结构。(在一个共享的变量前添加
__thread,可以将一个内置类型设置为线程局部存储)每个线程有独立的栈结构,这是为了保证函数调用的独立性和局部变量的安全性。例如,当一个线程调用一个函数,函数的参数和局部变量会被压入该线程的栈中。如果线程没有独立的栈,多个线程的函数调用可能会相互干扰,导致栈数据混乱。
线程和进程
线程和进程的关系如下:
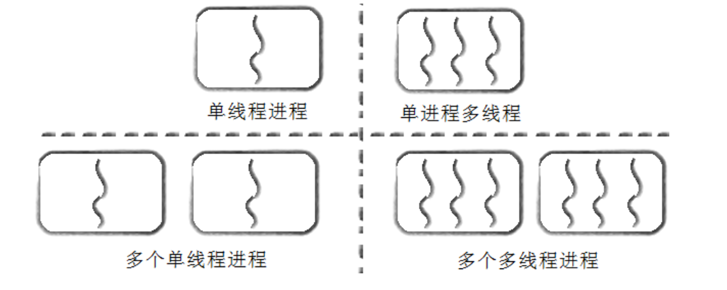
对于之前说的单进程,其实就是只具有一个线程执行流的进程。
与进程切换相比,线程切换需要操作系统做的工作就要少很多。
-
进程切换:切换页表、虚拟地址空间、PCB、上下文。
-
线程切换:切换PCB、上下文。
-
还有一个就是线程切换不用太更新CPU上的Cache,而进程切换就要全部更新。这也导致线程的切换效率比进程的切换效率高。
由于程序的局部性原理,在CPU上的Cache上会存储CPU 近期可能会频繁访问的数据和指令。当 CPU 需要读取数据或指令时,首先会在 Cache 中查找。如果 Cache 命中(即找到了所需的数据或指令),则直接从 Cache 中读取,这个过程速度很快,通常只需要几个 CPU 周期。如果 Cache 未命中,则需要从主存中读取数据或指令,并将其加载到 Cache 中,同时将读取的数据或指令返回给 CPU。这个过程相对较慢,因为涉及到主存的访问。
所以当一个程序运行起来,Cache上存储的都是一些热点数据,若进行进程切换,这些热点数据都会消失,到了下次切换回来的时候又要全部重新加载。而线程切换只是会更新部分数据,这就导致了线程切换的效率要比进程切换的效率高的多。
线程创建
- 由于Linux中并没有线程的概念,所以Linux本身没有提供操作线程的接口,只提供对轻量级进程操作的接口。但是对于用户来说,我们只认线程。所以在用户和Linux操作系统之间有人对轻量级进程的接口做封装形成了一个库,这个库能让用户以操作线程的方式来操作轻量级进程。
- 如果使用了这个库,编译时记得加上
-lpthread选项。- Linux中提供操作轻量级进程的接口是:
int clone();
相关接口
函数原型:int pthread_create(pthread_t *thread, const pthread_attr_t *attr, void *(*start_routine)(void*), void *arg);
参数:
thread:这是一个指向pthread_t类型的指针。pthread_t是用于表示线程标识符(Thread ID)的数据结构。当pthread_create()函数成功创建一个线程后,会将新线程的标识符存储在thread所指向的内存位置,通过这个标识符可以在后续操作中引用该线程。attr:这是一个指向pthread_attr_t类型的指针,用于指定线程的属性。线程属性包括线程的栈大小、调度策略、优先级等信息。如果不需要特殊的线程属性,可以将这个参数设置为NULL,此时线程将使用默认属性创建。start_routine:这是一个函数指针,指向线程启动后要执行的函数。arg:用于传递给start_routine函数的参数。这个参数可以是任何类型的数据,通过将数据的指针转换为void*类型来传递给线程函数。
返回值:成功返回0,失败返回非0的错误码。
创建线程
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include <cassert>void* thread_routine(void *arg)
{const char *name = (const char*)arg;while (true){std::cout << name << ": 我是一个新线程,我正在运行" << std::endl;sleep(1);}
}int main()
{pthread_t tid;//创建新线程int n = pthread_create(&tid, nullptr, thread_routine, (void*)"thread one");assert(n == 0);(void)n;while (true){std::cout << "main: 我是主线程,我正在运行" << std::endl;sleep(1);}return 0;
}
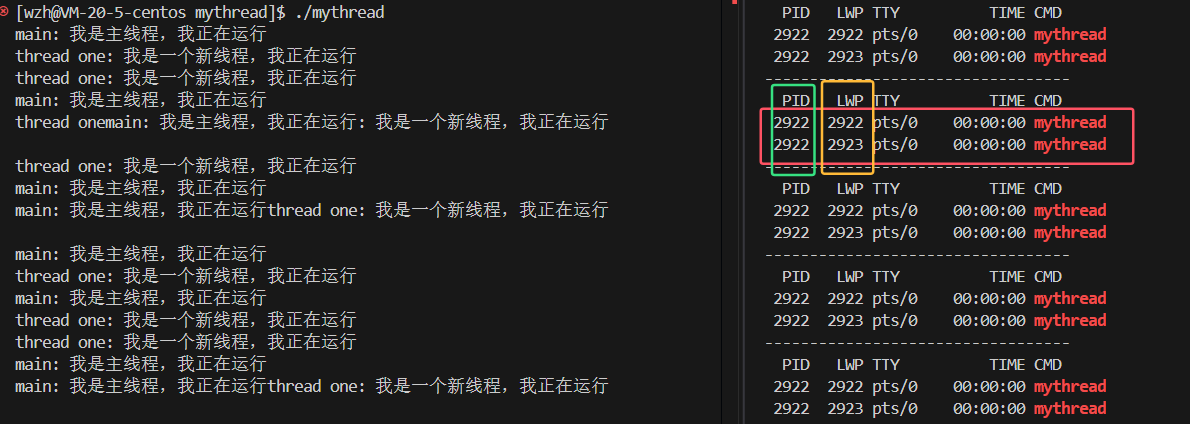
打印出来是乱序的,是因为当新线程被创建出来后,主线程和新线程执行的先后顺序并不确定。
LWP 和 tid
通过ps -aL命令查看两个线程的ID,发现它们的pid相同,并且还多出了一个不同的lwp。lwp其实就是Light Weight Process的缩写,也就是轻量级进程。pid与lwp相同的是主线程,不同的是新线程。
我们将主线程的输出改一改,让它能够打印出新创建线程的id。
std::cout << "main: 我是主线程,我正在运行!我创建出来的线程的tid: " << tid << std::endl;

这里发现我们打印输出的tid和使用ps -aL命令查到的不一样,也就是说我们打印输出的根本不是tid。实际上这里输出的其实是一个地址,如下

之前说过,在Linux中并没有线程的概念,只是有人封装了一个线程库来操作轻量级进程。所以我们在Linux下对线程的操作都要通过这个库实现。为了管理轻量级进程,在这个线程库中有一个对应的数据结构来描述轻量级进程。所以这个地址其实就是每一个结构体对象的地址。
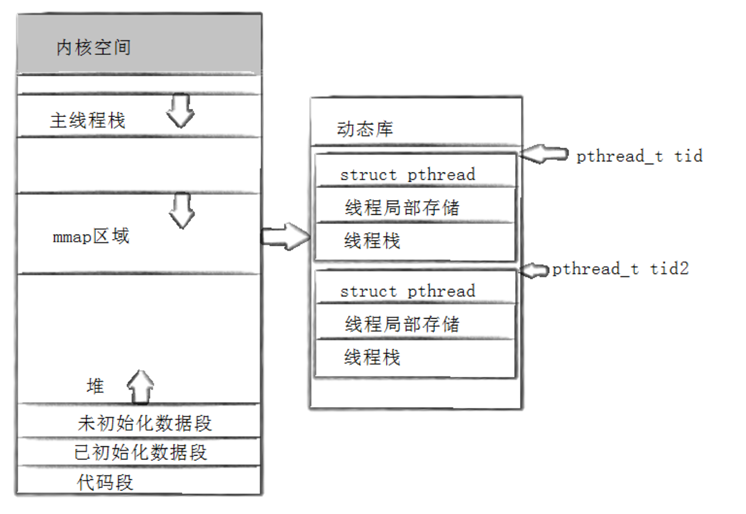
这个地址(也就是tid)是线程库给我们提供的,操作系统并不知道。操作系统为了表示它所知道的轻量级进程的唯一性,所以就又有了一个lwp,操作系统通过这个ID来进行调度。也就是说线程库提供的tid是属于用户级别的,而操作系统提供的lwp是属于内核级别的。
线程终止
终止一个线程有三种方法
-
从线程函数
return。这个方法不适用于主线程。 -
线程自己调用
pthread_exit终止。函数原型:
void pthread_exit(void *retval);参数:这个返回值可以是任何类型的数据,只要将其转换为
void *类型即可。例如,如果线程执行了一个计算任务,返回值可以是计算结果的指针;如果只是用于表示线程的状态,也可以是一个表示状态的整数(转换为void *类型)等。注意:终止线程不能适用
exit()函数,这个函数是用来终止进程的。也就是说如果使用该函数来终止线程,那么所有的线程都会终止。 -
调用
pthread_cancel来终止另一个线程。函数原型:
int pthread_cancel(pthread_t thread);参数:表示要取消的线程的标识符。这个标识符是在创建线程时通过
pthread_create()函数返回并存储的,并不是lwp。
终止线程也不能使用信号来终止,信号是用来终止一个进程的。对于操作系统来说,如果进程中的一个线程出问题了,那么它会发送信号来直接终止这个进程。
线程等待
线程同样要进行等待,如果不等待会造成类似僵尸进程的问题,导致内存泄漏。
函数原型:int pthread_join(pthread_t thread, void **retval);
参数retval:它是一个输出型参数,用来获取线程函数结束时的返回值。线程函数结束时,直接将返回值当成一个地址保存在线程库中。我们在外部创建一个void * ret类型的变量,然后将ret变量的地址传过去,然后线程库内部会将我们传过去的ret变量的地址进行解引用操作,将返回值赋值给解引用后的ret。
#include <iostream>
#include <pthread.h>
#include <unistd.h>
#include <cassert>
#include <cstdio>void* thread_routine(void *arg)
{const char *name = (const char*)arg;int cnt = 5;while (cnt){std::cout << name << ": 我是一个新线程,我正在运行" << "cnt: " << cnt--<<std::endl;//退出结果为1111if (cnt == 0) pthread_exit((void*)1111);sleep(1);}
}int main()
{pthread_t tid;//创建新线程int n = pthread_create(&tid, nullptr, thread_routine, (void*)"thread one");assert(n == 0);(void)n;void *ret = nullptr;//等待新线程pthread_join(tid, &ret);printf("thread one 的退出结果是: %d\n", (int*)ret);return 0;
}
线程分离
-
调用
pthred_join()等待线程其实是一种阻塞式等待,我们可以通过线程分离让线程不再需要去等待另一个线程,并且另一个线程在结束后还能自动释放自己的资源。 -
默认情况下,新创建的线程是joinable的,joinable和分离是冲突的,一个线程不能既是joinable又是分离的。
函数原型:int pthread_detach(pthread_t thread);
-
自己分离自己(不推荐)
std::string changeId(const pthread_t &thread_id) {char tid[128];snprintf(tid, sizeof(tid), "0x%x", thread_id);return tid; }void *start_routine(void *args) {std::string threadname = static_cast<const char*>(args);//将自己设置为分离状态pthread_detach(pthread_self());int cnt = 5;while (cnt--){//pthread_self()用来获取调用线程的tidstd::cout << threadname << "running ... : " << changeId(pthread_self()) <<std::endl;sleep(1);}return nullptr; }int main() {pthread_t tid;pthread_create(&tid, nullptr, start_routine, (void *)"thread one");std::string main_id = changeId(pthread_self());std::cout << "main thread running ... new thread id: " << changeId(tid) << "main thread id: " << main_id <<std::endl;sleep(2);int n = pthread_join(tid, nullptr);std::cout << "result: " << n << " : " << strerror(n) << std::endl;return 0; }由于创建出新线程后,主线程和新线程执行的先后顺序不确定,所以在上面这份代码中一定要让新线程分离成功后再
join,这样join才会失败。如果将30行的sleep(2);注释掉,你会发现你仍然能成功join新线程。 -
由主线程分离创建出来的线程
std::string changeId(const pthread_t &thread_id) {char tid[128];snprintf(tid, sizeof(tid), "0x%x", thread_id);return tid; }void *start_routine(void *args) {std::string threadname = static_cast<const char*>(args);int cnt = 5;while (cnt--){std::cout << threadname << "running ... : " << changeId(pthread_self()) <<std::endl;sleep(1);}return nullptr; }int main() {pthread_t tid;pthread_create(&tid, nullptr, start_routine, (void *)"thread one");std::string main_id = changeId(pthread_self());//创建出新线程后立马进行分离pthread_detach(tid);std::cout << "main thread running ... new thread id: " << changeId(tid) << "main thread id: " << main_id <<std::endl;int n = pthread_join(tid, nullptr);std::cout << "result: " << n << " : " << strerror(n) << std::endl;return 0; }如上这种情况就一定会
join失败,因为主线程创建出新线程后立马进行分离,一定先执行的是分离的操作,后执行的join操作。