一、目标
懂得AI,懂得编程、懂得业务的超级个体,将会是AGI时代最重要的人。
AI使得一个人能够干多个人的活
想要做到“AI全栈”需要涉及的知识面是非常广泛的,单单学习一门课程是不能全部涉及的
我们首先需要做的是入门,后面走的深入,走的远只能靠自己,依靠社群,和AI的进化。
入门AI全栈需要从三个方向入手:
(1)原理
(2)实践
(3)认知
注意:在现在这个时代,不要只是拿代码说事。
目前,行业的共识是:两个确定和一个不确定:
(1)确定未来-AI必然重构世界
(2)确定进入-想要收获红利,必须现在进入
(3)不确定落地-解决什么需求,技术路线,产品策略都是什么,确定性还是很低
等到不确定的因素确定了,代码的价值才是巨大的。
注意:学习的时候需要将能够听懂的多多实践,然后听不懂的直接记录下来,等到时机到了的时候然后慢慢再开始。
二、什么是AI
最重要的一点是区分什么是AI系统,什么不是AI系统?

目前来说只有基于机器学习神经网络的这种才是真正的AI
而使用规则和搜索的并不是AI
三、大模型能够干什么?
大模型,全称-大语言模型,英文叫做Large Language Model,缩写LLM
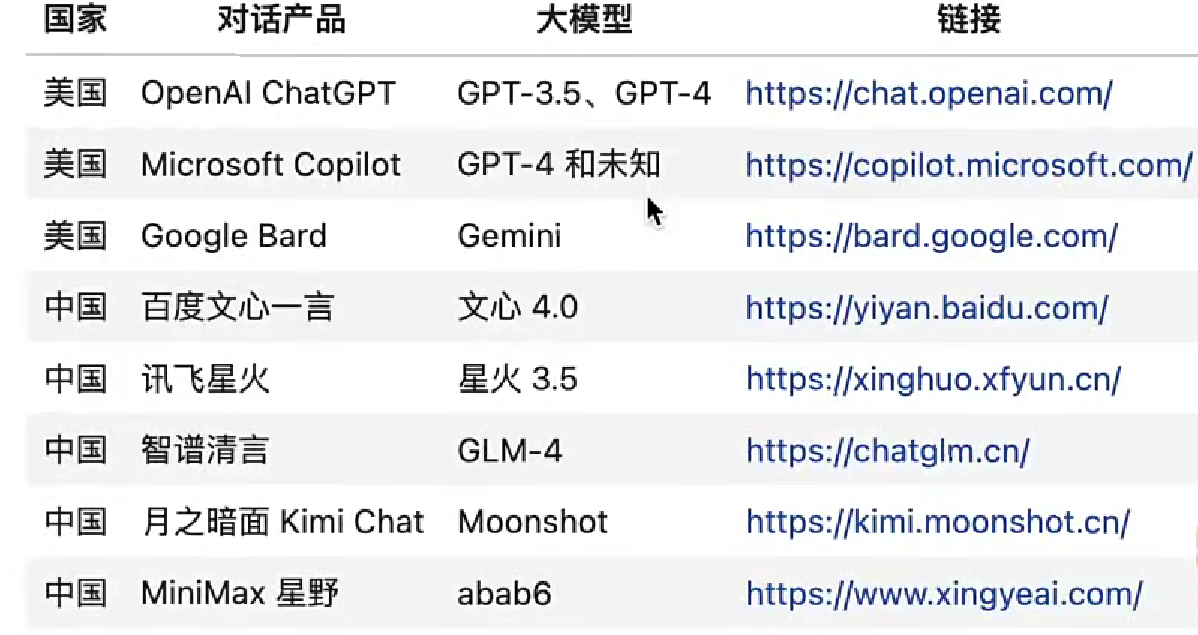
什么是对话产品,什么是大模型?
对话产品和大模型是两件事情。
只是这个对话产品背后调用了大模型。
产品不是AI,只是包装了这些大模型。
所以需要有一个访问国外的通道,否则是无法拥有顶级的体验的。
注意:千万不要只将大模型只是当作聊天机器人,它们的能量远远不止于此。
(1)按照指定的格式输出

(2)分类

(3)聚类

(4)持续的互动

(5)技术的相关问题

可能一切的问题都是能解决的,所以是AGI(Artificial General Intelligence)
这才是真实的
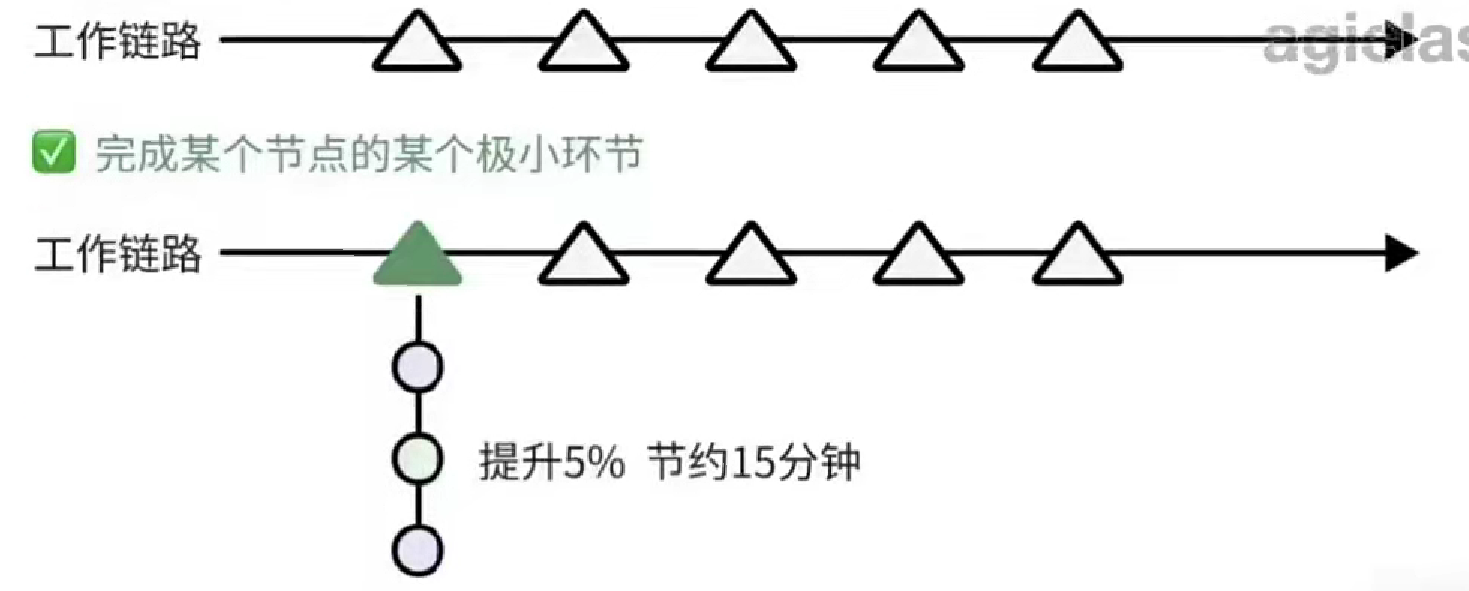
四、大模型是怎样生成结果的?
通俗的理解:

OpenAI的接口名字叫做completion,证明了只会生成的本质。
用不严谨但是通俗的语言描述大模型的工作原理:
(1)大模型阅读了人类曾说过的所有的话,这就是机器学习,这个过程叫做训练。
(2)将一串token后面跟着不同的token的概率存入神经网络,存储的数据就是参数,参数也叫做权重
(3)当我们给它若干token,大模型就能够计算出概率最高的下一个token是什么。这就是生成,也叫推理
(4)使用生成的token,再加上上文,就能继续生成下一个token,以此类推,生成更多的文字。
token可以认为是大模型在进行机器学习训练以及推理过程时候处理的那个资源的最小单位。
AI做对了一件事情,如何解释?最简单的解析是之前这个模型学习的时候之前就有这个问题。之前的训练数据里面有这个问题的答案。
AI胡说八道的原因是因为生成的是概率最高的就行了。
这套生成机制的架构是一个叫做Transformer的架构

除了Transformer还有其他的更加先进的架构出现。
用好AI的核心是将AI当人看。
五、ai解决问题的方式
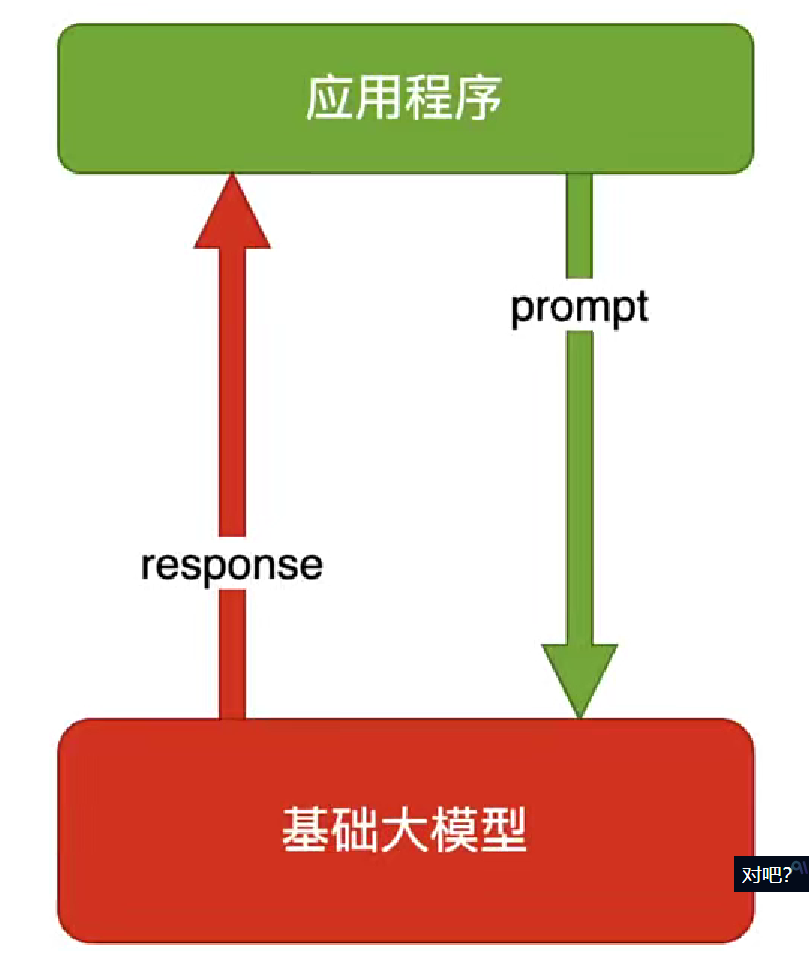
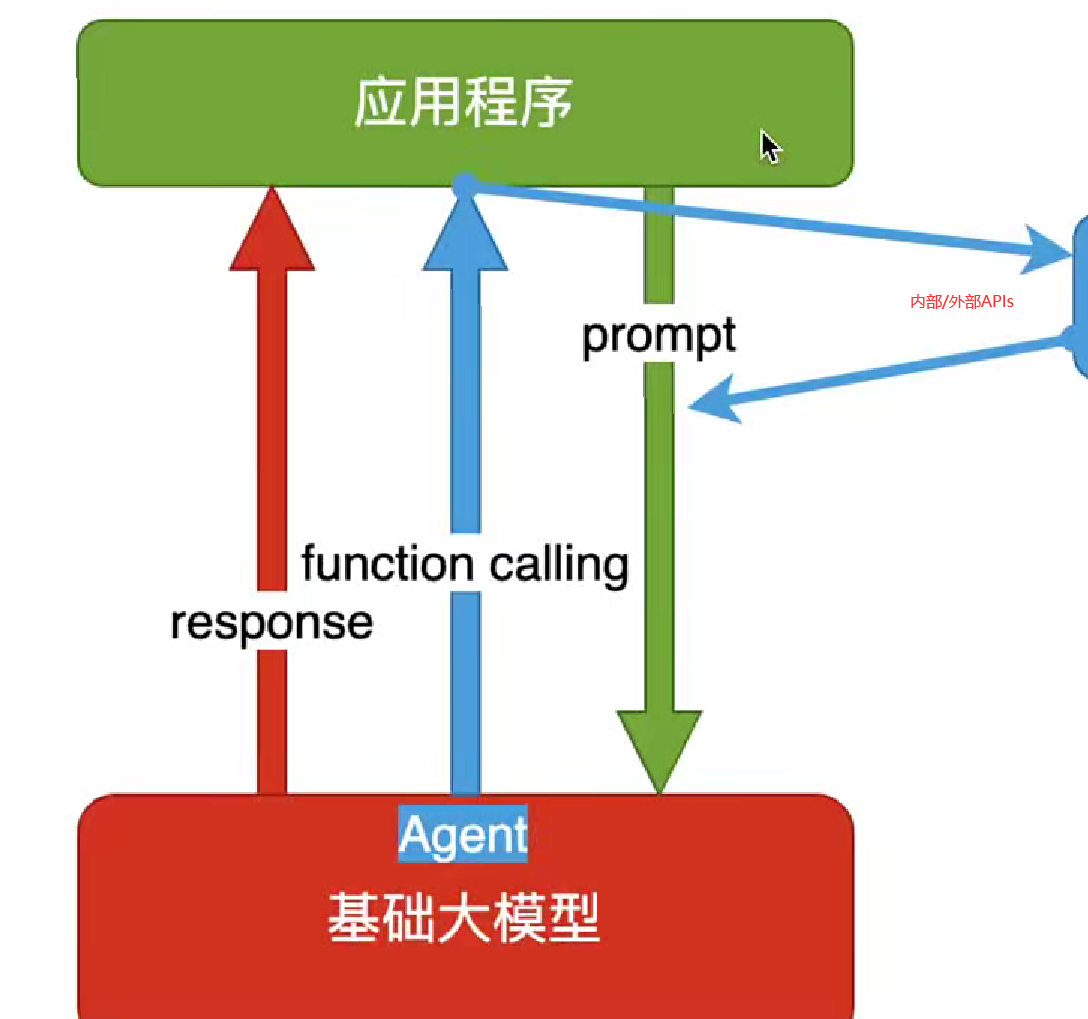
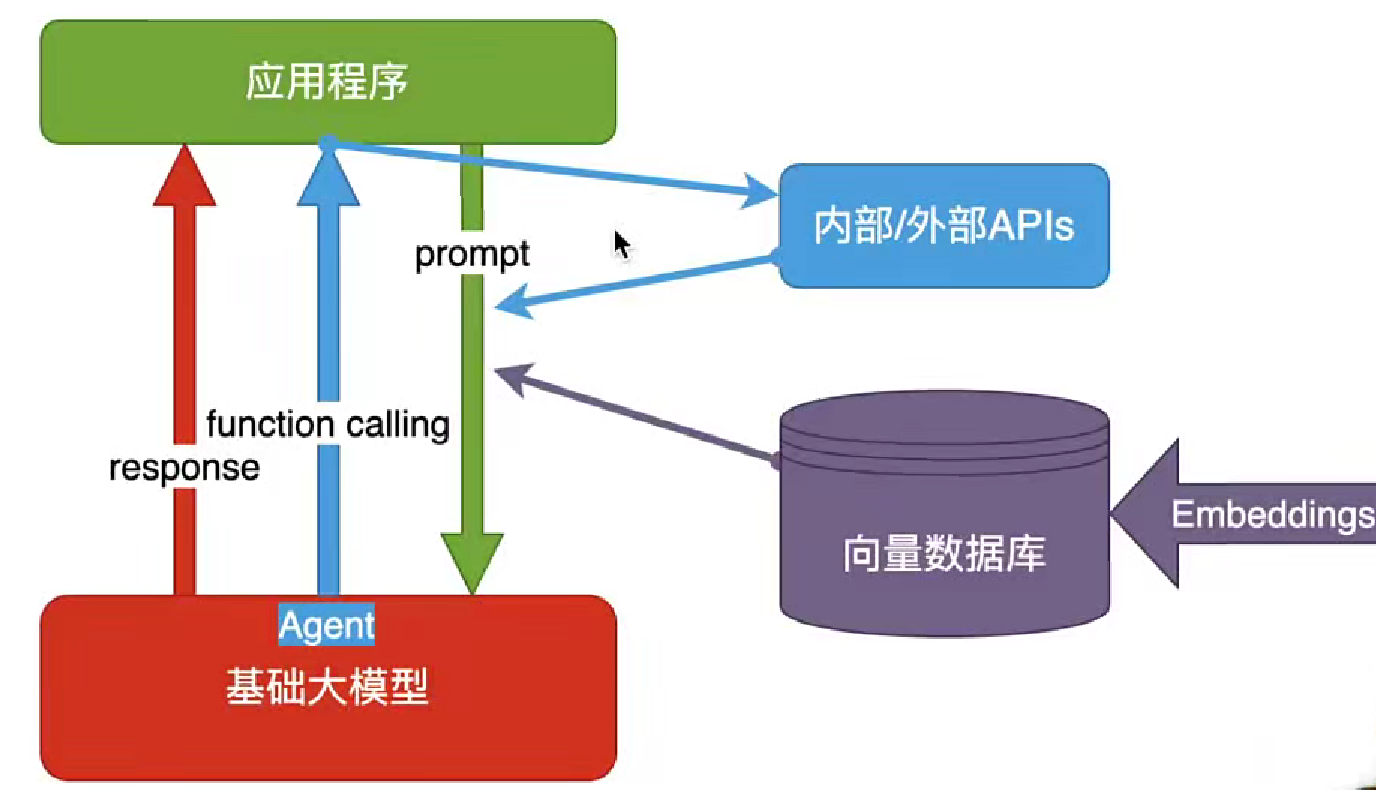
这种方式可以理解为一种开卷考试
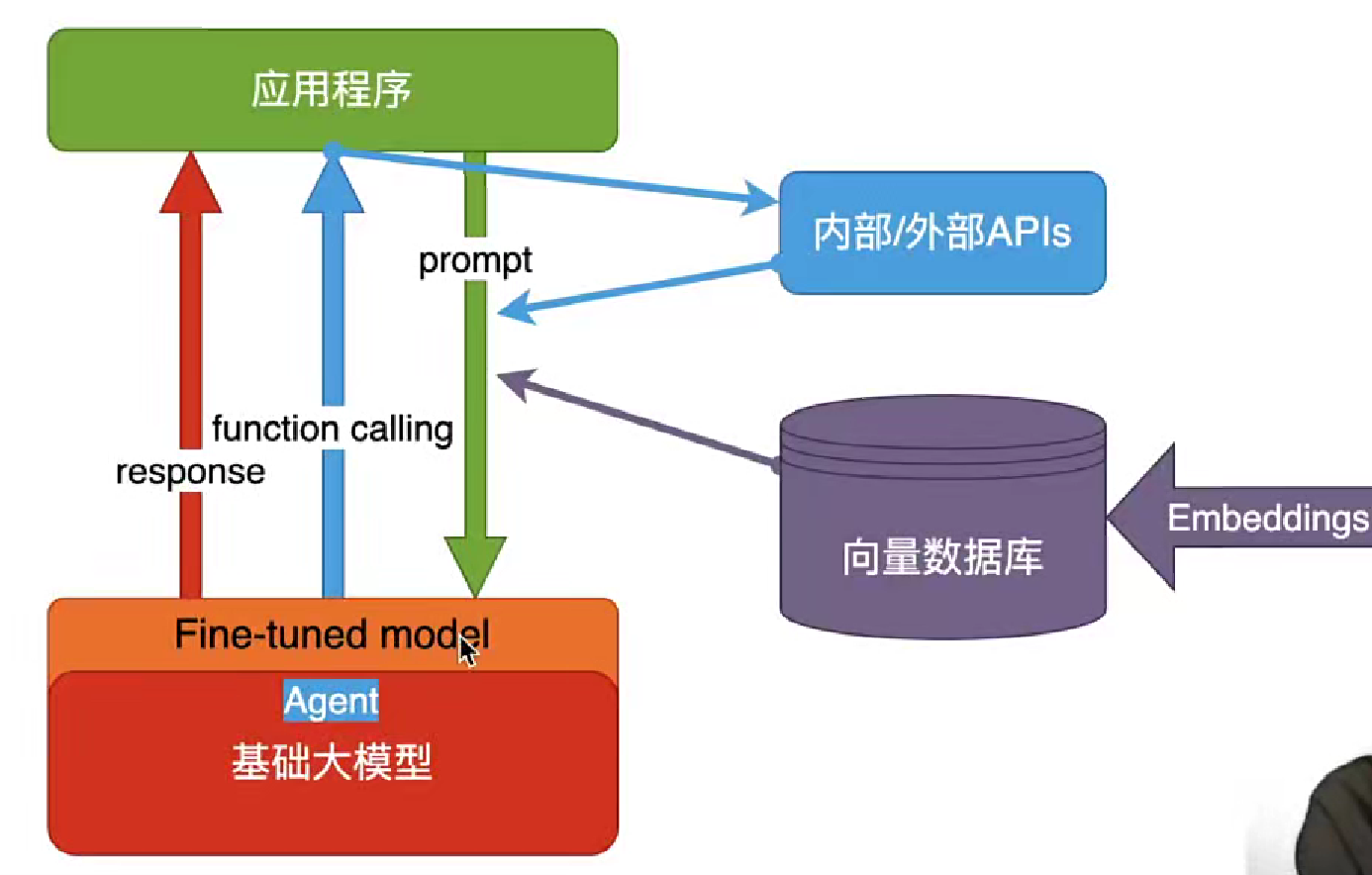
三好学生,懂得学习,活学活用
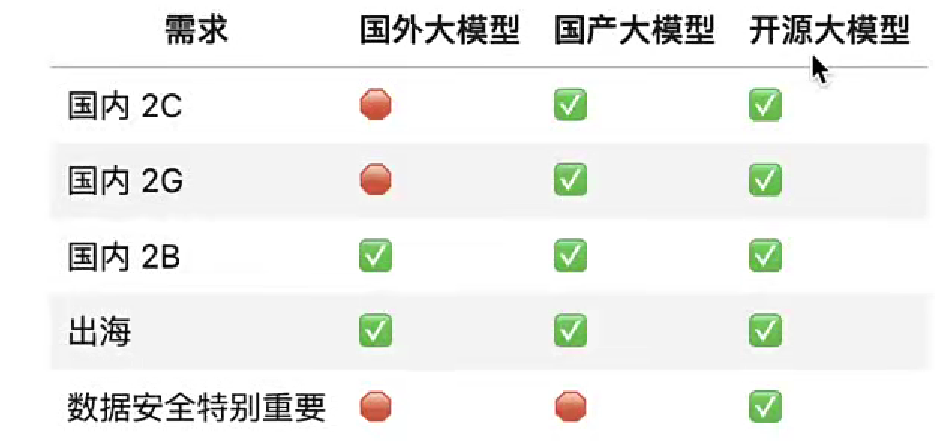
大模型选型表格:
安装openai
pip install --upgrade openai