1. 熵
1.1. 熵是物理学上的一个术语,本质上是一个系统“内在的混乱程度”
1.2. 是我们的敌人
2. 执行缓慢的遍历
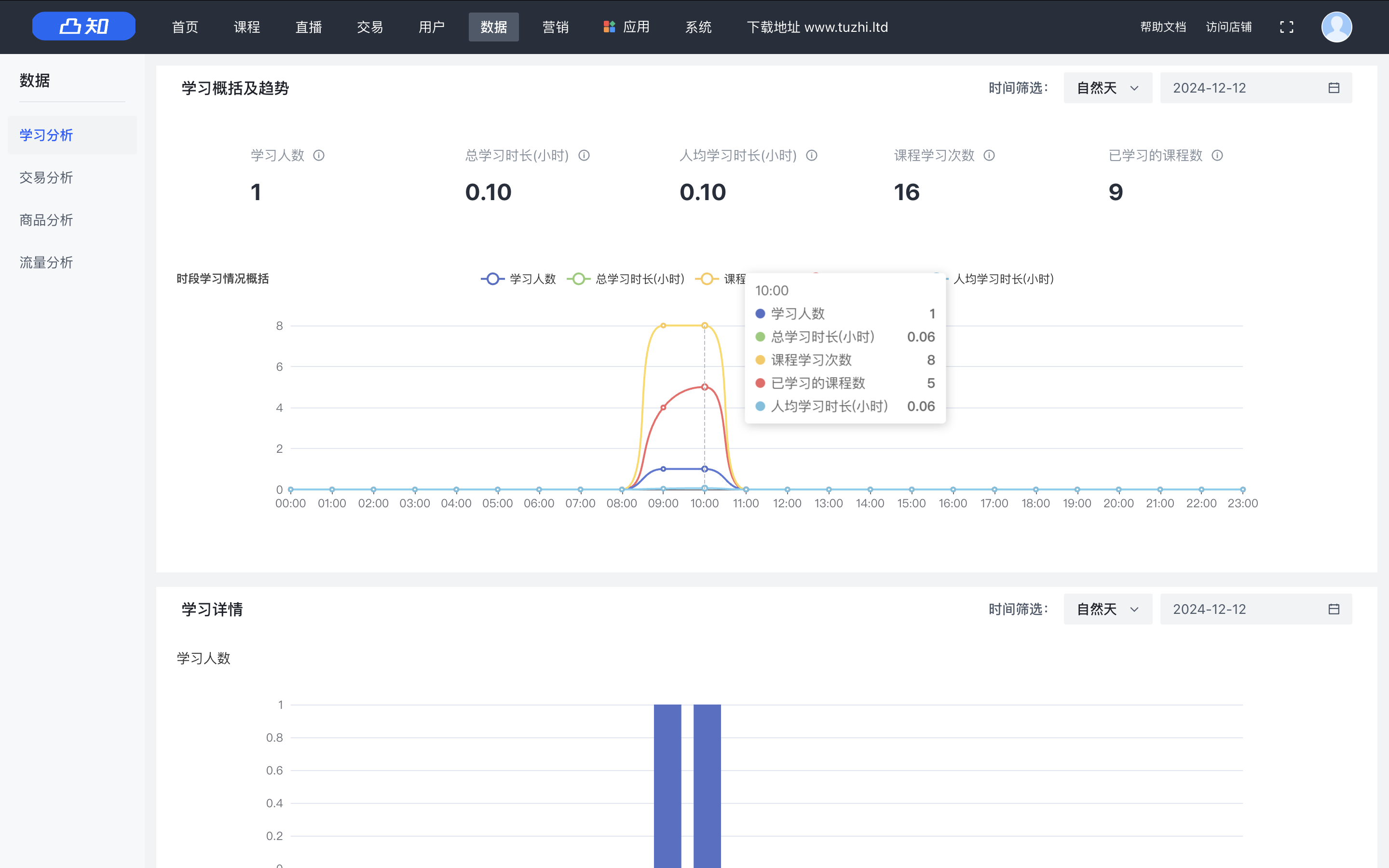
2.1. 和关系数据库一样,图数据库对于执行缓慢的操作并不陌生
2.2. 图也有帮助诊断问题的工具
-
2.2.1. 解释一个遍历会做什么
-
2.2.2. 分析一个遍历做了什么
2.3. 在遍历开始时指定筛选可以防止遍历搜索所有顶点
2.4. 解释遍历
-
2.4.1. explain()操作很少是我们排除错误的第一步
-
2.4.2. 使用explain()操作定位执行糟糕的遍历,需要对数据库的内部工作原理有深入的理解
-
2.4.3. explain()操作是不同数据库实例都具备的常用工具
-
2.4.4. 大多数图数据库是通过explain()操作执行此类调试操作的
-
2.4.5. explain()操作告诉我们一个遍历是如何执行的
2.5. 分析遍历
-
2.5.1. 通过使用profile()操作来实现的
-
2.5.2. profile()操作运行遍历并收集执行过程中有关性能特征的统计信息
-
2.5.3. 统计信息包括执行的细节
-
2.5.3.1. 表示的遍历的数量(Count)
-
2.5.3.2. 实际的遍历器的数量(Ts或Traversers)
-
2.5.3.3. Count和Traversers(即Ts列)的值并不总是一样的
> 2.5.3.3.1. 遍历器会被合并到称为膨胀(bulking)的Gremlin进程里,从而导致Count的值大于Traversers的值
-
2.5.3.4. 在该操作上耗费的时间(Time)
-
2.5.3.5. 在该操作上耗费的时间在整个遍历执行时间中的占比(%Dur)
-
2.5.4. profile()操作则告诉我们执行过程中发生了什么
-
2.5.5. 分析遍历需要消耗额外的资源,所以其表示的时间未必等同于没有经过分析的遍历
2.6. 如果我们发现耗时最长的操作有很多遍历器,我们应该在这个操作之前增加额外的筛选,以减少所需要的遍历器
2.7. 索引
-
2.7.1. 图数据库中的索引提供一种基于预设条件的高效数据查找方法
-
2.7.1.1. 索引带来了效率的提升,同时也带来了额外的存储和写入开销
-
2.7.2. 索引的工作原理是允许我们快速、直接访问所需数据,而不需要扫描整张图
-
2.7.2.1. 索引会产生针对特定条件优化获取数据过程所需要的数据冗余副本或数据指针
-
2.7.3. 避免扫描整张图能带来极大的性能改善
-
2.7.3.1. 在索引内执行一次查找肯定比查看数千、数百万甚至数十亿个顶点快得多
-
2.7.4. 常用于按值或按范围进行筛选的属性
-
2.7.4.1. 引能快速减少执行特定任务的遍历器数量,从而减少数据库要做的工作
-
2.7.4.2. 对于希望在开始时使用最少遍历器的遍历尤其有帮助
-
2.7.5. 需要全文搜索的属性,比如寻找以某个特定字母组合开始、结束或包含它的单词
-
2.7.5.1. 很多数据库需要特别的索引来基于某个属性执行全文搜索,因为它们能保证这些特殊处理被高效索引
-
2.7.6. 在支持地理数据的数据库中需要搜索空间特征
-
2.7.6.1. 空间属性也是需要特别索引的类别
-
2.7.7. 需要在为图增加索引时保持谨慎,仅在需要改善性能时才使用它们
-
2.7.8. 像Neo4j、DataStax Graph和JanusGraph(还有其他很多)这些则具备基于单值、基于复值、基于范围的全范围索引,甚至具备地址空间索引
-
2.7.9. Azure CosmosDB和Amazon Neptune,并没有用户定义索引的概念,倾向于由厂商管理索引细节
3. 处理超级节点
3.1. 超级节点是图数据库中最常见的与数据相关的性能问题
3.2. 该问题特别难处理,因为超级节点不能被清除
3.3. 超级节点就是图中有异常多相邻边的顶点
3.4. 和实例数据有关
-
3.4.1. 超级节点是在实例数据中有特定标签的特定顶点
-
3.4.2. 一个常见的误解是认为超级节点指的是顶点标签,但并非如此
-
3.4.3. 指的是与具有相同标签的其他顶点实例相比,有异常多边的顶点实例
3.5. 和数据库有关
-
3.5.1. 某个数据库的某个遍历中的超级节点在其他数据库或者同一个数据库的不同遍历中则可能运行良好
-
3.5.1.1. 不同厂商的底层数据结构和存储算法是不一样的
3.6. 监控超级节点
-
3.6.1. 监控增长
-
3.6.1.1. 第一个策略是定时监控图中所有顶点的度数(degree)并寻找最高的异常值
-
3.6.1.2. 监控是重要的,因为超级节点很少在一开始时就存在,它们会随时间增长
-
3.6.1.3. 超级节点很少在数据初始加载时出现,而是当图里的数据不断增加时才逐渐产生的
-
3.6.1.4. 现实世界里的很多网络是无尺度网络
> 3.6.1.4.1. 在无尺度网络中,很多顶点的相邻边较少,只有少数顶点有大量的相邻边
- 3.6.1.5. 少量被称为“枢纽”的机场会拥有大量航班
> 3.6.1.5.1. 幂律分布
-
3.6.1.6. 分布中的长尾是超级节点会在无尺度网络中出现的地方
-
3.6.1.7. 需要定时监控数据,以找到具有最高度数的顶点
-
3.6.1.8. 定时运行这个或类似的遍历并跟踪结果,能够主动监控潜在超级节点的增长并在问题出现前将其捕捉
-
3.6.2. 监控异常
-
3.6.2.1. 第二个用于监控超级节点的常用手段是响应式地监控遍历的性能并寻找异常值,通常使用市场上的各种应用程序监控工具来做
-
3.6.2.2. 寻找在某个顶点上明显比其他顶点耗费更长时间的遍历
-
3.6.2.3. 超级节点并不是导致性能问题的唯一因素,但它是导致大多数时候表现良好的遍历在某些顶点上出现性能差异的主要因素之一
-
3.6.2.4. 由于图的规模变大,每种方法都会产生耗时很长的查询,并对图数据库造成显著的额外负担
-
3.6.2.5. 在识别超级节点上,没有灵丹妙药
> 3.6.2.5.1. 知识、正确的数据建模和持续监控都是识别和避免超级节点的最佳工具
3.7. 在整张图(或者图中的一大部分)中进行遍历,这些计算应该被视为分析性的,而不是事务性的
-
3.7.1. 事务性操作通常只需要几秒或几微秒
-
3.7.1.1. 在运行事务型查询时,总是通过指定顶点标签和属性的筛选来开启遍历
-
3.7.2. 分析性操作可能需要数分钟、数小时或更长时间
-
3.7.3. 尽管超级节点在运行事务型查询时并不受待见,但它们在运行分析型算法时尤为重要
3.8. 处理超级节点最常见、最通用的可行方法是重构模型来消除或最小化超级节点的影响
-
3.8.1. 重构的目标是最小化图遍历的边的数量
-
3.8.2. 图数据库是为遍历边的访问模式而优化的
-
3.8.2.1. 图数据库比其他引擎更适合这类操作并不代表我们希望图做多余的工作
3.9. 以顶点为中心的索引和边索引
-
3.9.1. 超级节点是图数据库的常见问题,有些数据库厂商提供了特定的索引类型来帮助解决这类问题
-
3.9.2. 组合会被索引和排序,从而避免对边进行线性扫描,提供更快的图遍历
-
3.9.3. 不是所有的数据库都支持这类索引,而且每个厂商的实现细节都不尽相同
4. 应用程序的反模式
4.1. 对非图用例使用图
-
4.1.1. 图数据库擅长解决很多特定类型的复杂问题,但并不是解决所有问题的灵丹妙药
-
4.1.1.1. 图并不能回答我们提出的所有疑问
-
4.1.2. 要谨记图在帮助我们理解数据和转化业务问题中的好处和局限
-
4.1.3. 在构建图解决方案前,我们需要对信息有足够深入的理解,从而可以建模和遍历图
-
4.1.4. 不要过度依赖图的灵活性也同等重要
-
4.1.4.1. 尽管图确实具备超凡的敏捷性,但这并不代表图数据模型可以解答任何疑问,也不代表它可以高效地做出解答
-
4.1.5. 不要被使用一项新技术带来的兴奋感冲昏头脑,忘记好的软件开发基本原则
4.2. 脏数据
-
4.2.1. 往图里添加脏数据
-
4.2.2. 脏数据指的是包含错误或重复的记录、不完整或过期的信息,甚至缺失字段的数据
-
4.2.3. 脏数据,就像其他反模式一样,并不是图数据库专有的问题,但它会在图数据库中引起一些特有的问题
-
4.2.4. 数据越干净、越少重复,图就越能更准确地表示连接
-
4.2.5. 实体解析(entity resolution)
-
4.2.5.1. 指对我们认为表示相同实体的记录进行去重、连接或重组,形成单一的权威代表
4.3. 缺乏充分的测试
-
4.3.1. 测试数据缺乏代表性
-
4.3.1.1. 由于图的连接本质和遍历这些连接的需要,在图数据库中确保对具有代表性的数据样本进行测试比在关系数据库中重要得多
-
4.3.1.2. 具有代表性的数据样本对于处理分支因子,即递归查询中继承顶点的数量,尤为重要
-
4.3.1.3. 图遍历的性能较少取决于图中数据的数量,而是更取决于图中数据的连接性
-
4.3.2. 测试数据规模不足
-
4.3.2.1. 在规模充足的数据上进行测试意味着使用有足够深度和足够连接的数据,而不仅是数据量大
-
4.3.2.2. 规模化测试对于高度递归的应用程序或使用分布式数据库的应用程序而言是头等大事
> 4.3.2.2.1. 在深度(迭代次数)为5时表现尚可,但可能在生产环境中深度为10的时候则表现糟糕
- 4.3.2.3. 有效地模拟图数据是一件极其复杂的事情
> 4.3.2.3.1. 大部分图领域的无限扩展性代表着独特的挑战
- 4.3.2.4. 根据经验,创建测试数据的最好方式根本就不是创建它们,而是尽可能地使用真实数据,有些时候要结合数据脱敏技术来保护数据中的个人验证信息
5. 遍历反模式
5.1. 不使用参数化的遍历
-
5.1.1. 当不可信的数据被作为命令或查询语句的一部分发送到解析器中时,就会发生注入缺陷
-
5.1.2. 攻击者的有害数据会欺骗解析器来执行非预设的命令,或者在没有合法授权的情况下访问数据
-
5.1.3. 参数化遍历使用符号(token)来代表查询中的输入值
-
5.1.3.1. 符号会被应用程序传递过来的、经过“消毒”和验证的值替代
-
5.1.3.2. 在Java中使用JDBC的话,我们使用PreparedStatement来实现参数化
-
5.1.4. 要免受恶意代码的攻击,就需要对从用户那里传递过来的数据使用参数
-
5.1.5. 大部分数据引擎,不管是图还是其他类型的,会缓存执行计划
-
5.1.5.1. 这能节省生成新执行计划的开销,因为执行计划在首次通过参数调用遍历后就产生了
-
5.1.5.2. 对于频繁使用的遍历来说,缓存执行计划能明显地提升服务器的性能
5.2. 使用没有标签的筛选操作
- 5.2.1. 没有在第一个操作中提供标签进行筛选,所有剩余的操作都要在图中的每一个顶点上进行,严重影响性能