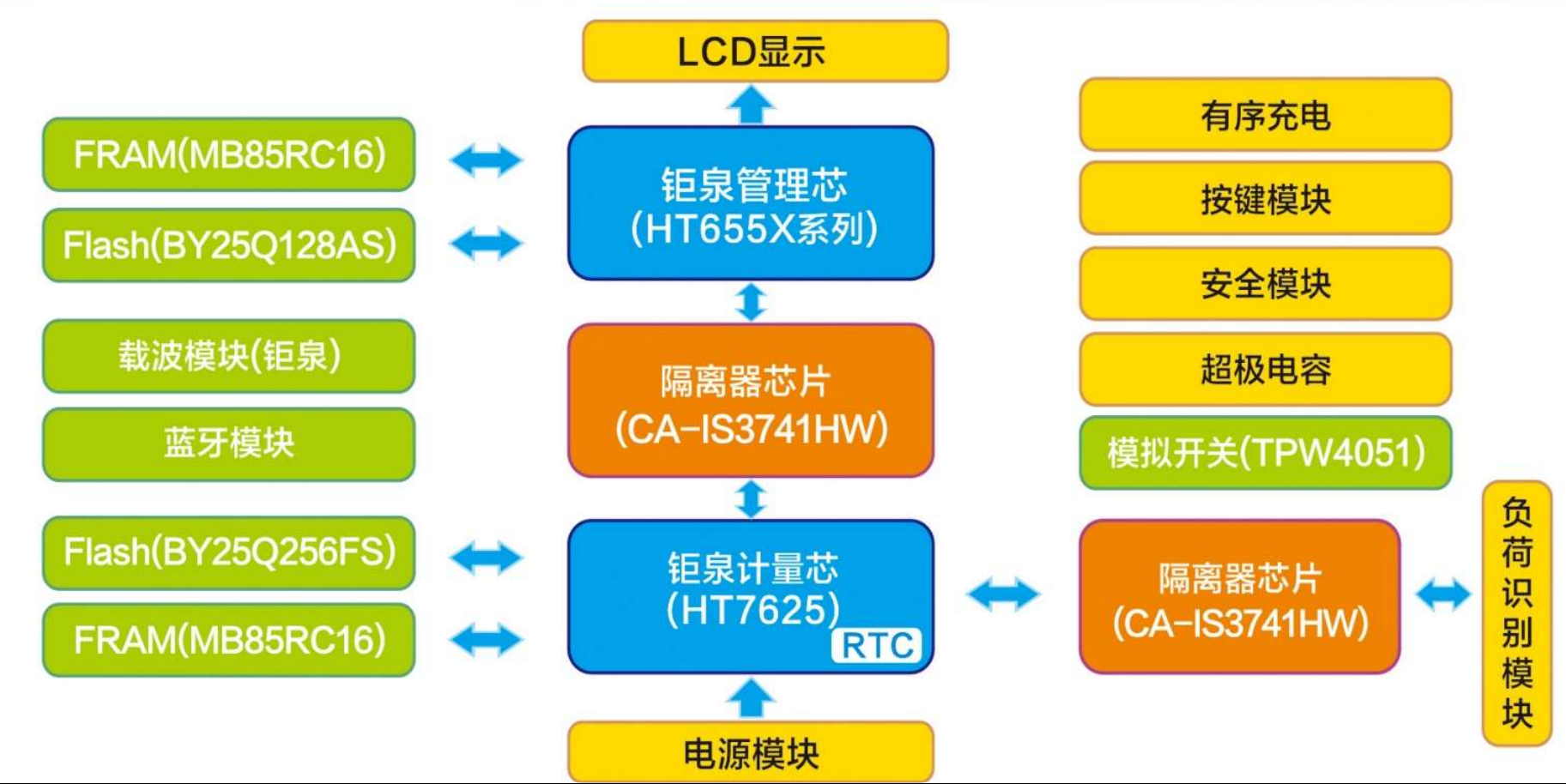
前言:目标检测可能是大家用的比较多的,先完善这一篇吧。yolov5的导出可以参考官方文档。并且博主比较懒,已经做过一遍的事情,不想验证第二遍,如果有步骤错误或者疏漏导致中间遇到了问题,可以先自己debug,流程大致就是这样的。
一、修改源码
首先是拉取yolov8最新的源码,最新的commit即可,任意下载一个型号的模型
git clone https://github.com/ultralytics/ultralytics.git
wget https://github.com/ultralytics/assets/releases/download/v8.2.0/yolov8n.pt
由于mlu220最高支持pytorch1.3版本,因此yolov8的一些库是不支持的,因此需要在源码的基础上对这些进行删减。
并且pytorch1.3不支持加载pytorch1.4~版本之后默认使用torch.save保存的模型。需要加载模型后重新保存。
model = YOLO('yolov8n.yaml').load('yolov8n.pt') torch.save(model.state_dict(), "yolov8n_unzip.pt", _use_new_zipfile_serialization=False)
(1)不支持GELU
1.修改 /torch/venv3/pytorch/lib/python3.6/site-packages/torch/nn/modules/activation.py 文件
1 class GELU(Module): 2 @staticmethod 3 def forward(x): 4 return x * 0.5 * (1 + torch.tanh(torch.sqrt(2 / torch.pi) * (x + 0.044715 * torch.pow(x, 3))))
2.修改 /torch/venv3/pytorch/lib/python3.6/site-packages/torch/nn/modules/init.py 我呢见
from .activation import Threshold, ReLU, ..., GELU __all__ = ['SiLU', 'Hardswish', "GELU", 'Module', ...]
(2)ModuleNotFoundError: No module named ‘importlib.metadata’
ultralytics\utils/__init__.py 中 importlib.metadata 替换为 importlib_metadata
ultralytics\utils/checks.py 中 from importlib import metadata 替换为 import importlib_metadata
ultralytics\utils/checks.py 中 metadata 替换为 importlib_metadata
(3)将 ultralytics/hub 修改为 ultralytics/hub_bak
ultralytics\engine\model.py 注释 from ultralytics.hub.utils import HUB_WEB_ROOT
ultralytics\engine\model.py 注释 HUB_WEB_ROOT相关函数调用
(4)建议直接使用 DetectionModel 类创建模型,分割、分类等同理
from ultralytics.nn.tasks import yaml_model_load, DetectionModel model = DetectionModel(cfg=yaml_model_load("yolov8n.yaml")) ckpt = torch.load("./weights/yolov8n_unzip.pt", map_location="cpu") model.load_state_dict(ckpt["model"].state_dict())
(5)后处理层不支持
修改 ultralytics/ultralytics/nn/modules/head.py 文件
找到 def _inference(self, x): 函数
修改为以下内容
# if self.dynamic or self.shape != shape:# self.anchors, self.strides = (x.transpose(0, 1) for x in make_anchors(x, self.stride, 0.5))# self.shape = shape box = x_cat[:, : self.reg_max * 4]cls = x_cat[:, self.reg_max * 4 :]return self.dfl(box), cls.sigmoid()
(6)寒武纪在量化和导出cambricon模型时,需要将算子层搬运到不同的设备符上
如何理解这段话,例如,量化时,用的是torch.nn.Conv2d算子;导出时,用的是torch_mlu.nn.Conv2d算子。虽然在构建整个模型时,会使用 model.to(devices) 的操作,但是内部的有些算子还是需要手动搬运,因此需要修改文件,增加手动搬运的代码。
修改 ultralytics/ultralytics/nn/modules/block.py 文件
1.在开头位置添加
devices = 'cpu'
2.在 return self.cv3(self.cv2(self.upsample(self.cv1(x)))) 前增加
def forward(self, x):self.upsample = self.upsample.to(devices)"""Performs a forward pass through layers using an upsampled input image."""return self.cv3(self.cv2(self.upsample(self.cv1(x))))
二、导出代码
import torch import argparseimport torch_mlu import torch_mlu.core.mlu_quantize as mlu_quantize import torch_mlu.core.mlu_model as ctfrom ultralytics.nn.tasks import yaml_model_load, DetectionModelimport os import cv2 import numpy as npimg_data = [] def load_data(file, img_size):global img_dataif os.path.isfile(file):_, suffix = os.path.splitext(file)if suffix in [".jpg", ".jepg", ".bmp", ".png"]:img = cv2.imread(file)if img.shape[1] != img_size[1] or img.shape[0] != img_size[0]:img = cv2.resize(img, (img_size[0], img_size[1]))img = img.astype(np.float32)img = img / 255.0img = img.transpose((2, 0, 1))image = img[np.newaxis, :, :, :]image = np.array(image, dtype=np.float32)img_data.append(image)else:for f in os.listdir(file):load_data(os.path.join(file, f), img_size)def model_qua():model = DetectionModel(cfg=yaml_model_load("yolov8s.yaml"))ckpt = torch.load("./weights/yolov8s_unzip.pt", map_location="cpu")model.load_state_dict(ckpt["model"].state_dict())qconfig = {'data_scale': 1.0,'perchannel': False,'use_avg': False}quantized_model = mlu_quantize.quantize_dynamic_mlu(model, qconfig, dtype='int16', gen_quant=True)for img in img_data:img = torch.from_numpy(img).to("cpu")pred_1 = quantized_model(img)torch.save(quantized_model.state_dict(), r'./weights/yolov8s_unzip_int16.pt')print('run qua')def convert_mlu():if opt.fake_device:ct.set_device(-1)ct.set_core_number(0)ct.set_core_version('MLU220')model = DetectionModel(cfg=yaml_model_load("yolov8s.yaml"))# print(model) quantized_net = torch_mlu.core.mlu_quantize.quantize_dynamic_mlu(model)state_dict = torch.load(r'./weights/yolov8s_unzip_int16.pt')quantized_net.load_state_dict(state_dict, strict=False)quantized_net.eval()quantized_net.to(ct.mlu_device())if opt.jit:print("### jit")ct.save_as_cambricon('resnet18_torch1.3')torch.set_grad_enabled(False)ct.set_core_number(4)trace_input = torch.randn((1, 3, 640, 640), dtype=torch.float)input_mlu_data = trace_input.type(torch.HalfTensor).to(ct.mlu_device())quantized_net = torch.jit.trace(quantized_net, input_mlu_data, check_trace = False)with torch.no_grad():for img in img_data:img = torch.from_numpy(img).type(torch.HalfTensor).to(ct.mlu_device())pred = quantized_net(img)print('run mlu')returnif __name__ == '__main__':parser = argparse.ArgumentParser()parser.add_argument('--weights', nargs='+', type=str, default='yolov5s.pt', help='model.pt path(s)')parser.add_argument('--source', type=str, default='../data/2', help='source') # file/folder, 0 for webcamparser.add_argument('--img-size', type=int, default=320, help='inference size (pixels)')parser.add_argument('--device', default='', help='cuda device, i.e. 0 or 0,1,2,3 or cpu')parser.add_argument('--cfg', default='cpu', help='qua and off')parser.add_argument('--fake_device', type=bool, default=True)parser.add_argument('--jit', type=bool, default=True)opt = parser.parse_args()load_data(opt.source, img_size=[640, 640])print("img_data=", len(img_data))# compare_output() with torch.no_grad():if opt.cfg == "cpu":convert_torch_v_1_3(opt.weights)elif opt.cfg == "qua":model_qua()elif opt.cfg == "mlu":convert_mlu()
需要注意的地方,量化时 devices = ‘cpu’,导出时 devices = ‘mlu’
python export.py --cfg qua
python export.py --cfg mlu
三、后处理
需要注意的地方,导出的这个yolov8是没有后处理模块的,如下图所示:
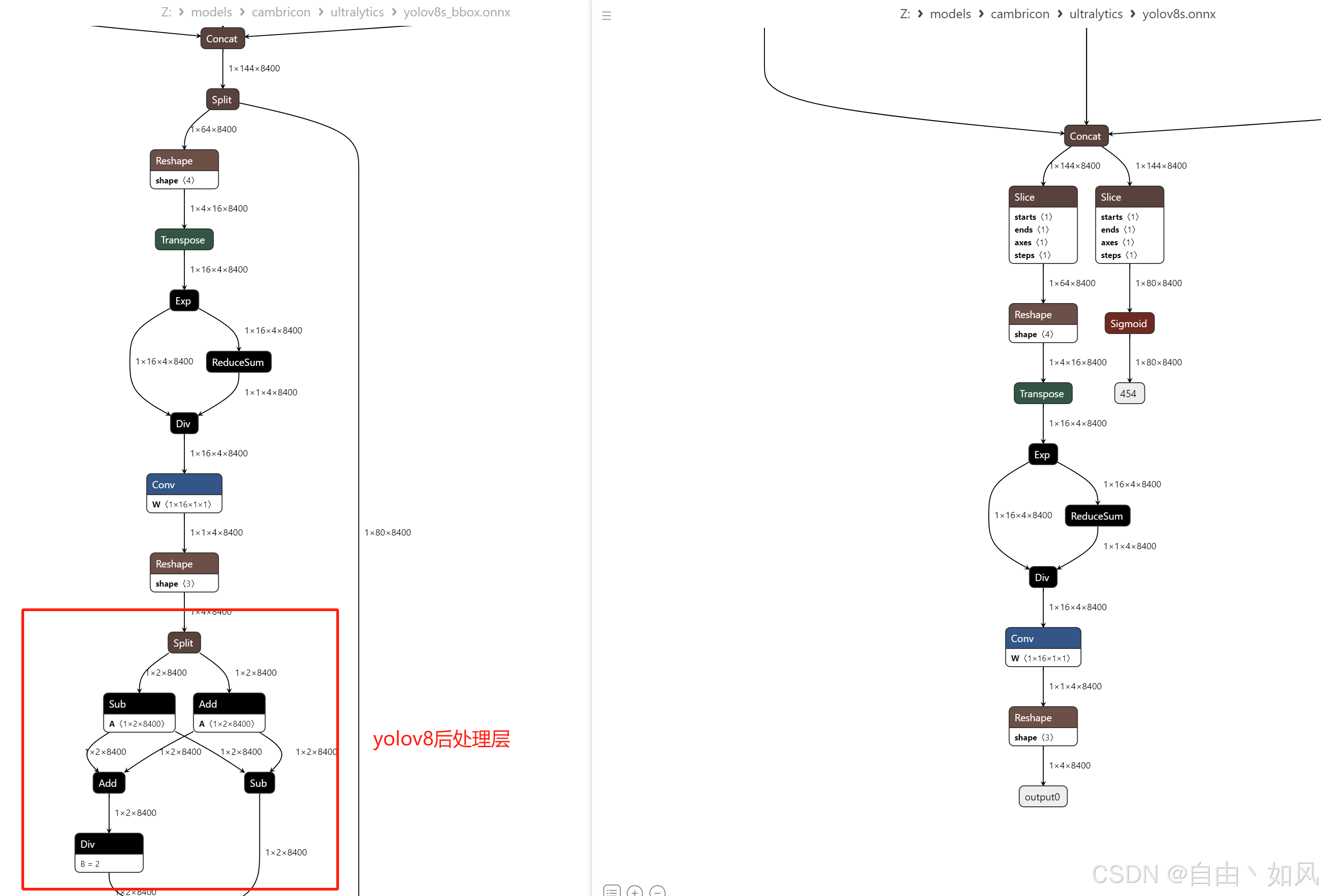
当然,这个问题也很多解决,无非就是一些sub、add、div的操作,使用cpu实现就好了,以下是整个yolov8后处理c++实现代码:
#ifndef _YOLOV8_H #define _YOLOV8_H#include "XRModelAPI.h" #include "algorithm_struct_base.h"class YoLoV8 : public ModelAPI { public:YoLoV8(MODEL_INFO_S& info);virtual ~YoLoV8() {}ZR_ErrorCode PostProcess(std::vector<ObjectResult>& results);public:void getWidth() {this->model_width = modelWidth_;}void getHeight() {this->model_height = modelHeight_;}uint32_t model_width;uint32_t model_height;protected:ZR_ErrorCode get_anchor_centers(uint8_t stride);void get_bbox_key(uint8_t stride, float* detection, float* confi, std::vector<ObjectResult>& results);private:std::map<uint8_t, std::vector<POINT_2D_S>> centers_points;uint8_t num_class = 80;uint8_t stride[3] = {8, 16, 32};// uint8_t stride[3] = {32, 16, 8};float scoreThreshold = 0.10f;float nmsThreshold = 0.35f;uint8_t downsample = 3; };#endif // _YOLOV8_H
#include "yolov8.h"YoLoV8::YoLoV8(MODEL_INFO_S& info) : ModelAPI(info) {for (int i = 0; i < this->downsample; ++i) {this->get_anchor_centers(stride[i]);} }namespace {static char* class_lables[80] = {(char*)"person", (char*)"bicycle", (char*)"car", (char*)"motorcycle",(char*)"airplane", (char*)"bus", (char*)"train", (char*)"truck", (char*)"boat", (char*)"traffic light",(char*)"fire hydrant", (char*)"stop sign", (char*)"parking meter", (char*)"bench", (char*)"bird",(char*)"cat", (char*)"dog", (char*)"horse", (char*)"sheep", (char*)"cow", (char*)"elephant",(char*)"bear", (char*)"zebra", (char*)"giraffe", (char*)"backpack", (char*)"umbrella", (char*)"handbag",(char*)"tie", (char*)"suitcase", (char*)"frisbee", (char*)"skis", (char*)"snowboard",(char*)"sports ball", (char*)"kite", (char*)"baseball bat", (char*)"baseball glove",(char*)"skateboard", (char*)"surfboard", (char*)"tennis racket", (char*)"bottle", (char*)"wine glass",(char*)"cup", (char*)"fork", (char*)"knife", (char*)"spoon", (char*)"bowl", (char*)"banana",(char*)"apple", (char*)"sandwich", (char*)"orange", (char*)"broccoli", (char*)"carrot",(char*)"hot dog", (char*)"pizza", (char*)"donut", (char*)"cake", (char*)"chair", (char*)"couch",(char*)"potted plant", (char*)"bed", (char*)"dining table", (char*)"toilet", (char*)"tv/monitor",(char*)"laptop", (char*)"mouse", (char*)"remote", (char*)"keyboard", (char*)"cell phone",(char*)"microwave", (char*)"oven", (char*)"toaster", (char*)"sink", (char*)"refrigerator",(char*)"book", (char*)"clock", (char*)"vase", (char*)"scissors", (char*)"teddy bear",(char*)"hair drier", (char*)"toothbrush"}; };ZR_ErrorCode YoLoV8::get_anchor_centers(uint8_t stride) {int net_grid_w = modelWidth_ / stride;int net_grid_h = modelHeight_ / stride;for (int i = 0; i < net_grid_h; ++i) {for (int j = 0; j < net_grid_w; ++j) {POINT_2D_S yolox_center;yolox_center.cx = j + 0.5;yolox_center.cy = i + 0.5;centers_points[stride].push_back(yolox_center);}}return ZR_AI_OK; }ZR_ErrorCode YoLoV8::PostProcess(std::vector<ObjectResult>& results) {uint32_t dataSize = 0; #if defined(BUILD_WITH_CAMBIRCON)float* detection = (float* )model->GetInferenceOutputItem(0, dataSize);spdlog::debug("dataSize={} ", dataSize);float* confi = (float* )model->GetInferenceOutputItem(1, dataSize);spdlog::debug("dataSize={} ", dataSize); #elsefloat* detection = (float* )model->GetInferenceOutputItem(1, dataSize);spdlog::debug("dataSize={} ", dataSize);float* confi = (float* )model->GetInferenceOutputItem(0, dataSize);spdlog::debug("dataSize={} ", dataSize); #endifint net_grid_w = 0, net_grid_h = 0;std::vector<ObjectResult> object;for (int i = 0; i < this->downsample; ++i) {if (detection != nullptr && confi != nullptr) {detection += net_grid_w * net_grid_h * 4;confi += net_grid_w * net_grid_h * num_class;this->get_bbox_key(stride[i], detection, confi, object);net_grid_w = modelWidth_ / stride[i];net_grid_h = modelHeight_ / stride[i];} else {}}if (object.size() != 0) {Utils::nms(object, results, nmsThreshold);object.clear();} }void YoLoV8::get_bbox_key(uint8_t stride, float* detection, float* confi, std::vector<ObjectResult>& results) {int net_grid_w = modelWidth_ / stride;int net_grid_h = modelHeight_ / stride;std::vector<POINT_2D_S> all_points = centers_points[stride];for (int i = 0; i < net_grid_w * net_grid_h; ++i) {const float* temp_d = detection + i * 4;const float* temp_c = confi + i * num_class;uint8_t topClass = 0;for (uint8_t j = 0; j < num_class; ++j) {if (temp_c[j] > temp_c[topClass]) {topClass = j;}}if (temp_c[topClass] < scoreThreshold) continue;// 与原始网络解耦层对应float sub_x = all_points[i].cx - temp_d[0];float sub_y = all_points[i].cy - temp_d[1];float add_w = temp_d[2] + all_points[i].cx;float add_h = temp_d[3] + all_points[i].cy;float x_center = ((sub_x + add_w) * 0.5f) * stride;float y_center = ((sub_y + add_h) * 0.5f) * stride;float w = (add_w - sub_x) * stride;float h = (add_h - sub_y) * stride;if (w < 5.f || h < 5.f) continue;ObjectResult obj;obj.confidence = temp_c[topClass];obj.name = class_lables[topClass];obj.class_index = topClass;obj.bbox.x_min = std::max((x_center - w * 0.5f), 0.f);obj.bbox.y_min = std::max((y_center - h * 0.5f), 0.f);obj.bbox.x_max = std::min((x_center + w * 0.5f), float(modelWidth_));obj.bbox.y_max = std::min((y_center + h * 0.5f), float(modelHeight_));results.push_back(obj);} }
------------------------------------------------------------------------------------------------
原文来自:https://blog.csdn.net/qq_41384531/article/details/140372504