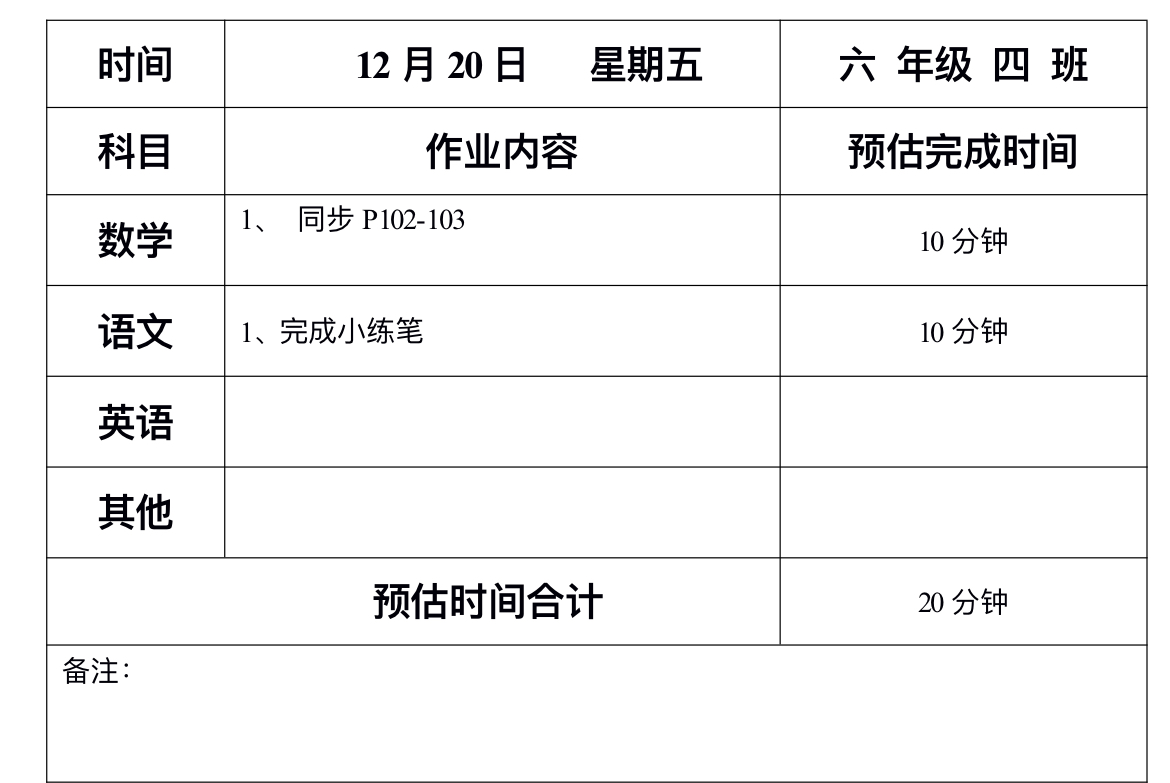
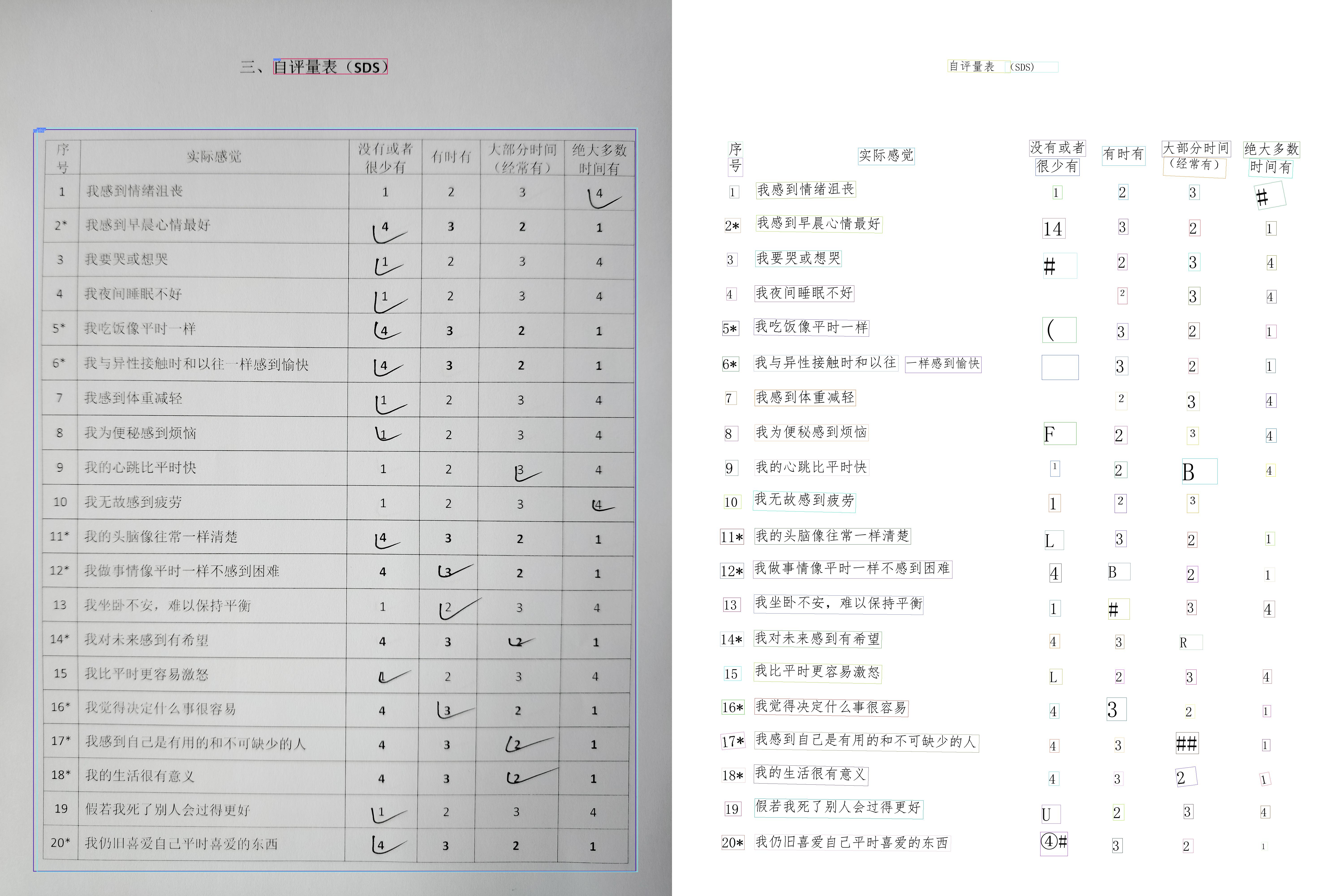
有个项目需求,对拍摄的问卷图片,进行自动得分统计【得分是在相应的分数下面打对号】,输出到excel文件
原始问卷文件见下图,真实的图片因使用手机拍摄的图片,存在一定的畸变,
技术调研
传统方法
传统方法,通过线检测 先对 表格进行矫正【仿射变换】,然后二次线检测 划分出不同表格cell,然后根据位置关系 拿到得分区的cell,利用统计手段或其他手段判断是否存在对号,同时得分区存在逆序关系,即有的问题是从 1-4,有的则是4-1,这样就需要对第一个数字区cell 即起始数字进行判断 是 1 or 4
深度学习方法OCR
了解到的方法就是paddle的OCR,从PaddleOCR github出发
其中 PaddleOCR生态涉及
- 文本检测、印章文本检测
- 文本识别、公式识别
- 表格结构识别
- 版式分析(版面区域检测)
- 文档图像方向分类
- 关键信息抽取
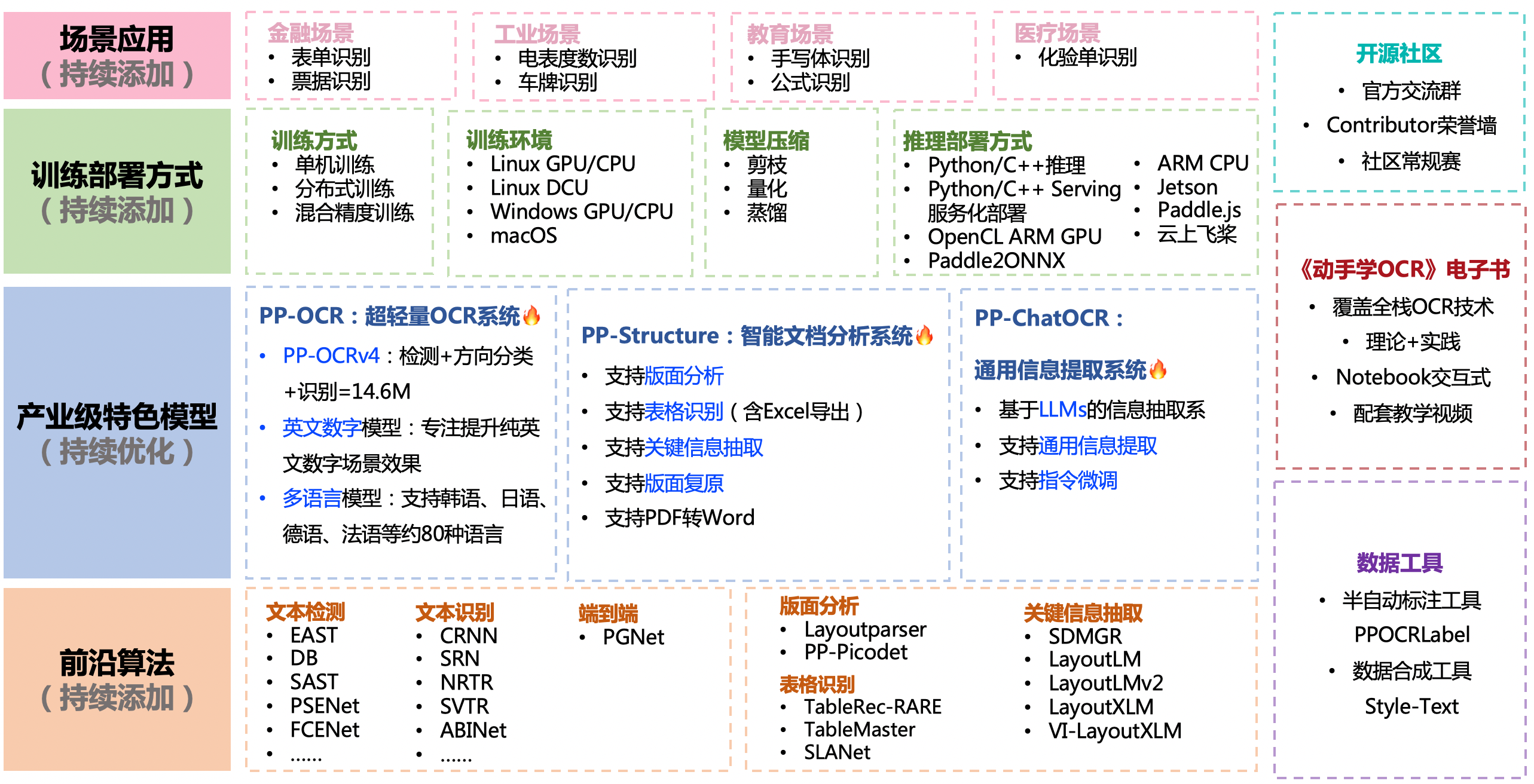
提供的模型包括
-
PP-OCR 中文模型
-
PP-OCR 英文数字模型
-
PP-OCRv3 多语言模型
-
PP-Structure 文档分析
-
版面分析+表格识别
-
SER 语义实体识别
-
RE 关系提取
-
新增文档结构分析PP-Structure工具包,支持版面分析与表格识别(含Excel导出)
PP-OCR https://paddlepaddle.github.io/PaddleOCR/latest/ppocr/overview.html 模型简介
PP-Structure https://paddlepaddle.github.io/PaddleOCR/latest/ppstructure/overview.html 简介
PaddleOCR/ppstructure/README_ch.md 代码库里的简介
吐槽,PaddleOCR 文档 有,但太乱了
当前使用的默认模型如下,第一次运行会自动下载
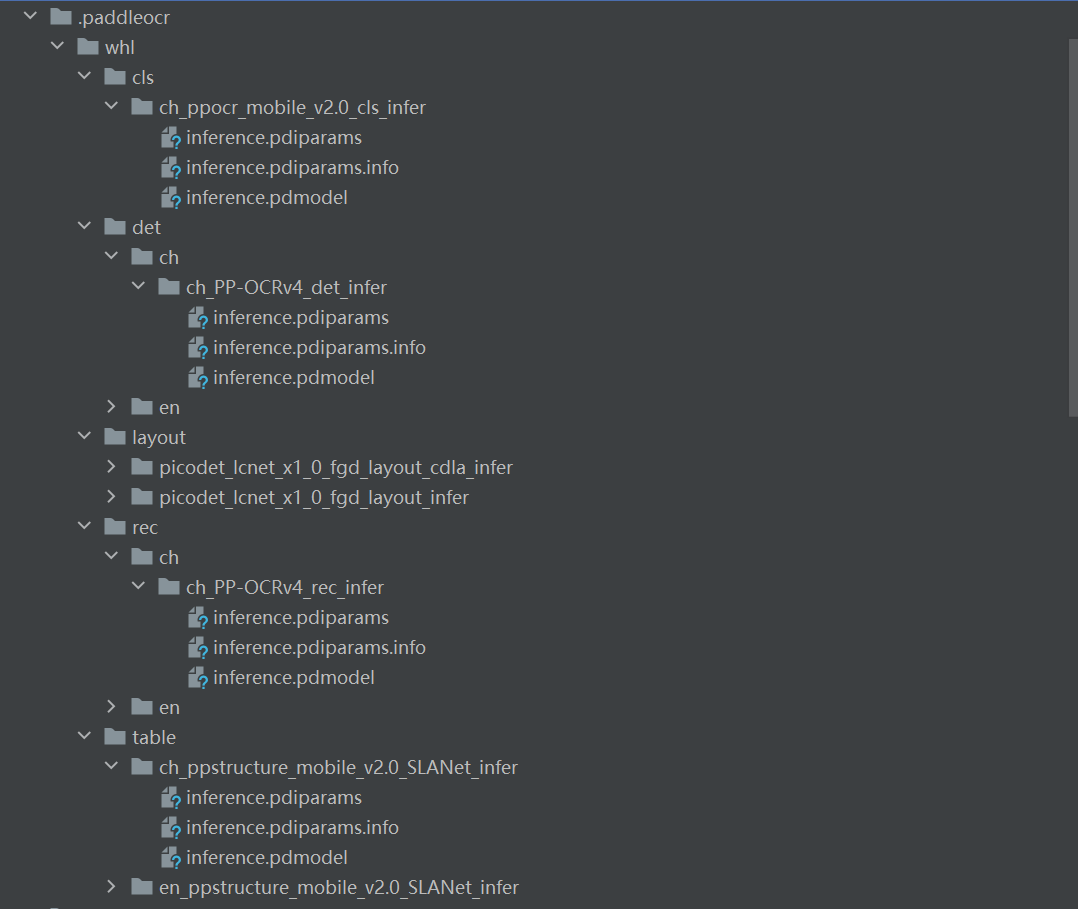
其中涉及的模型
分类cls,使用 ppocr_mobilet_v2
检测det,识别rec,使用PP-OCRV4
版式layout,使用 lcnet
表格结构table,使用 SLANet
针对项目需求,匹配的功能就是 通用表格分析(PaddleOCR 进行的一个整合),包括四个模块
-
表格结构识别模块 --> 表格结构划分 pp-structure
-
版面区域检测模块 --> 定位表格
-
文本检测模块 ---> 检测文本
-
文本识别模块 ---> 文本识别
整个流程,版面区域检测(定位出表格区域)---> 表格结构识别()--->文本检测(定位文字bbox)--->文本识别(识别出文字)
PaddleOCR实践
在线测试 paddle 的通用表格识别结果 可以基本满足需求
https://aistudio.baidu.com/community/app/91661/webUI
- 通用表格识别产线 - PaddleX 文档
其中针对打勾情况 (会无法检出 或者 误检);未打勾 可以正常检出 【可以进行反推】,效果如下
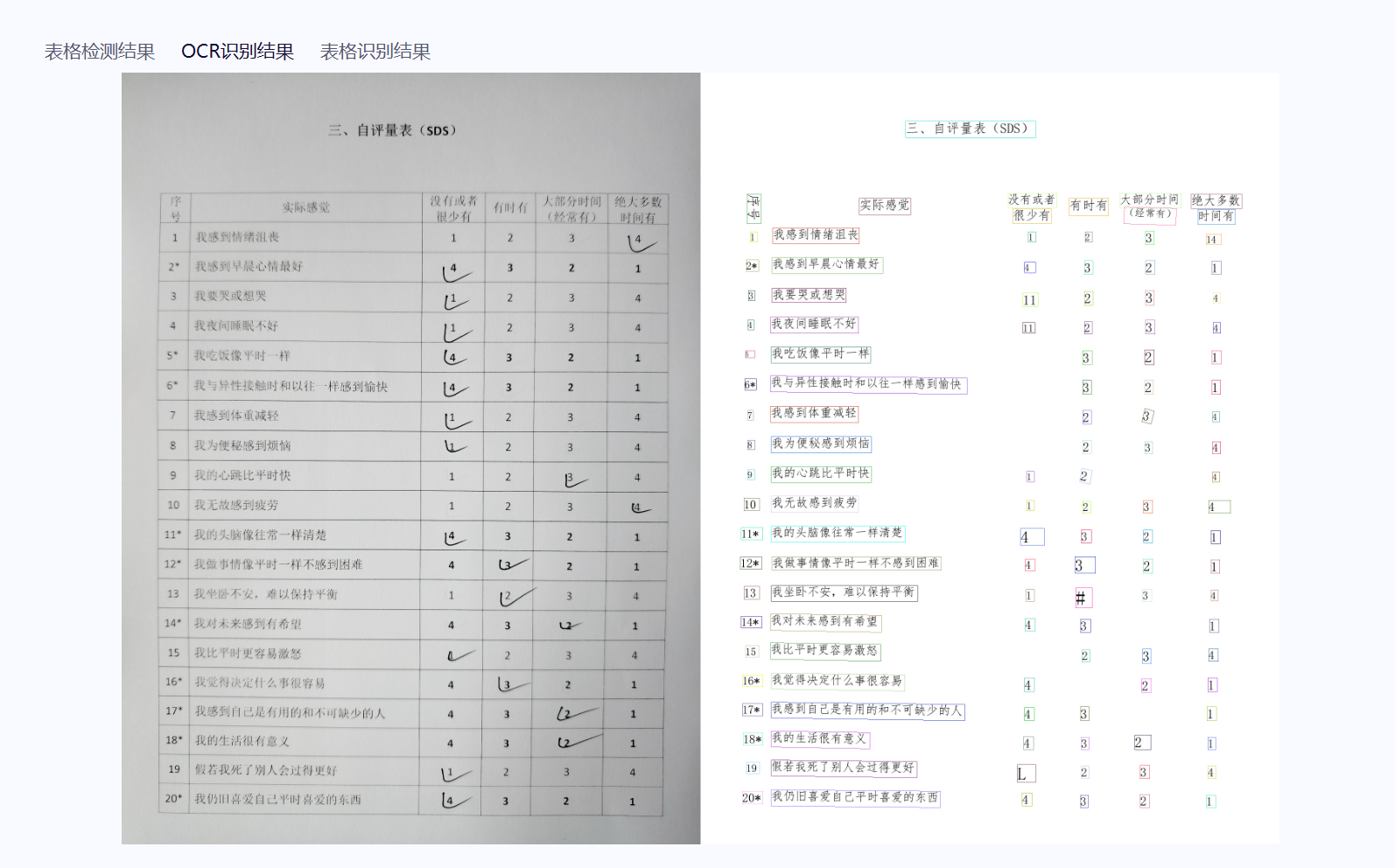
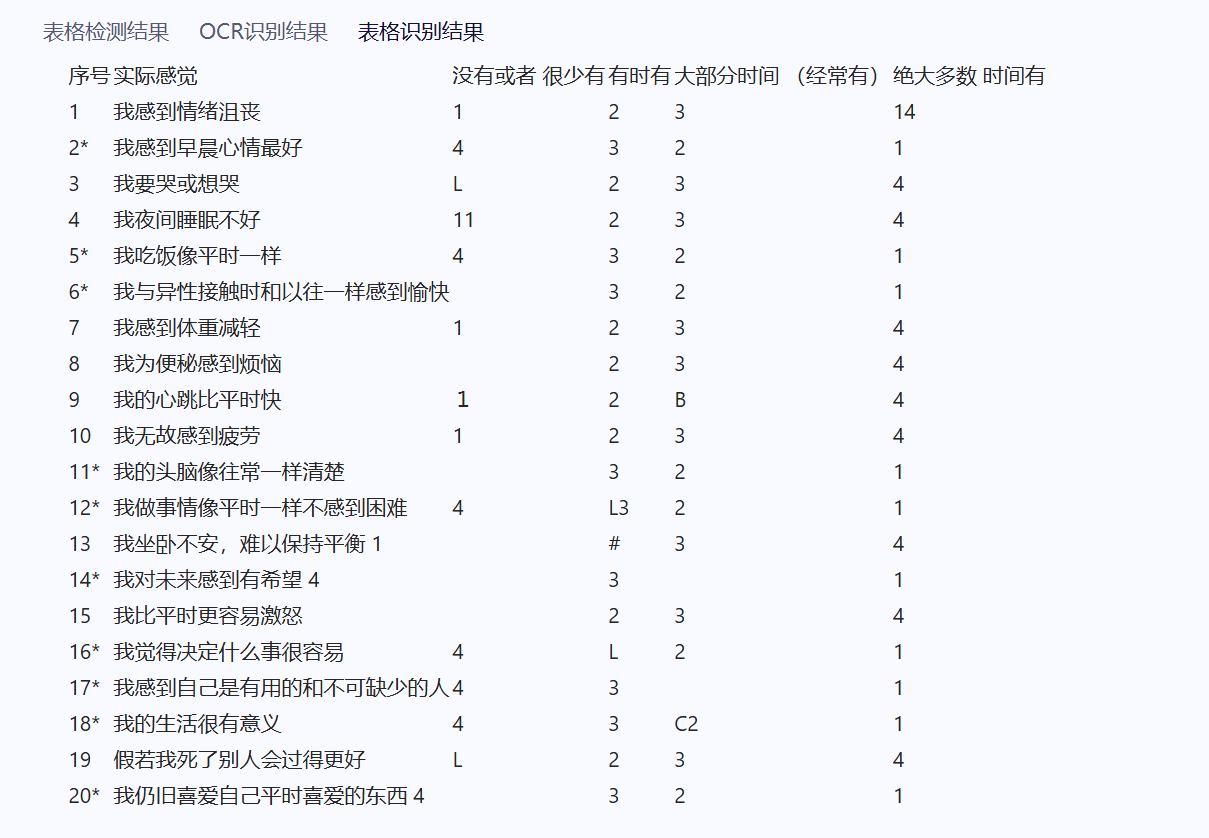
这里在线测试感觉还行【应该是还存在其他的后处理逻辑】,当我自行部署到本地测试推理,感觉有点差距
本地部署测试效果
其中测试 GitHub - xhw205/PaddleOCR_AlignText: PaddleOCR 输出结果的行对齐,表格制式图像OCR行对齐 在2.7.0 paddleOCR 会提示 第33行(y_i_points = [res[i][0][0][1], res[i][0][1][1], res[i][0][3][1], res[i][0][2][1]])表示数组越界
准备进行微调,适应当前数据
paddle 微调
根据文档建议,通用表格分析包括了 四个模块
表格结构识别模块 --> 表格结构
版面区域检测模块 --> 表格区域定位
文本检测模块 ---> 文本未检测出来
文本识别模块 ---> 文本识别错误
哪个检测效果不好,就去微调哪个模型;针对我的项目需求,感觉是 表格结构识别模块,无法对版式进行很好解析,因此对表格结构识别模型进行微调
-
PaddleOCR/applications/中文表格识别.md 这个文件给出了整个训练的流程
-
https://paddlepaddle.github.io/PaddleX/latest/module_usage/tutorials/ocr_modules/table_structure_recognition.html 给出了 表格结构识别模块使用教程,其中的二次开发部分,给出了微调的教程【使用了一个所谓的低代码PaddleX ,进行训练,进行了再一次封装,不是很推荐】
再次吐槽,PaddleOCR 相关文档,太乱了
总结:微调整体流程,准备图片数据---> PPOCRLabel 标注---> 使用PPOCRLabel 提供的脚本进行数据集制作划分--->预训练模型下载--->模型的配置文件修改---> 执行微调训练命令
数据标注
使用PPOCRLabel
pytho ppocrlabel.py --lang zh 启动
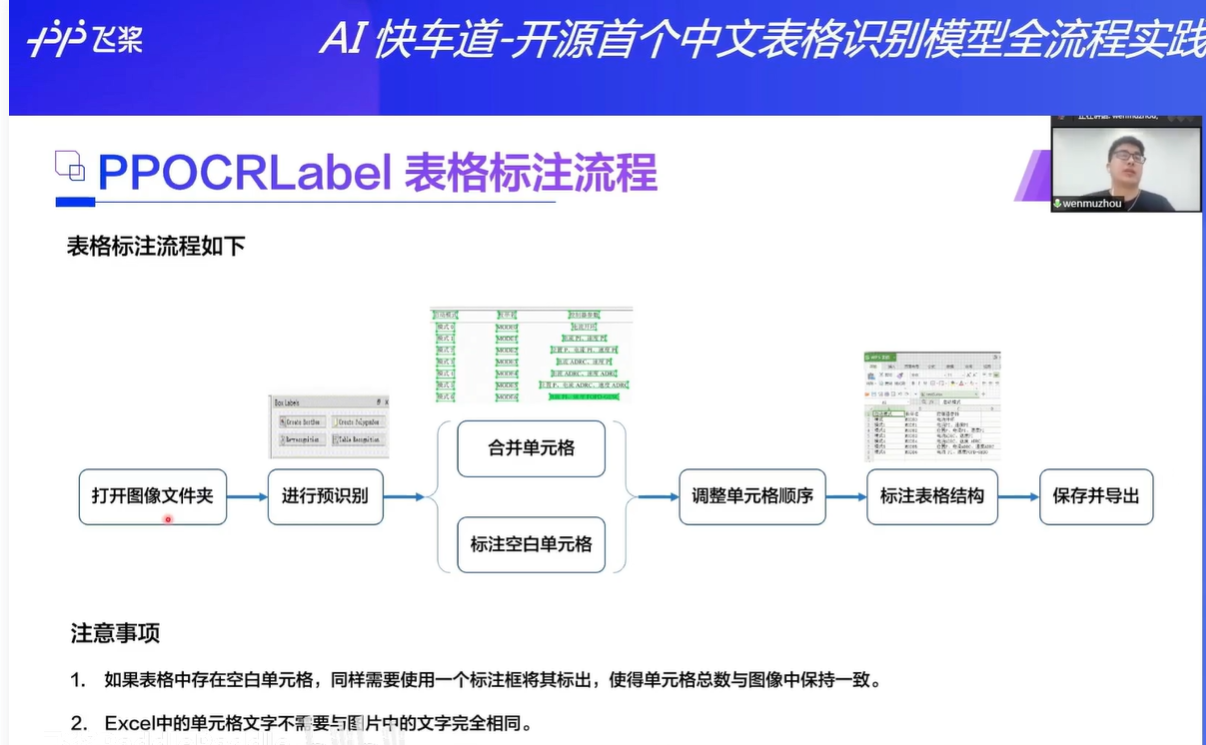
官方文档,表格识别任务标注
https://gitcode.com/gh_mirrors/pa/PaddleOCR/blob/release/2.7/doc/doc_ch/table_recognition.md
标注视频 过于简单【遇到的问题无法解决】
https://www.bilibili.com/video/BV1wR4y1v7JE/?share_source=copy_web&vd_source=cf1f9d24648d49636e3d109c9f9a377d&t=1998
如有问题,需要帮助,欢迎留言、私信或加群 交流【群号:392784757】
数据标注问题(针对表格结构训练标注)
利用PPOCRLabel标注工具大批量自动标注自己的数据集-CSDN博客
【PaddleOCR-PPOCRLabel】标注工具使用-CSDN博客
提到
表格标注针对表格的结构化提取,将图片中的表格转换为Excel格式,因此标注时需要配合外部软件,打开Excel同时完成。在PPOCRLabel软件中完成表格中的文字信息标注(文字与位置)、在Excel文件中完成表格结构信息标注,推荐的步骤为:
-
表格识别:打开表格图片后,点击软件右上角
表格识别按钮,软件调用PP-Structure中的表格识别模型,自动为表格打标签,同时弹出Excel -
更改标注结果:以表格中的单元格为单位增加标注框(即一个单元格内的文字都标记为一个框)。标注框上鼠标右键后点击
单元格重识别
可利用模型自动识别单元格内的文字。注意:如果表格中存在空白单元格,同样需要使用一个标注框将其标出,使得单元格总数与图像中保持一致。
-
调整单元格顺序:点击软件
视图-显示框编号打开标注框序号,在软件界面右侧拖动识别结果一栏下的所有结果,使得标注框编号按照从左到右,从上到下的顺序排列,按行依次标注。 -
标注表格结构:在外部Excel软件中,将存在文字的单元格标记为任意标识符(如
1),保证Excel中的单元格合并情况与原图相同即可(即不需要Excel中的单元格文字与图片中的文字完全相同) -
导出JSON格式:关闭所有表格图像对应的Excel,点击
文件-导出表格JSON标注获得JSON标注结果。
总结:好像正确的流程,先自动表格识别,打开excel 调整结构与图片表格一致 有文字 标注任意标识符都可,然后 导出 gt.txt
https://github.com/PaddlePaddle/PaddleOCR/issues/6242 表格标注存在的疑问
- 能否一次性标注所有表格?现有的模式是只能一张张标注么?
- 如何进行表格结构的调整?readme中给出的使用方法是“将表格图像中有文字的单元格,在Excel中标记为任意标识符(如1)”。请问能稍微详细介绍么?不是很明白这个操作。
- 在pplabel中对表格单元格内的文字进行位置标注和单元格内容重新识别的结果会直接修改已经生成的excel么?因为我在ubuntu系统下使用的wps,所以需要自己手动打开生成的exel文档,但是发现并没有随标注结果改变
- 单元格内容重新识别的功能对跨两行以上的文本识别效果比较差
官方回复
问题2:表格结构调整成和图片中表格一样的就行,比如有单元格合并,Excel对应调整,对于单元格里的内容随便写,不关心;
问题3:重新识别不会改变Excel;
单元格内的信息,只和 html 中的一个 td 标签内容对应
cells 里面的 tokens 信息不参与表格结构模型 训练,只有坐标信息有用
空单元格也是需要标注的
总结:这里是手动调整excel,在标注时 添加矩形框没有用,我在代码debug时也发现,就是基于生成的excel表生成的对应 html,也就是说 我们可以手动做一个对应的图片表格,去生成 html excel->gt.txt->show html
GitHub - WenmuZhou/TableGeneration: 通过浏览器渲染生成表格图像 提供了一个可视化的脚本,可用来可视化 输出的gt.txt,查看标注情况,如果渲染的 html 表格结构 和 图片的表格结构不一致,就要重新处理 excel.xlsx 【gt.txt 是由excel.xlsx 导出的,处理完后 重新导出gt.txt】
预训练模型下载
下载的是SLANet模型权重
模型列表 https://paddlepaddle.github.io/PaddleOCR/latest/ppstructure/models_list.html#22
根据自己的微调任务来下载预训练模型
模型配置文件修改
本文是做表格结构模型微调,所以使用表格配置文件,PaddleOCR-2.7.0/configs/table/SLANet_ch.yml
根据任务类型,选择配置文件
备份一份,进行修改 PaddleOCR-2.7.0/configs/table/SLANet_ch_for_finetune.yml
PaddleOCR-2.7.0/applications/中文表格识别.md ,可以根据这个修改配置
涉及到的有
Global:use_gpu:Trueepoch_num: # 训练轮次eval_batch_step: [0,10] # evaluation is run every 331 iterations after the 0th iterationpretrained_model: # 预训练模型路径
Train:dataset:data_dir:label_file_list:loader:batch_size_per_card:num_workers:
Eval:dataset:data_dir:label_file_list:loader:batch_size_per_card:num_workers:
根据需要进行修改
模型训练
执行命令,加载对应配置 -c
python3 tools/train.py -c configs/table/SLANet_ch_for_finetune.yml
模型转换与推理
模型转换+推理
https://blog.csdn.net/qq_41273999/article/details/135692215
验证精度--->训练引擎 推理单张图片 ---> 模型导出inference模型 ---> 预测引擎 推理
注意路径
# 验证精度
python3 tools/eval.py -c /home/aistudio/SLANet_ch.yml -o Global.checkpoints=/home/aistudio/PaddleOCR/output/SLANet_ch/best_accuracy.pdparams# 训练引擎 推理单张图片
python3 tools/infer_table.py -c /home/aistudio/SLANet_ch.yml -o Global.checkpoints=/home/aistudio/PaddleOCR/output/SLANet_ch/best_accuracy.pdparams Global.infer_img=/home/aistudio/data/data165849/table_gen_dataset/img/no_border_18298_G7XZH93DDCMATGJQ8RW2.jpg# 模型导出inference模型
python3 tools/export_model.py -c /home/aistudio/SLANet_ch.yml -o Global.checkpoints=/home/aistudio/PaddleOCR/output/SLANet_ch/best_accuracy.pdparams Global.save_inference_dir=/home/aistudio/SLANet_ch/infer# 预测引擎推理python3 table/predict_structure.py \--table_model_dir=/home/aistudio/SLANet_ch/infer \--table_char_dict_path=../ppocr/utils/dict/table_structure_dict.txt \-- image_dir=/home/aistudio/data/data165849/table_gen_dataset/img/no_border_18298_G7XZH93DDCMATGJQ8RW2.jpg \--output=../output/inference
其他更详细命令可参考 PaddleOCR-2.7.0/applications/中文表格识别.md
如有问题,需要帮助,欢迎留言、私信或加群 交流【群号:392784757】
微调效果
数据量太少,微调效果基本没有变化
再次吐槽,PaddleOCR文档有,但太乱了;问题回复有,但不理解
相关报错
paddlepaddle-gpu
https://www.paddlepaddle.org.cn/documentation/docs/zh/2.4/install/pip/windows-pip.html
通过修改 下载链接 来更换模型
https://blog.csdn.net/zhanglei5415/article/details/126603380
IndexError: list index out of range
这个越界错误,很多人都遇到,引发的原因也不一致
- if 'bbox' in cells[bbox_idx] and len(cells[bbox_idx]['tokens']) > 0: IndexError: list index out of range
官方给出说法,excel里的单元格数量和你在PPOCRLable里绘制的矩形框的数量不匹配。
- https://blog.csdn.net/haoDe9242/article/details/132078422
也遇到,排查说是 多了个 td
- 官方issue中 (回答 感觉并不太能解决疑问)
https://github.com/PaddlePaddle/PaddleOCR/issues/11572 也遇到
--> https://github.com/PaddlePaddle/PaddleOCR/discussions/12708
https://github.com/PaddlePaddle/PaddleOCR/issues/10243 ---> box_type 设置不对
https://github.com/PaddlePaddle/PaddleOCR/issues/7857
- 解决paddle_ocr训练过程中IndexError: list index out of range的问题_paddleocr list index out of range-CSDN博客
https://blog.csdn.net/weixin_51302403/article/details/134818251)
- PaddleOCR list index out of range 问题_paddleocr识别训练训练数据提示list index out of range-CSDN博客
https://blog.csdn.net/bailanren/article/details/141815706
ZeroDivisionError: float division by zero
metric['fps'] = total_frame / total_time
ZeroDivisionError: float division by zero
https://bbs.csdn.net/topics/612067297
best metric acc:0
模型评估未开始导致
https://github.com/PaddlePaddle/PaddleOCR/issues/2299
AttributeError: ‘ParallelEnv‘ object has no attribute ‘_device_id‘
解决paddleocr报错之AttributeError: ‘ParallelEnv‘ object has no attribute ‘_device_id‘
https://blog.csdn.net/very_big_house/article/details/135402790
感谢
-
ocr 专栏 OCR数字仪表识别_吨吨不打野的博客-CSDN博客
-
GitHub - WenmuZhou/TableGeneration: 通过浏览器渲染生成表格图像
-
GitHub - xhw205/PaddleOCR_AlignText: PaddleOCR 输出结果的行对齐,表格制式图像OCR行对齐
-
GitHub - RapidAI/TableStructureRec: 整理目前开源的最优表格识别模型,完善前后处理,模型转换为ONNX
-
TableDetAndRec - a Hugging Face Space
-
表格检测与识别入门 - My Github Blog