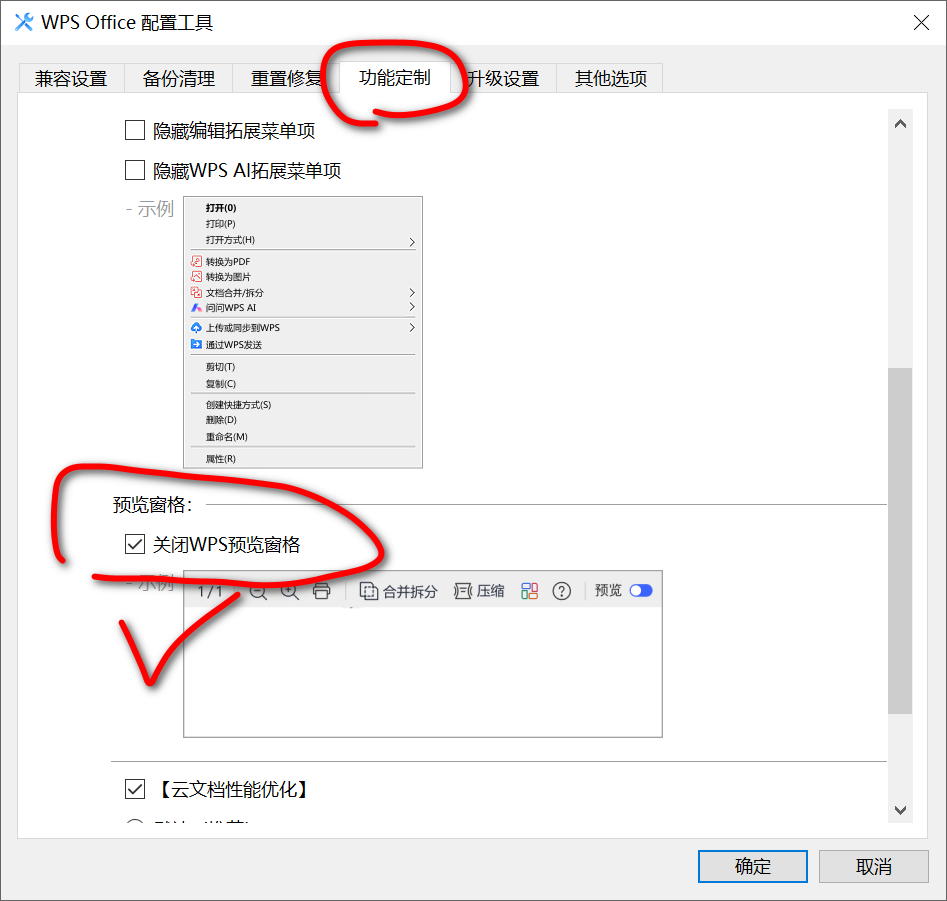
作业信息
| 这个作业属于哪个课程 | <班级的链接>2024-2025-1-计算机基础与程序设计) |
|---|---|
| 这个作业要求在哪里 | <作业要求的链接>https://www.cnblogs.com/rocedu/p/9577842.html#WEEK13 |
| 这个作业的目标 | <写上具体方面>第12章并完成云班课测试 |
| 作业正文 | ... 本博客链接 https://www.cnblogs.com/tanzitian11/p/18620833 |
教材学习内容总结
c语言第十二章学习
结构体是一种用户自定义的数据类型,它允许将不同类型的数据组合在一起。例如,如果你要表示一个学生的信息,学生有姓名(字符数组)、年龄(整数)、成绩(浮点数)等不同类型的数据,就可以使用结构体来定义。
基本语法:
struct结构体名{类型成员1;类型成员2;...;类型成员n; };
例如,定义一个学生结构体:
struct Student {char name[20];int age;float score;
};
这里定义了一个名为Student的结构体,它包含三个成员:name(字符数组用于存储姓名)、age(整数用于存储年龄)和score(浮点数用于存储成绩)。
结构体变量的声明和初始化
声明:
在定义了结构体类型后,可以声明该结构体类型的变量。有两种方式:
方式一:先定义结构体类型,再声明变量。
struct Student stu1;
方式二:在定义结构体类型的同时声明变量。
struct Student {char name[20];int age;float score;
} stu2;
初始化:
可以在声明结构体变量时进行初始化。例如:
struct Student stu3 = {"Tom", 18, 90.5};
这里初始化了一个Student结构体变量stu3,将name成员初始化为"Tom",age成员初始化为18,score成员初始化为90.5。
结构体成员的访问
使用点(.)运算符来访问结构体变量的成员。例如:
struct Student stu;
strcpy(stu.name, "Jerry");
stu.age = 19;
stu.score = 88.0;
这里通过stu.name、stu.age和stu.score分别访问并设置了结构体变量stu的成员。
结构体数组
可以定义结构体数组来存储多个结构体变量。例如:
struct Student class[3];
这定义了一个名为class的结构体数组,它可以存储 3 个Student结构体变量。
初始化结构体数组:
struct Student class[3] = {{"Alice", 20, 92.0}, {"Bob", 19, 85.0}, {"Cindy", 21, 95.0}};
访问结构体数组中的成员:
例如,要访问第二个学生的成绩,可以使用class[1].score。
结构体指针
可以定义指向结构体的指针。例如:
struct Student *p;
struct Student stu = {"David", 20, 90.0};
p = &stu;
使用指针访问结构体成员:
可以通过(*p).name来访问stu的name成员,不过 C 语言提供了更简洁的方式p->name。同样,p->age和p->score可以分别访问age和score成员。
结构体作为函数参数
可以将结构体变量或结构体指针作为函数参数传递。
当传递结构体变量时,是值传递,会复制整个结构体,效率较低。例如
void printStudent(struct Student stu) {printf("Name: %s, Age: %d, Score: %.2f\n", stu.name, stu.age, stu.score);
}
当传递结构体指针时,是地址传递,效率较高。例如:
void printStudentPtr(struct Student *p) {printf("Name: %s, Age: %d, Score: %.2f\n", p->name, p->age, p->score);
}
嵌套结构体的定义
嵌套结构体是指在一个结构体中包含另一个结构体作为其成员。这种方式可以更好地组织复杂的数据结构,用于表示具有层次关系的数据。
例如,假设有一个表示日期的结构体Date,和一个表示学生信息的结构体Student,学生信息中包含生日(日期类型),就可以这样定义:
struct Date {int year;int month;int day;
};
struct Student {char name[20];int age;struct Date birthday;
};
在这里,Student结构体中有一个成员birthday,它的类型是Date结构体,这样就形成了嵌套结构体。
嵌套结构体变量的声明和初始化
声明:
可以按照常规的方式声明包含嵌套结构体的变量。例如,声明一个Student结构体变量stu:
struct Student stu;
初始化:
对于嵌套结构体变量的初始化,可以通过层层嵌套的方式进行。例如:
struct Student stu = {"Tom", 18, {2005, 6, 1}};
这里初始化了Student结构体变量stu,其中birthday成员(Date结构体类型)又被初始化为{2005, 6, 1}。
嵌套结构体成员的访问
要访问嵌套结构体中的成员,需要使用多个点(.)运算符来逐级访问。
例如,要访问stu变量中的生日年份,可以使用stu.birthday.year。同样,要修改生日月份,可以使用stu.birthday.month = 7;这样的语句。
嵌套结构体指针
可以定义指向包含嵌套结构体的指针。例如:
struct Student *p;
struct Student stu = {"Jerry", 19, {2004, 7, 1}};
p = &stu;
使用指针访问嵌套结构体成员:
可以通过(*p).birthday.year来访问stu的生日年份,不过更简洁的方式是p->birthday.year。同样,p->birthday.month和p->birthday.day可以分别访问月份和日期成员。
嵌套结构体作为函数参数
可以将包含嵌套结构体的变量或者指针作为函数参数传递。
当传递变量时,是值传递,会复制整个结构体,包括内部嵌套的结构体。例如:
struct Student *p;
struct Student stu = {"Jerry", 19, {2004, 7, 1}};
p = &stu;void printStudent(struct Student stu) {printf("Name: %s, Age: %d, Birthday: %d - %d - %d\n", stu.name, stu.age, stu.birthday.year, stu.birthday.month, stu.birthday.day);
}
当传递指针时,是地址传递,效率更高。例如:
void printStudentPtr(struct Student *p) {printf("Name: %s, Age: %d, Birthday: %d - %d - %d\n", p->name, p->age, p->birthday.year, p->birthday.month, p->birthday.day);
}
应用场景举例
在处理复杂的数据关系时非常有用。比如在图形编程中,一个图形对象结构体可能包含位置结构体(x、y坐标)、颜色结构体(r、g、b颜色分量)等嵌套结构体,用于精确地表示和操作图形的各种属性。
链表的基本概念
链表是一种常见的数据结构,它由一系列节点组成。每个节点包含数据部分和指向下一个节点的指针。单向链表中,节点的指针只能指向后续节点,形成一个线性的链接序列。
例如,链表就像是一列火车,每个车厢(节点)有自己的货物(数据),并且有一个挂钩(指针)连接到下一个车厢。
单向链表节点的定义
在 C 语言中,通常使用结构体来定义链表节点。结构体包含两个成员:数据成员和指针成员。
基本结构如下:
收起
typedef struct ListNode {int data; // 数据部分,可以是任何类型,这里以整数为例struct ListNode *next; // 指向下一个节点的指针
} ListNode;
这里使用typedef关键字为struct ListNode这个结构体类型定义了一个别名ListNode,方便后续使用。data成员用于存储节点的数据,next指针用于指向下一个节点。
链表的创建
创建链表的基本步骤是先创建头节点(一般是链表的第一个节点),然后逐个添加后续节点。
创建头节点:
ListNode *head = (ListNode *)malloc(sizeof(ListNode));
if (head == NULL) {// 内存分配失败处理return;
}
head->data = 0; // 初始化数据部分,这里假设初始数据为0
head->next = NULL; // 初始时,头节点的下一个节点为空
添加节点:
假设要向链表中添加一个新节点,其数据为newData。
ListNode *newNode = (ListNode *)malloc(sizeof(ListNode));
if (newNode == NULL) {// 内存分配失败处理return;
}
newNode->data = newData;
newNode->next = head->next; // 将新节点的下一个节点指向当前头节点的下一个节点
head->next = newNode; // 将新节点插入到链表中,作为新的头节点后的第一个节点
链表的遍历
遍历链表是指访问链表中的每个节点,通常使用一个指针来遍历。
ListNode *p = head->next;while (p!= NULL) {// 处理当前节点的数据,例如打印printf("%d ", p->data);p = p->next; // 移动指针到下一个节点}
上述代码从链表的第一个节点(头节点后的节点)开始,通过不断地将指针p移动到下一个节点,直到p为NULL(表示到达链表末尾),从而实现了对链表的遍历。
链表节点的插入和删除
插入节点:
假设要在节点preNode之后插入一个新节点newNode。
newNode->next = preNode->next;
preNode->next = newNode;
删除节点:
假设要删除节点delNode后的节点。
ListNode *temp = delNode->next;
delNode->next = temp->next;
free(temp);
在插入和删除操作中,关键是要正确地处理节点之间的指针关系,以保持链表的完整性。
链表的应用场景
链表在很多场景中有广泛应用。例如,在操作系统中用于管理进程链表,每个进程节点包含进程的相关信息(如进程 ID、状态等),通过链表可以方便地对进程进行调度和管理。在数据结构实现中,如栈和队列也可以基于链表来实现,以提供更灵活的存储和操作方式。
找到要删除的节点:
从头节点开始遍历链表,直到找到要删除的节点。通常,这个节点是通过某个特定的条件来确定的,比如节点的数据值。
找到要删除节点的前一个节点:
在遍历链表时,需要同时跟踪当前节点的前一个节点。这样,当找到要删除的节点时,我们已经知道了它的前一个节点。
更新前一个节点的指针:
将前一个节点的指针指向要删除节点的下一个节点。这样,链表中的节点顺序就被更新了,要删除的节点就被“跳过”了。
释放要删除节点的内存:
由于要删除的节点不再被链表中的任何节点引用,我们可以安全地释放它的内存。
基于AI的学习




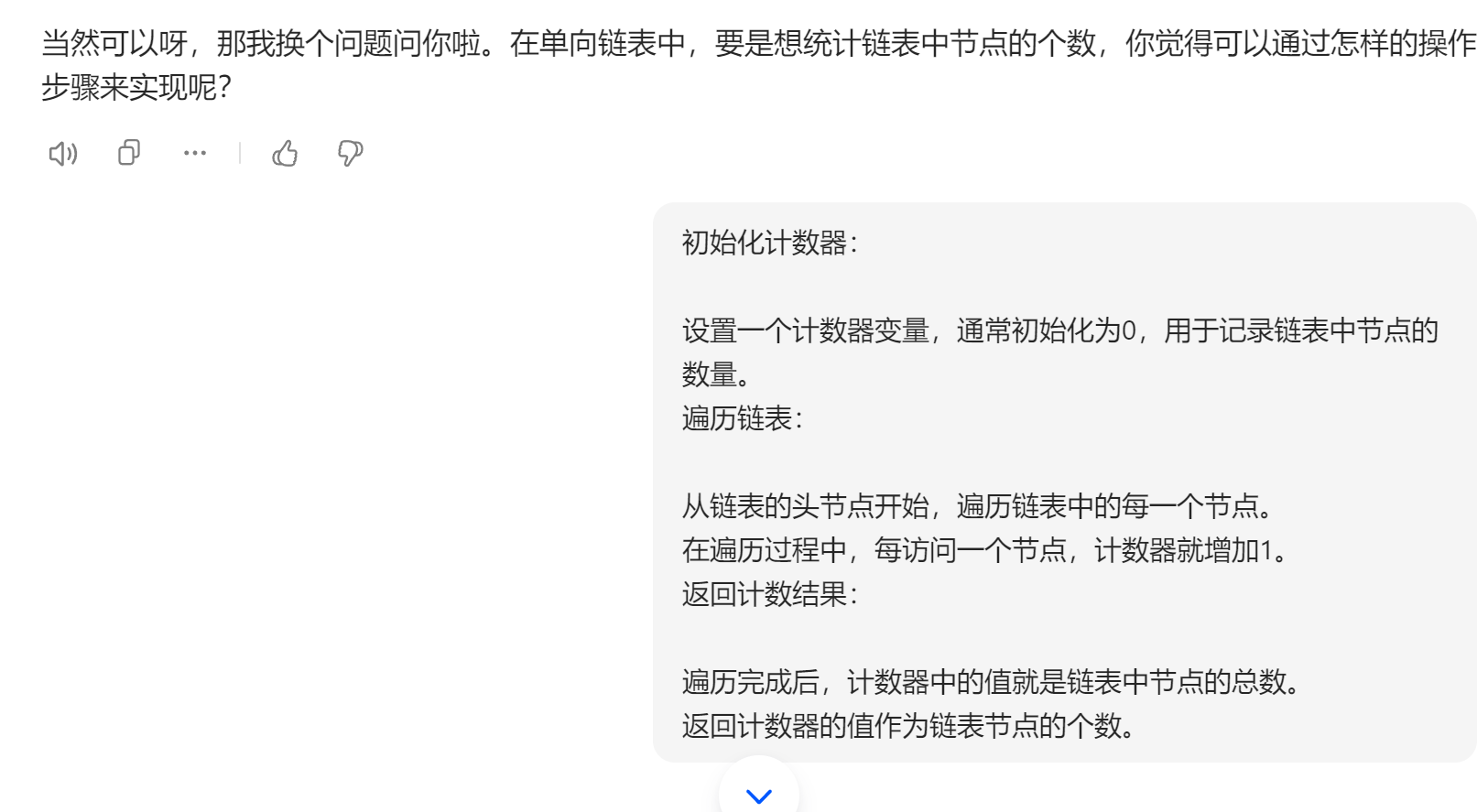
感悟
C 语言宛如一座神秘而深邃的编程殿堂,在探索其中的过程中,我收获了诸多宝贵的感悟。
起初,面对 C 语言复杂的语法和逻辑结构,我时常感到困惑与迷茫。那些密密麻麻的代码,就像一团乱麻,让人无从下手。然而,随着不断深入学习,我逐渐领略到它的精妙之处。通过亲手编写代码,从简单的 “Hello, World!” 程序开始,到逐渐构建起具有复杂功能的数据处理和算法实现程序,我体会到了创造的乐趣与成就感。
在学习变量、数据类型和运算符时,我明白了精准定义与巧妙运算的重要性,它们如同建筑中的基石与工具,奠定并塑造着程序的框架与功能。而函数的学习则让我意识到代码复用与模块化设计的魅力,能够将复杂的任务分解为一个个可管理的小模块,极大地提高了编程效率。
指针是 C 语言的一大特色,也是难点所在。理解指针就像是在迷宫中寻找出口,一旦掌握,便开启了一片新天地。它让我能够直接操控内存地址,实现更为高效和灵活的数据处理,但稍有不慎就会陷入错误的泥沼,这也培养了我严谨细致的编程思维。
C 语言的学习之路充满挑战,但每一次克服困难后的成长都让我更加坚定。它不仅教会我编程技能,更锤炼了我的逻辑思维、问题解决能力和耐心。我深知,在这条道路上我只是迈出了一小步,未来还有更多的知识等待我去探索和领悟,我将继续砥砺前行,在 C 语言的世界里挖掘更多的宝藏。