MySQL分页性能思考
关键词:深度分页
背景
最近有一个需求:在后台管理页面中,需要展示产品信息的列表。
之前版本开发中产品信息是用户填写完所有字段之后能进行保存。在之前的基础上需要支持用户不完全填写字段进行展示和保存的功能。
一个很简单的想法是为空也直接保存就可以了,但是由于之前的开发中MySQL中已经约束了字段NOT NULL,担心修改表结构引发一些意料之外的错误。
因此考虑使用Redis作为临时保存信息的能力,避免直接修改MySQL的数据表格式,同时一般设置来说Redis也只会丢失1s的数据,可以接受这个丢失。
使用Redis之后,如何在列表页展示产品信息呢?这个简单问题引发了我的一些思考。
mysql怎么做分页,有哪几种方案
简单和通用的做法:offset+limit,sql语句大概是:
select * from my_table where my_table.name = 'oneName' order by my_table.id limit 100000,10;
对于offset+limit的方案,其会在offset及大的时候性能变慢:10w的offset:0.742s,0的offset为0.006s。
性能低的原因在于:大量无意义的回表查询(回表总次数为offset+limit的值),丢弃了大量数据(offset),只保留了很少部分(limit) 。like:
- 通过普通二级索引树idx_update_time,过滤update_time条件,找到满足条件的记录ID。
- 通过ID,回到主键索引树,找到满足记录的行,然后取出展示的列(回表)
- 扫描满足条件的100010行,然后扔掉前100000行,返回。
其执行计划:
因此我们的优化思路在于:减少无意义的回表查询。
有三种方法:
-
使用子查询提前筛选出id,避免无意义的回表和筛选。在下面的例子中,就使用子查询先筛选出
a.id,避免大量回表。耗时约为0.038,由于有了子查询,耗时肯定是比offset为0要高的。语句like:select id,name,balance FROM account where id >= (select a.id from account a where a.update_time >= '2020-09-19' limit 100000, 1) LIMIT 10;(可以加下时间条件到外面的主查询) -
使用
inner join同一张表,原理其实和子查询是一样的。语句like:SELECT acct1.id,acct1.name,acct1.balance FROM account acct1 INNER JOIN (SELECT a.id FROM account a WHERE a.update_time >= '2020-09-19' ORDER BY a.update_time LIMIT 100000, 10) AS acct2 on acct1.id= acct2.id;
容易混淆:上面两个语句都用到了
SELECT a.id FROM account a WHERE a.update_time >= '2020-09-19' ORDER BY a.update_time LIMIT 100000, 10,但是需要注意,查询的是a.id,走的索引,并不会回表哦。
-
游标法:使用主键id作为游标,同样可以避免大量无意义的回表,语句范例如下。
select id,name,balance FROM account where id > 100000 order by id limit 10;
值得一提的是,对于上面三种优化,都只提及了id作为筛选项目,如果涉及更多where条件之类的,优化思路都是类似的,即:减少无意义的回表查询。
MySQL和Redis一起之后如何分页
在使用REDIS保存用户没有完全填写的产品信息之后,列表展示页面我们需要同时展示REDIS中保存的不完全填写的数据和MySQL中完全填写的数据。
对于列表页这样瀑布流展示的数据,在展示的时候我们需要合并MySQL和REDIS中的数据,并且尽量保持原有逻辑,按照产品id降序排列,如何做呢?
补充:REDIS保存的数据是用的String类型,key就是产品的id,value为产品信息序列化后的字符串。又使用了一个Zset来保存Redis中保存的产品id。
在考虑混合Redis中的数据之后,相比于只用考虑MySQL的的数据,难点在于分页非常不好做,常规的limit+offset方案的性能让人无法接收!
为什么性能差
我们原有的查询中,一般没有考虑深度分页的问题,都是直接limit+offset进行查询。
在混合进Redis的数据之后,数据分布可能如下图所示:
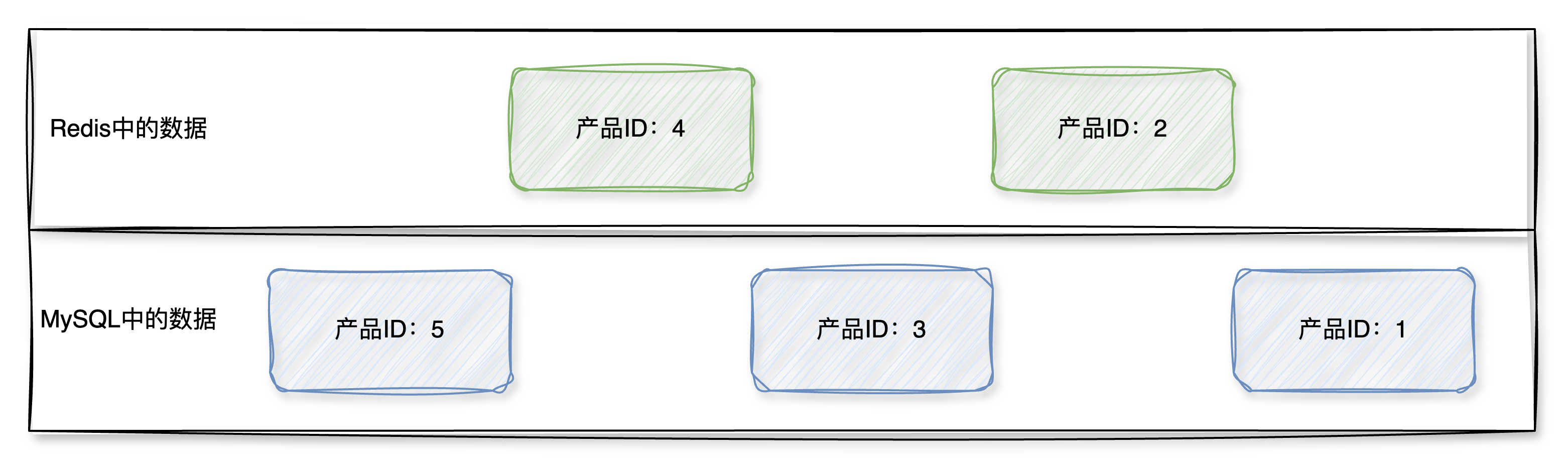
数据在Redis中和MySQL中并没有一个固定的顺序,而是交错的,在这样的情况下暴力的limit+offset的方案就会导致更多的无效查询,比如:如果需要查询每页50条数据,当前处于第30页。如果只考虑MySQL的查询,只用limit 30*50,50即可;现在同时考虑MySQL和Redis的数据查询,需要通过以下步骤:
- 第一步需要首先通过
limit 0,30*50+50塞选出MySQL中的产品ID; - 第二步取出Redis的zset中保存的所有的产品ID;
- 第三步在业务代码中按照顺序重新降序组装出本次展示所需要的产品ID;
- 第四步并再回到MySQL和REIDS中查询并组装展示;
上面第一步中直接全部取出产品信息会进一步增加耗时,这里已经算是优化后的步骤了。
上面的步骤看起来非常的“没有必要”,我们逐个解释一下:
- 第一步:第一步中为啥offset中要用
30*50+50取这么多产品ID,分明这次只需要50个数据?原因就在于混入Redis的数据之后,全局排名(偏移量)30*50的数据,在MySQL中排名(偏移量)的范围是[0,30*50],所以必须全部取出参与排序。 - 第二步:第二部中为啥要取出Redis中保存的所有的产品ID?原因在于Redis中zset虽然支持按照分数范围进行筛选,但是并不支持按照偏移量进行筛选,所以只能全部取出
- 第三步,第四步:很正常的步骤。
怎么优化
性能这么差,简直不能忍受!所以我们上面MySQL做分页的优化可以排上用场了。MySQL深度分页的几个优化思路(子查询、inner join、游标)中游标优化可以解决我们的问题,子查询和inner joint并不能解决我们的问题。
因为使用游标优化之后,无论是MySQL中取数据还是Redis中取数据我们都可以直接用游标来限制取数据的范围了:MySQL中可以用where xxx>? limit 0,50;Redis中zset中zrange取数据的时候也可以限制范围了。而剩下的两种优化方法本质上我们举得案例中就已经采用了,对这种多数据源合并的情况虽然可能有一些提升,但并没有解决本质问题。 不过改用游标法之后,我们需要前端同学配合我们修改,将原先的offset+limit的方案迁移到游标方案来。
实际上Redis来保存仍然有一些点需要考虑,比如说随着产品ID增多,会产生zset的bigkey问题,或者是产品本身信息过多带来的bigkey问题等等。
此外,我们也可以考虑一些代码之外的方案,比如说和业务商量一下是否可以不保证按照产品ID递减的方式来展示,可以先展示完缓存的数据等等~
参考:
mysql查询 limit 1000,10 和limit 10 速度一样快吗?如果我要分页,我该怎么办?-腾讯云开发者社区-腾讯云
更推荐看这个 实战!聊聊如何解决MySQL深分页问题

![[题解]AtCoder Beginner Contest 385(ABC385) A~F](https://img2024.cnblogs.com/blog/3322276/202412/3322276-20241221235543995-1846778698.png)