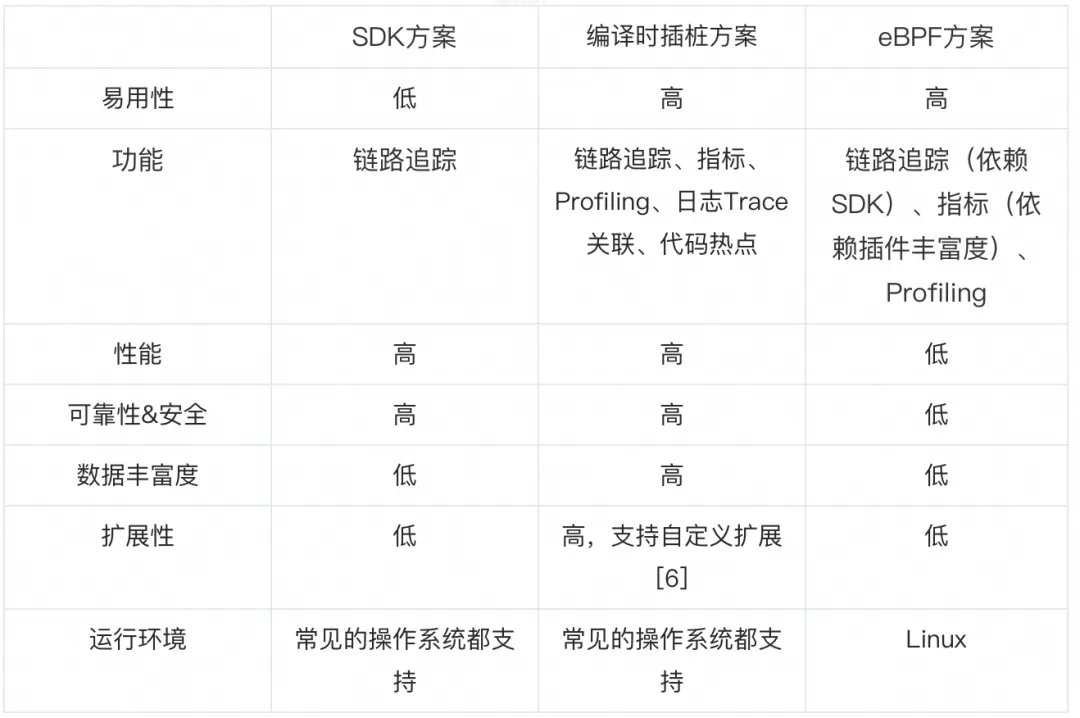
你提供的文件共同构建了一个基于 SUMO(交通模拟平台)的交通信号控制模拟环境。以下是每个模块的主要功能和作用:
1. Q学习智能体 (ql_agent.py)
- 这个文件实现了一个Q学习智能体类(
QLAgent),它与SUMO环境交互。 - 智能体使用Q表(Q-Table)进行决策,并根据状态、奖励和执行的动作动态更新策略。
- 使用ε-贪婪(epsilon-greedy)策略探索环境,部分概率基于Q表选择动作,部分概率随机选择。
2. 环境模块 (env.py)
- 实现了
SumoEnvironment类,这是模拟的核心部分。 - 这个类集成了SUMO交通模拟器,定义了观测空间、动作空间,并提供对模拟的控制。
- 支持单智能体模式和多智能体模式,用于多交通信号的控制优化。
- 使用 PettingZoo 库,支持多智能体交互和训练。
3. 观测函数模块 (observations.py)
- 包含
DefaultObservationFunction和基础类ObservationFunction。 DefaultObservationFunction为每个交通信号生成观测数据,包括信号阶段(如绿灯)、车道密度和排队信息。- 定义了观测空间,例如数据的范围和维度,用于指导智能体感知环境。
4. 交通信号控制 (traffic_signal.py)
- 表示每个SUMO模拟中的交通信号灯,提供控制信号灯的逻辑。
- 包含计算奖励、生成观测和控制信号灯状态(如绿灯、黄灯)的方法。
- 默认观测包括:当前绿灯阶段、车道密度、排队长度等。
- 支持多种预定义奖励函数,例如队列长度最小化和等待时间差异减少。
5. RESCO预设环境 (resco_envs.py)
- 定义了一些预设交通网络场景,例如网格结构和真实城市交通交叉路口(如科隆、英戈尔施塔特等)。
- 提供函数来初始化这些网络,支持并行环境运行以加速模拟和训练。
整体功能
这些模块之间是模块化设计,提供了灵活性,可以自定义智能体、环境、观测和奖励机制。该系统既适用于学术研究,也可用于优化实际交通信号系统。如果需要深入了解某个具体模块或功能,请告诉我!
中文总结
epsilon_greedy.py
- 实现了epsilon-greedy策略,用于平衡智能体的探索(随机选择动作)和利用(选择Q表中最优动作)。
- 主要功能:
choose方法根据当前的epsilon值选择动作,并逐步衰减epsilon值。reset方法重置epsilon为初始值。
plot_epsilon.py
- 用于可视化epsilon值的衰减过程。
- 功能:
- 接受初始epsilon值和衰减率参数。
- 绘制epsilon随迭代次数的变化图,展示探索与利用的变化趋势。
与整体系统的关系:
QLAgent使用EpsilonGreedy来选择动作,确保智能体在早期探索环境,后期更注重利用。plot_epsilon.py用于调试和优化epsilon参数,帮助用户直观了解探索概率的变化。
如果需要进一步解释或代码分析,请随时告诉我!