过去 9 年里,HelloGitHub 月刊累计收录了 3000 多个开源项目。然而,随着项目数量的增加,不少用户反馈:“搜索功能不好用,找不到想要的项目!” 这让我意识到,仅仅收录项目是不够的,还需要通过更智能的方式,帮助用户找到心仪的开源项目。于是,我开始探索如何通过 RAG 技术解决这个问题。
检索增强生成(RAG),是赋予生成式人工智能模型信息检索能力的技术。
RAG 技术我早有耳闻,但却一直不知道该从哪里入手。虽然现在有不少容易上手的 RAG 低代码平台,但我不想只停留在“会用”的层面,更希望了解它的实现细节,否则不敢在生产环境中用。不过,要让我直接用 LangChain 和 Ollama 从零搭建一个 RAG 系统,还真有点心里没底。

还好最近 OceanBase 搞事情,在 4.3.3 版本里支持了向量检索功能,更贴心的是,还专门为像我这样对 RAG 感兴趣的新手,准备了一个用 Python 搭建 RAG 聊天机器人的实战教程。

GitHub 地址:github.com/oceanbase/oceanbase
光看永远只是纸上谈兵,所以我干脆上手把玩了一番。

接下来,我将分享如何基于该项目,打造一款 HelloGitHub 开源社区的聊天机器人,内容包括实现过程、细节优化,以及对 RAG 技术的理解与未来展望。
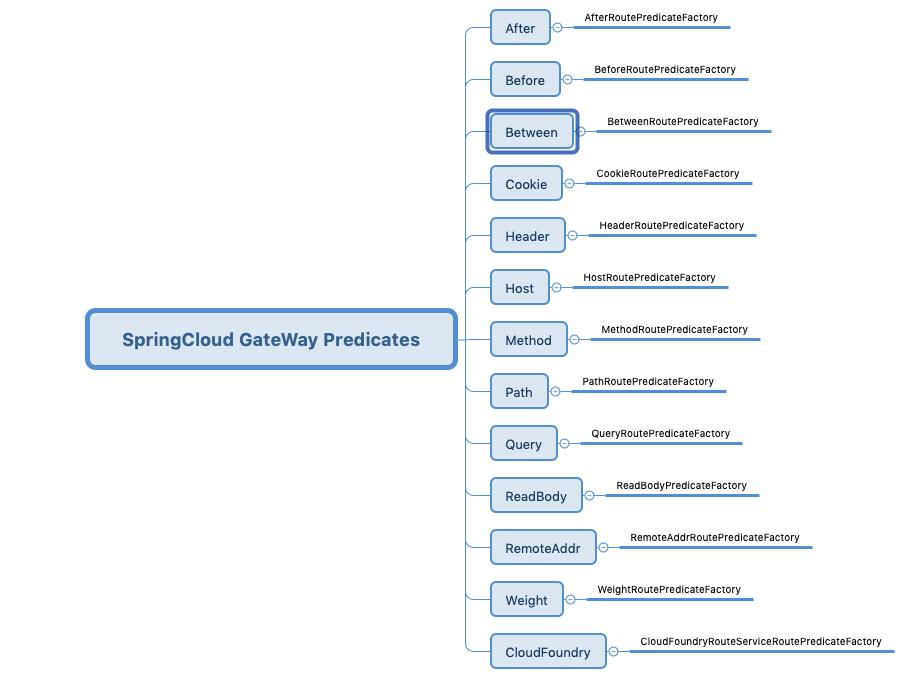
一、介绍
OceanBase 开源的 RAG 聊天机器人,能够通过自然对话更精准地回答与 OceanBase 文档相关的问题。

该项目是基于 langchain、langchain-oceanbase 和 streamlit 构建,处理流程是先将 OceanBase 数据库的文档,通过 Embedding 模型转化为向量数据,并存储在 OceanBase 数据库中。当用户提问时,系统会用相同的模型将问题转化为向量,然后通过向量检索找到相关的文档内容,再将这些文档作为上下文提交给大语言模型,从而生成更精准的回答。
在线体验:oceanbase.com/obi
体验后,我感觉效果还不错,于是就萌生了一个想法:能不能把 OceanBase 的文档,换成 HelloGitHub 月刊的 Markdown 文件,灌进系统里,这样不就摇身一变,成为 HelloGitHub 专属的聊天机器人了吗? 说干就干!
二、安装运行
在开始改造之前,首先需要把项目跑起来。安装运行的步骤在 OceanBase 提供的实战教程中已经很详细了,这里不再过多介绍。运行步骤如下:
- 执行
embed_docs.py脚本,将文档内容向量化后存储到 OB - 启动项目
streamlit run --server.runOnSave false chat_ui.py
启动成功将自动跳转至此界面:

建议:
- Python 版本管理:运行需要 Python 3.9+,建议使用
pyenv管理项目的 Python 版本。 - 查看数据库:不论是通过 Docker 部署 OceanBase 还是使用 OB Cloud,都建议在本地通过 GUI 工具查看数据库,有助于开发和调试。

运行 embed_docs.py 脚本后,查看数据库中的表,你会发现这些字段:
document:存储原始的文档内容embedding:存储文档向量化后的数据metadata:记录文档的名称、路径以及切分后的标题等信息
其中 embedding 列是一个类似数组形式的数据,这个就是通过 Embedding 模型将文档片段转化为向量数据的结果。这些向量数据能够捕捉文本的语义信息,使计算机能够更好地理解文本的含义,从而实现类似语义搜索的功能(计算距离),为后续问题与文档内容的匹配提供基础。

三、动手改造
这个项目除了支持 LLMs API,还可以切换为本地的 Ollama API 使用,只需修改 .env 配置文件即可完成调整:
# 使用支持 embed API 的模型
OLLAMA_URL=localhost:11434/api/embed
OLLAMA_TOKEN=
OLLAMA_MODEL=all-minilm
注意:在调用第三方付费 API 时,一定要注意使用量,建议仅导入部分文档用于测试,或用本地 LLM 调试逻辑,避免不必要的花费。
3.1 导入 HelloGitHub 月刊
通过 embed_docs.py 脚本,将 HelloGitHub 月刊内容向量化并导入到 OceanBase 数据库,命令如下:
python embed_docs.py --doc_base /HelloGitHub/content --table_name hg
参数说明:
doc_base:HelloGitHub 内容目录table_name:脚本会自动创建该表,并将数据存储到表中。
但是运行后,我查看数据库时发现 document 字段中包含了许多无意义的内容,例如格式符号或无关信息:

面对这些噪声数据,我编写了一个脚本,清洗 HelloGitHub 月刊文件中无关的格式符号和冗余内容,并重新导入数据库。

3.2 启动服务
在启动服务时,需要通过环境变量 TABLE_NAME 指定要使用的表。命令如下:
TABLE_NAME=hg2 streamlit run --server.runOnSave false chat_ui.py
我试了一下,回答的效果并不理想:

经过测试,我分析问答效果欠佳的原因,可能包括以下几点:
- 向量化效果:所选用的模型 all-minilm 仅有 384 维度,可以尝试更大的 Embedding 模型;
- 数据清理:虽然清理了一部分无用内容,但可能还有一些噪声数据未处理完全;
- 文档完整性:HelloGitHub 的内容结构是否适合问答模型需要进一步分析;
- 提示词:需要完善提示词设计,补充更多上下文;
四、优化问答效果
我开始对 RAG 有些感觉了,所以准备切换到付费但效果更好的通义千问 text-embedding-v3 模型(1024 维度),进行调试。
4.1 数据优化
为提升问答效果,我决定进一步优化 document 的构造方式。具体思路是:将 HelloGitHub 网站中的表导入至 OceanBase 数据库,并基于这些表的数据,构建更干净和精准的内容。这样可以最大程度地确保项目数据的全面性,同时减少无关内容的干扰,提升向量检索相关性。
导入表到 OceanBase
OceanBase 和 MySQL 高度兼容,因此,我直接用 Navicat 将 HelloGitHub 的数据表结构和内容,从 MySQL 无缝迁移到了 OceanBase。然后我写了一个 embed_sql.py 脚本,通过直接查询相关表的数据,进而生成更精简的内容(document),同时补充元数据(metadata),并存储到数据库。核心代码如下:
# 构建内容(document)
content = f"""{row.get('name', '未知')}:{row.get('title', '未知标题')}。{row.get('summary', '暂无概要')}"""# 构建元数据(metadata)
metadata = {"repository_name": row.get("name", "N/A"), # 仓库名称"repository_url": row.get("url", "N/A"), # 仓库链接"description": row.get("summary", "N/A"), # 项目描述"category_name": row.get("category_name", "N/A"), # 类别名称"language": row.get("primary_lang", "N/A"), # 主要编程语言"chunk_title": row.get("name", "N/A"), "enhanced_title": f'内容 -> {row.get("category_name", "N/A")} -> {row.get("name", "N/A")}'...
}# 将内容和元数据添加到文档对象
docs.append(Document(page_content=content.strip(), metadata=metadata))
# 存储到数据库
vs.add_documents(docs,ids=[str(uuid.uuid4()) for _ in range(len(docs))],
)
经过多轮调试和对比,我发现 document 数据越精简,向量检索效果越好,随后将完整的数据集存入 OceanBase 数据库的 hg5 表。
python embed_sql.py --table_name hg5 --limit=4000
args Namespace(table_name='hg5', batch_size=4, limit=4000, echo=False)
Using RemoteOpenAI
Processing: 100%|███████████████████████████████████████████████████████████████████████▉| 3356/3357 [09:33<00:00, 5.85row/s]

至此,基于数据库表构造的 document 数据,已经非常干净了。
4.2 提示词优化
在优化完数据后,我开始思考如何优化提示词,并对 LLM 的回答进行引导和强化。以下是针对 LLM 提示词优化的方向:
- 明确背景和任务:在提示词中设定问答的背景并限制问题的范围,例如,确保问题只涉及开源项目或 HelloGitHub 的内容。
- 丰富上下文:将 metadata(元数据) 和 document(项目描述)同时提供给大模型,让 LLM 有更多上下文来生成精确回答。
- 高质量示例:提供高质量的回答示例,统一输出格式。
- 约束逻辑:明确要求 LLM 不得虚构答案。如无法回答问题,需清楚指出知识盲点,并合理提供方向性建议。
4.3 处理流程优化
在优化向量检索和回答的流程方面,我做了以下改进:
- 扩大检索范围:向量检索默认只返回前 10 条最高相似度的内容。我将其扩展至 20 条,为 LLM 提供更多上下文选择。
- 判断相关性:使用提示词指导 LLM 在输出答案前,先判断问题是否与 HelloGitHub 或开源项目相关,避免生成无关回答。
- 提炼回答:基于用户输入分析意图后,选出最相关的 5 个项目,并结合元数据生成更贴合用户需求的回答。
4.4 效果展示
除了上面的优化,我还进一步简化了页面、删除用不到的代码,最终呈现效果如下:

回答效果对比:

通过切换至通义千问 text-embedding-v3 模型,同时优化数据、提示词策略和问答流程,让这套 RAG 系统的回答质量有了明显提升,我打算自己盘一盘再上线。所以先放出源码,感兴趣的小伙伴可以作为参考:
GitHub 地址:github.com/521xueweihan/ai-workshop-2024
五、最后
在构建 HelloGitHub 的 RAG 聊天机器人过程中,回答效果一直不好,让我一度产生了放弃的念头。但当我通过查询表里的数据构造 document,并使用维度更大的 Embeding 模型后,回答效果直线提升,才让我重新看到了希望。

这段经历也让我开始认真思考:优化 RAG 的关键是什么?我的答案是 数据+检索。如今,许多企业希望借助 AI 技术赋能已有服务,RAG 则是一种门槛较低的通用解决方案。在这一过程中,数据质量决定了基础,高质量数据往往是从海量数据提纯而来。检索则是确保内容能够被快速且准确提取的关键。否则不管提示词再怎么优化,也无法检索到有价值的内容,就无法实现增强的效果。
另外,我认为在未来的 RAG 应用中,除了向量数据,数据库还需要具备一些关键能力来确保检索和生成的高效性。例如,支持关系型数据和向量数据的混合搜索,不仅能处理结构化和非结构化数据,还能有效减少 RAG 模型中的“幻觉”问题,从而让生成的答案更准确、更有根据。图搜索(知识图谱)同样很重要,它为 RAG 提供复杂推理所需的背景信息,提升生成质量。此外,RAG 应用在许多场景中需要频繁更新和同步数据,因此数据库还需支持实时查询、低延迟响应、事务处理和高可用性,这些是确保 RAG 高效运行的基础。
OceanBase 的分布式架构优势,让它在面对海量数据时依然游刃有余。而新引入的向量存储和检索能力,使得我们能够通过 SQL 轻松获取最“干净”的数据,并在同一个数据库内完成向量化操作。OceanBase 未来可期!
GitHub 地址:github.com/oceanbase/oceanbase
虽然 RAG 技术目前还不像 Web 开发那么成熟,但作为一个潜力巨大的技术方向,值得我们持续关注和学习。作为一名刚刚踏上 RAG 探索之旅的小白,我还有很多需要学习的地方。如果你也对 RAG 充满兴趣,欢迎结伴而行、共同成长!

![[密码管理/信息安全] 密码管理工具:KeePass vs LastPass vs 1Password [转]](https://blog-static.cnblogs.com/files/johnnyzen/cnblogs-qq-group-qrcode.gif?t=1679679148)