《JMeter JDBC 请求实战宝典》
宝子们,今天咱就来唠唠 JMeter 里超厉害的 JDBC 请求,这玩意儿就像是数据库世界的神奇魔杖,能帮咱把数据库里的各种秘密(数据)都挖出来,还能对这些数据进行各种操作,不管是查查看、改一改,还是加点新东西、删点旧东西,它都能轻松搞定,而且还能告诉咱数据库在这些操作下是不是够 “给力”,性能咋样。接下来,咱就一步一步揭开它的神秘面纱。
一、JDBC 请求的作用和适用场景
(一)作用
- 数据库操作模拟
- JDBC 请求允许我们在 JMeter 中直接与数据库进行交互,就像我们亲自在数据库管理工具中执行 SQL 语句一样。我们可以通过它发送各种 SQL 查询,如查询数据(SELECT)、插入新记录(INSERT)、更新现有数据(UPDATE)和删除数据(DELETE)等操作。这对于测试数据库驱动的应用程序的功能和性能至关重要。例如,在一个电商系统中,我们可以使用 JDBC 请求来测试用户注册时数据插入数据库是否正确,订单处理过程中数据的更新是否及时准确,以及查询商品信息时数据库的响应速度等。
- 性能测试与优化
- 它能帮助我们评估数据库在不同负载条件下的性能表现。通过模拟大量并发用户对数据库进行各种操作,我们可以测量数据库的响应时间、吞吐量和错误率等关键性能指标。比如,在一个社交网络平台中,大量用户同时发布动态、点赞、评论等操作都会涉及数据库操作,我们可以利用 JDBC 请求模拟这些高并发场景,找出数据库可能存在的性能瓶颈,以便进行优化。例如,如果发现查询用户动态的响应时间过长,可能是查询语句没有优化或者数据库索引设置不合理,我们就可以针对性地进行改进。
- 数据验证与完整性检查
- 在测试过程中,我们可以使用 JDBC 请求从数据库中获取数据,并与预期结果进行比较,以验证数据库中的数据是否正确和完整。例如,在一个在线支付系统中,完成一笔交易后,我们可以通过 JDBC 请求查询数据库中该交易的状态、金额等信息,与系统显示给用户的信息进行对比,确保数据的一致性。如果发现数据不匹配,就可能存在系统漏洞或数据处理错误,需要及时排查。
(二)适用场景
- 企业级应用测试
- 对于大型企业级应用,如企业资源规划(ERP)系统、客户关系管理(CRM)系统等,数据库是核心组成部分。JDBC 请求可以用于测试这些系统中各种业务流程对数据库的操作,如员工信息管理、订单处理、库存管理等模块。在 ERP 系统中,我们可以模拟多个部门同时进行采购订单创建、库存盘点、财务报表生成等操作,通过 JDBC 请求监测数据库的性能和数据准确性,确保整个企业业务流程的顺畅运行。
- 电商平台测试
- 电商平台涉及大量的商品信息管理、用户订单处理、库存更新等数据库操作。在商品促销活动期间,大量用户同时浏览商品、下单购买、查询订单状态等,我们可以使用 JDBC 请求模拟这些高并发场景,评估数据库在峰值负载下的性能,确保用户购物体验的流畅性。同时,也可以通过数据验证确保商品信息、订单数据等在数据库中的存储和处理正确无误。
- 金融系统测试
- 金融系统对数据的准确性、完整性和安全性要求极高。JDBC 请求可用于测试银行的核心业务系统,如账户管理、交易处理、报表生成等功能。例如,在模拟大量用户同时进行转账、查询账户余额、生成交易明细报表等操作时,通过 JDBC 请求监控数据库的性能和数据的一致性,确保金融交易的准确和安全,避免出现数据错误或交易丢失等严重问题。
二、准备工作:给 JMeter 和数据库 “牵红线”
(一)准备数据库驱动
这就好比你要跟数据库 “交流”,得有个 “翻译官”,这就是 JDBC 驱动。不同的数据库需要不同的驱动,就像不同国家的人说不同语言,得找对应的翻译。
- 根据数据库类型下载驱动
- 要是你的数据库是 MySQL,那就去下载 MySQL 的 JDBC 驱动,比如 mysql - connector - java - [版本号].jar。要是 Oracle,就下 ojdbc - [版本号].jar;SQL Server 就下 mssql - jdbc - [版本号].jar;PostgreSQL 就下 postgresql - [版本号].jar。宝子们可别下错了哦,不然 JMeter 和数据库就没法正常 “聊天” 啦。
- 把驱动放到 JMeter 的 “lib/ext” 目录下
- 把下载好的驱动文件复制到 JMeter 安装目录下的 “lib/ext” 文件夹里。这一步很关键哦,就像给 JMeter 装上了能听懂数据库 “语言” 的耳朵,这样它才能跟数据库顺畅地 “聊天”,不然就会出现 “鸡同鸭讲” 的尴尬局面。
三、配置 JDBC 连接:搭建数据库的 “专属通道”
(一)添加 JDBC Connection Configuration 元件
在 JMeter 里新建一个测试计划,然后右键点击测试计划,选 “添加”->“配置元件”->“JDBC Connection Configuration”,这就相当于开始给数据库建一条 “专属通道” 啦。
(二)配置连接参数
- Variable Name Bound to Pool(绑定到池的变量名)
- 你可以自己起个变量名,比如 “myDBPool”。这个名字就像通道的名字,以后在 JDBC 请求里要靠它找到这条通道,连接到数据库。要是名字没取好,JMeter 就会像个迷路的孩子,找不到去数据库的路,那可就麻烦大了。
- Connection Pool Configuration(连接池配置)
- Max Number of Connections(最大连接数)
- 这就好比通道上最多能同时跑多少辆车。如果是测试一个电商系统的数据库,在促销活动期间,可能会有大量用户同时查询订单、商品信息等,那这个数就得根据数据库服务器的性能适当设大些,比如 100。但要是数据库服务器配置一般,你设太大,它可能就 “堵车” 崩溃了。就像一条小路,你非要让太多车同时走,那不就堵得死死的,啥也干不了了。
- Max Wait (ms)(最大等待时间)
- 想象一下,如果通道满了,后面的车(请求连接的线程)最多愿意等多久呢?比如设成 8000(8 秒),超过这个时间,线程可能就不耐烦,直接报错了,这就像司机等太久就生气走人一样。
- Time Between Eviction Runs (ms)(驱逐运行时间间隔)
- 这就像是定期检查通道上有没有长时间停着不走的车(空闲连接)。设成 60000(1 分钟)比较合适,这样能及时清理那些闲置太久的连接,把通道让给真正需要的请求。就像你得时不时清理一下停车场里长期占着车位不挪窝的车,不然其他车就没地方停啦。
- Auto Commit(自动提交)
- 如果选 “True”,就好比每辆车(SQL 语句)一通过通道(执行),就自动登记(提交事务)。但如果是测试一个银行转账系统,你肯定不希望每转一笔账就自动提交,万一中间出错了,钱就可能莫名其妙地没了。所以这种情况就得选 “False”,等所有转账步骤都成功了,再手动提交事务,确保数据的完整性。这就像你寄快递,得确保所有东西都打包好、地址写对了,才放心交给快递员,而不是寄一件交一次钱,万一有问题都不知道咋找回。
- Transaction Isolation(事务隔离级别)
- 一般选 “DEFAULT” 就行,就用数据库默认的事务隔离级别。不过在一些特殊情况下,比如你要测试并发事务对数据一致性的影响,可能就得手动调整这个级别。比如在一个机票预订系统中,同时有多个用户预订同一航班的最后一张票,你就得调整事务隔离级别来确保不会出现超售的情况。这就像大家在抢演唱会门票,得有个规则(事务隔离级别)来保证不会把同一张票卖给好多人,不然就乱套了。
- Max Number of Connections(最大连接数)
- Connection Validation by Pool(通过池进行连接验证)
- Test While Idle(空闲时测试)
- 要是选 “True”,就像在车(连接)空闲的时候检查一下车有没有毛病(连接是否有效)。这能及时发现可能出现的连接问题,避免在关键时刻掉链子。比如在一个实时股票交易系统中,连接突然出问题,那可就麻烦大了,所以空闲时测试很重要。就像你开车出门前,得检查一下车有没有问题,不然在路上抛锚了,那可就耽误大事了。
- Soft Min Evictable Idle Time (ms)(软最小可驱逐空闲时间)
- 这是说空闲的车(连接)在通道上停多久就可以被赶走。比如设成 4000(4 秒),那空闲超过 4 秒的连接就可能被清理掉,把位置让给其他需要的连接,这样能保证通道的高效利用。这就像停车场规定,车停太久没人用,就得挪走,给其他车腾地方。
- Validation Query(验证查询)
- 这是用来检查连接有没有问题的查询语句。不同的数据库有不同的 “体检项目”:
- MySQL:一般用 “Select 1” 就行,简单快速地检查连接是否正常。这就像你跟数据库打个招呼,看看它有没有回应,回个 “1” 就说明它还在那儿,挺好的。
- Oracle:可以用 “Select 1 from dual”,这是 Oracle 的 “特色体检项目”。
- SQL Server:通常也是 “Select 1”。
- PostgreSQL:用 “Select 1” 就能搞定。
- 这是用来检查连接有没有问题的查询语句。不同的数据库有不同的 “体检项目”:
- Test While Idle(空闲时测试)
- Database Configuration(数据库配置)
- Database URL(数据库 URL)
- 这就像数据库的家庭住址,你得准确地告诉 JMeter 数据库住在哪儿。
- MySQL:格式是 “jdbc:mysql://[主机名]:[端口号]/[数据库名]”,比如 “jdbc:mysql://localhost:3306/eshop”,这里 “localhost” 是主机名,“3306” 是 MySQL 默认的端口号,“eshop” 是数据库名。这就像你要去朋友家,得知道他家的具体地址,不然怎么找得到呢?
- Oracle:格式是 “jdbc:oracle:thin:@[主机名]:[端口号]:[数据库实例名]”,像 “jdbc:oracle:thin:@192.168.1.100:1521:orcl” 这样。
- SQL Server:格式是 “jdbc:sqlserver://[主机名]:[端口号];databaseName = [数据库名]”,例如 “jdbc:sqlserver://localhost:1433;databaseName = mydb”。
- PostgreSQL:格式是 “jdbc:postgresql://[主机名]:[端口号]/[数据库名]”,比如 “jdbc:postgresql://localhost:5432/finance”。
- 这就像数据库的家庭住址,你得准确地告诉 JMeter 数据库住在哪儿。
- JDBC Driver class(JDBC 驱动类)
- 这是连接数据库的 “司机”,不同的数据库得有不同的 “司机”。
- MySQL:“com.mysql.jdbc.Driver”(新点儿的版本可能是 “com.mysql.cj.jdbc.Driver”)。
- Oracle:“com.oracle.jdbc.OracleDriver”。
- SQL Server:“com.microsoft.sqlserver.jdbc.SQLServerDriver”。
- PostgreSQL:“org.postgresql.Driver”。这就像不同的车(数据库)得找对应的司机(JDBC 驱动类),不然可开不动哦。
- 这是连接数据库的 “司机”,不同的数据库得有不同的 “司机”。
- Username(用户名)和 Password(密码)
- 这就是进入数据库的 “钥匙” 啦,得填上合法的用户名和密码,才能顺利地进入数据库的 “家门”。要是钥匙不对,那门可就打不开咯,就没办法跟数据库 “玩耍” 了。
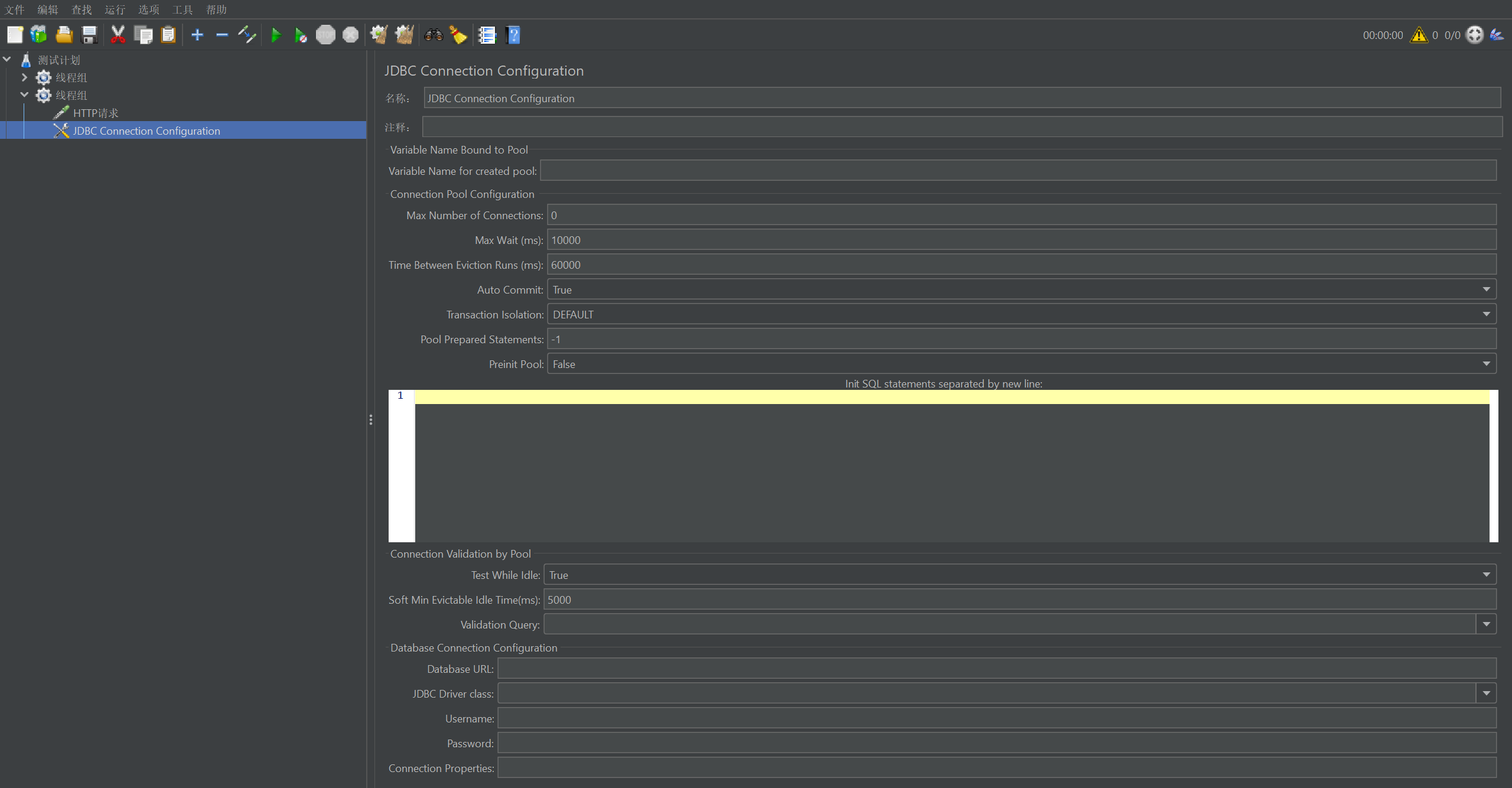
- 这就是进入数据库的 “钥匙” 啦,得填上合法的用户名和密码,才能顺利地进入数据库的 “家门”。要是钥匙不对,那门可就打不开咯,就没办法跟数据库 “玩耍” 了。
- Database URL(数据库 URL)
四、创建 JDBC 请求:给数据库派活儿
(一)添加 JDBC Request 元件
右键点击线程组(要是没有线程组,就先添加线程组,方法是右键点击测试计划,选 “添加”->“线程组”),然后选 “添加”->“Sampler”->“JDBC Request”,这就相当于准备给数据库派活儿啦。
(二)配置 JDBC 请求参数
- Variable Name Bound to Pool(绑定到池的变量名)
- 把之前在 JDBC Connection Configuration 里设的变量名填进来,比如 “myDBPool”,这样就能通过这条 “通道” 把任务送到数据库啦。要是填错了,任务可就送不到地方了哦。
- Query Type(查询类型)
- 这就是你要给数据库安排的 “工作类型”,有好几种选择呢。
- Select Statement(查询语句)
- 这就像你去数据库里找东西,比如在一个电商系统里,你想看看所有用户的订单信息,就可以写 “SELECT * FROM orders”,这就是让数据库把订单表的数据都找出来给你。就像你让店员把仓库里所有的某种商品都拿出来给你看看,是不是很简单?
- Update Statement - 也用于 Inserts 和 Deletes(更新语句,也用于插入和删除)
- 要是你想改改数据,或者加点新数据、删点旧数据,就用这个。比如在一个用户管理系统中,“UPDATE users SET age = 25 WHERE id = 1” 就是把 id 为 1 的用户年龄改成 25(更新);“INSERT INTO users (name, age) VALUES ('John', 30)” 是往用户表里加一个叫 John、年龄 30 的新用户(插入);“DELETE FROM users WHERE id = 2” 是把 id 为 2 的用户删掉(删除)。这就像你对商品不满意,让店员把商品的某个信息改一改,或者再放一个新商品进去,或者把某个旧商品拿走,是不是很好理解?
- Callable Statement(可调用语句)
- 这就像你去数据库里找一个特别会干活的 “小助手”(存储过程)来帮你干活。比如在一个物流系统中,数据库里有个存储过程叫 “calculate_shipping_cost ()” 是用来计算运费的,你就可以写 “{call calculate_shipping_cost ()}” 来调用它。这就像你在超市找一个专业的收银员来帮你算账,比你自己慢慢算快多了,而且还准确。
- Prepared Select Statement(预编译查询语句)
- 这个和普通的查询语句差不多,但是更厉害,它是预编译的,就像提前把任务安排好,性能更好,也更安全。比如在一个论坛系统中,“SELECT * FROM posts WHERE category =?”,这里的 “?” 就是个占位符,等会儿你可以把具体的帖子分类条件填进去。这就像你提前跟店员说你要找哪种类型的商品,让他先准备好,等你来了直接拿给你,是不是很高效?
- Prepared Update Statement - 也用于 Inserts 和 Deletes(预编译更新语句,也用于插入和删除)
- 也是预编译的,用来做更新、插入或者删除操作。比如在一个在线教育系统中,“UPDATE courses SET status =? WHERE course_id =?”,这里的 “?” 也是占位符,等会儿你可以把课程的新状态和课程 ID 填进去。这就像你提前告诉店员要修改哪个商品的什么信息,让他提前准备好,干活就更快啦。
- Select Statement(查询语句)
- 这就是你要给数据库安排的 “工作类型”,有好几种选择呢。
- SQL Query(SQL 查询)
- 根据你选的查询类型,把相应的 SQL 语句填进来。注意哦,别在后面加尾随分号,就像你说话别拖拖拉拉的。对于 Callable 语句,你得看看数据库有没有特殊要求,有时候可能得用 “{” 和 “}” 把它括起来,就像给复杂的指令包个包装,让数据库能明白你的意思。这就像你给店员下指令,得说得清楚明白,不然店员会一头雾水,不知道该干啥。
- Parameter Values(参数值)和 Parameter Types(参数类型)
- 如果你的查询是预编译或者可调用语句,而且还有参数,那就得把参数值和参数类型填好。
- Parameter Values
- 这是用逗号隔开的参数值列表。要是参数值是 NULL,你得写成 “] NULL [”,别直接写 “NULL”。要是参数值里有逗号或者双引号,你得把整个列表用双引号括起来,而且里面的双引号得写成两个。比如说 “Dbl - Quote: "" and Comma:,”。这就像你给店员列了一个清单,要把每个物品(参数值)的情况都写清楚,不然店员会看不懂哦。
- Parameter Types
- 这是用逗号隔开的 SQL 参数类型列表,像 INTEGER、DATE、VARCHAR、DOUBLE 这些。要是你用的是自定义的数据库类型,还可以用常量的整数值。对于可调用语句里的 INOUT 或者 OUT 参数,你得把类型写清楚,比如 “INOUT INTEGER”。参数类型的数量得和占位符的数量一样多,不然数据库就不知道你在说啥啦,就像你给店员的清单上,物品数量和对应的描述数量得一致,不然店员会糊涂的。这就好比你告诉店员要找几种不同类型的商品,得明确说清楚每种商品的类别,不然店员怎么知道你要啥呢?比如说你要找 3 件商品,分别是整数型的年龄、日期型的生日和字符串型的名字,那你就得把这三个参数类型依次告诉店员,这样店员才能准确地帮你找到对应的商品(数据)。而且对于一些特殊的数据库操作,比如调用存储过程中的输入输出参数,明确参数类型就更加重要了,不然数据可能会被错误地处理,就像你给店员一个错误的商品类别,店员可能会拿错东西给你哦。
- Parameter Values
- 如果你的查询是预编译或者可调用语句,而且还有参数,那就得把参数值和参数类型填好。
- Variable Names(变量名)
- 这是用逗号隔开的变量名列表,用来存查询结果的。比如说你用 Select 语句或者预编译查询语句查出来的数据,或者调用存储过程返回的值,都可以存到这些变量里。要是你调用存储过程,变量名的顺序得和 OUT 参数的顺序一样。要是变量名比 OUT 参数少,那就只能存和变量名数量一样多的结果;要是变量名多了,多出来的就不管啦。这就像你准备了几个小盒子(变量名)来装店员给你的东西(查询结果),得提前把盒子准备好,而且大小和数量要合适哦。
- Result Variable Name(结果变量名)
- 如果你填了这个,JMeter 就会给你创建一个包含行映射列表的 Object 变量。你可以用 “columnValue = vars.getObject ("resultObject").get (0).get ("Column Name");” 这样的方式来获取值。这就像 JMeter 给你一个大箱子(结果变量),把查询结果整整齐齐地装在里面,你要拿的时候就可以很方便地找到啦,就像从大箱子里找你想要的东西一样。
- Query Timeout (s)(查询超时时间,单位为秒)
- 你可以设个时间,让数据库在这个时间内把活干完。空着的话就是 0,表示无限大时间,数据库慢慢干就行。要是设成 - 1,就是不设超时时间。不过有时候你得根据情况设一下,别让数据库干活干得太久,把你给等急了。比如在一个金融交易系统中,查询超时可能会导致交易失败,所以要根据业务的响应时间要求合理设置,就像你让店员找东西,不能让他找太久,不然你就错过其他重要的事情啦。
- Limit ResultSet(限制结果集)
- 这就像你跟数据库说 “你别把所有数据都给我,给我一部分就行”。空值表示 - 1,就是不限制,数据库会把所有符合条件的数据都给你。你要是设个数字,比如 10,那数据库就只给你前 10 行数据,这样能减少数据量,让测试跑得更快,也能省点内存。在一个数据量巨大的数据分析系统中,可能不需要全部数据,只看前几百行数据来初步分析性能就够了,这时限制结果集就很有用,就像你从图书馆借资料,不需要把整个书架的书都搬回家,只拿你最需要的几本就行。
- Handle ResultSet(处理结果集)
- 这是在说数据库把数据给你之后,你要怎么处理这些数据。
- Store as string(默认,存储为字符串)
- 就是把数据都当成字符串存起来,也不会去遍历结果集。如果是 CLOB 类型的数据,就把它转成字符串;要是 BLOB 类型的数据,就把它当成 UTF - 8 编码的字节数组转成字符串。而且 CLOB 和 BLOB 数据在达到一定字节数(由 jdbcsampler.max_retain_result_size 决定)之后就会被截断。这就像你把数据库给你的数据一股脑地堆在一起,不仔细去翻看里面的具体内容,只是简单地把每个数据当成一个小纸条(字符串)记录下来。如果碰到那种很长很长像一大卷胶带(CLOB 类型数据)的数据,就把它剪成一段一段的字符串;要是遇到那种像一大包神秘零件(BLOB 类型数据)的数据,就把它拆开,按照 UTF - 8 编码规则整理成字节数组,再转成字符串。而且哦,如果这些数据太大了,超过了规定的字节数(由 jdbcsampler.max_retain_result_size 决定),那就没办法啦,只能截断,就像你要把一根太长的绳子截成合适的长度一样。虽然这种方式简单直接,但有时候可能会丢失一些数据的细节,不过在你只需要大概看看数据,或者数据量不大的时候,还是挺方便的。
- Store as Object(存储为对象)
- 把结果集类型的变量存成对象,这样你后面可以对它进行迭代访问。CLOB 的处理和 “Store as string” 一样,BLOB 就存成字节数组。同样,CLOB 和 BLOB 在达到一定字节数后会被截断。这就像你把从数据库拿到的数据小心翼翼地整理好,放在一个精致的盒子(对象)里,这样你之后就可以打开盒子,一件一件地查看里面的数据(迭代访问),是不是比直接堆在一起更有条理呢?比如你从数据库查询到了一些用户信息,存成对象后,你就可以逐个查看每个用户的详细信息,而不是像存储为字符串那样只能看到一堆乱糟糟的字符。这种方式对于需要对查询结果进行进一步处理和分析的情况非常有用,就像你要对用户信息进行统计分析,把数据存成对象会让你的操作更加方便快捷。
- Count Records(记录计数)
- 这种方式就是只把记录的数量显示出来,变量就存成字符串。要是 BLOB 类型的数据,就存它的大小。这就像你只关心图书馆有多少本书(记录数量),不关心书的具体内容,只把数量记下来就行,是不是很简洁明了呢?在一些场景下,比如你只是想知道某个查询返回了多少条数据,而不需要详细了解每条数据的具体内容,那么选择 “Count Records” 就可以快速得到你想要的信息,避免了处理大量不必要的数据,节省了时间和资源。比如说你要统计某个时间段内的订单数量,使用 “Count Records” 方式,数据库只需要返回一个数字,而不是把所有订单的详细信息都给你,这样能大大提高查询效率,让你更快地得到你需要的统计结果。
- 这种方式就是只把记录的数量显示出来,变量就存成字符串。要是 BLOB 类型的数据,就存它的大小。这就像你只关心图书馆有多少本书(记录数量),不关心书的具体内容,只把数量记下来就行,是不是很简洁明了呢?在一些场景下,比如你只是想知道某个查询返回了多少条数据,而不需要详细了解每条数据的具体内容,那么选择 “Count Records” 就可以快速得到你想要的信息,避免了处理大量不必要的数据,节省了时间和资源。比如说你要统计某个时间段内的订单数量,使用 “Count Records” 方式,数据库只需要返回一个数字,而不是把所有订单的详细信息都给你,这样能大大提高查询效率,让你更快地得到你需要的统计结果。
- Store as string(默认,存储为字符串)
- 这是在说数据库把数据给你之后,你要怎么处理这些数据。
五、实际应用场景教程
(一)电商系统的订单处理测试
- 场景描述
- 在电商系统中,订单处理是关键业务流程。用户下单后,订单信息需要插入数据库,包括用户 ID、商品 ID、购买数量、下单时间等。同时,库存数量需要相应减少,这涉及到数据库的更新操作。此外,用户可能会查询订单状态,这需要从数据库中获取订单的相关信息。
- 测试步骤
- 配置 JDBC 连接:按照前面所述的方法,配置好连接到电商数据库的连接池。例如,设置最大连接数为 50(考虑到电商系统在促销活动时的并发量较大,但也不能设置过高以免数据库服务器不堪重负),最大等待时间为 5000 毫秒,空闲时测试连接是否有效等参数,确保连接池的稳定和高效运行。
- 创建 JDBC 请求插入订单数据:
- 在 JDBC Request 采样器中,选择 “Update Statement” 作为查询类型,因为我们要插入新的订单数据。
- SQL Query 填写:“INSERT INTO orders (user_id, product_id, quantity, order_time) VALUES (?,?,?,?)”,这里的 “?” 是占位符,用于预编译 SQL 语句,提高性能和安全性。
- Parameter Values 填写:假设我们有用户 ID 为 1001,商品 ID 为 2001,购买数量为 2,下单时间为当前时间(可以通过 JMeter 的函数助手生成当前时间的合适格式,如 “{__time(yyyy-MM-dd HH:mm:ss)}”),则参数值填写为“1001,2001,2,{__time(yyyy-MM-dd HH:mm:ss)}”。
- Parameter Types 填写:“INTEGER,INTEGER,INTEGER,VARCHAR”,分别对应上述参数的类型。
- 创建 JDBC 请求更新库存数据:
- 同样选择 “Update Statement”,SQL Query 填写:“UPDATE products SET stock_quantity = stock_quantity -? WHERE product_id =?”,用于减少商品的库存数量。
- Parameter Values 填写:假设购买数量为 2,商品 ID 为 2001,则参数值填写 “2,2001”。
- Parameter Types 填写:“INTEGER,INTEGER”。
- 创建 JDBC 请求查询订单状态:
- 选择 “Prepared Select Statement”,SQL Query 填写:“SELECT order_status FROM orders WHERE order_id =?”,用于查询指定订单的状态。
- Parameter Values 填写:假设订单 ID 为 3001,则参数值填写 “3001”。
- Parameter Types 填写:“INTEGER”。
- 在 Variable Names 中填写 “orderStatus”,这样查询到的订单状态将存储在这个变量中,方便后续的断言或其他处理。
- 设置线程组和断言:
- 在测试计划中添加线程组,设置线程数为 20(模拟 20 个并发用户下单), ramp-up period 为 2 秒(让用户在 2 秒内逐渐开始下单,更符合实际情况),循环次数为 1(每个用户只下一次单)。
- 在查询订单状态的 JDBC 请求后添加响应断言,设置断言规则为检查返回的订单状态是否符合预期。例如,如果预期订单状态为 “已支付”,则在断言中设置 “要测试的模式” 为 “已支付”,模式匹配规则为 “包括”。这样,如果查询到的订单状态不是 “已支付”,则该请求将被标记为失败,方便我们快速发现订单处理过程中的问题。
- 运行测试并分析结果:
- 运行测试计划,JMeter 将模拟 20 个用户并发执行下单、更新库存和查询订单状态的操作。
- 通过查看聚合报告监听器,我们可以获取订单处理过程中的关键性能指标,如平均响应时间、吞吐量和错误率等。如果平均响应时间过长,可能意味着数据库查询或更新操作存在性能瓶颈,需要进一步优化 SQL 语句或数据库配置。如果错误率较高,可能是由于数据库连接问题、SQL 语句错误或业务逻辑处理不当等原因导致,需要仔细排查。
- 同时,查看查看结果树监听器,可以详细了解每个请求的响应情况,包括插入订单、更新库存和查询订单状态的结果。如果某个请求失败,可以通过查看其详细信息,如请求的参数、SQL 语句和响应数据,快速定位问题所在,进行针对性的修复。
(二)社交网络平台的动态发布与点赞测试
- 场景描述
- 在社交网络平台上,用户发布动态后,动态信息会插入数据库,包括用户 ID、动态内容、发布时间等。其他用户对动态进行点赞操作时,数据库中的点赞数需要相应更新。同时,用户可能会查询自己或他人的动态列表,以及查看动态的点赞数等信息。
- 测试步骤
- 配置 JDBC 连接:配置连接到社交网络数据库的连接池,根据平台的用户规模和活跃度,合理设置最大连接数、最大等待时间等参数。例如,对于一个中等规模的社交网络平台,最大连接数可设置为 30,最大等待时间为 3000 毫秒,确保连接池能够满足日常并发操作的需求,同时又不会过度消耗数据库资源。
- 创建 JDBC 请求发布动态:
- 选择 “Update Statement” 作为查询类型,SQL Query 填写:“INSERT INTO posts (user_id, post_content, post_time) VALUES (?,?,?)”。
- Parameter Values 填写:假设用户 ID 为 5001,动态内容为 “今天天气真好,出去散步啦!”,发布时间为当前时间(“{__time(yyyy-MM-dd HH:mm:ss)}”),则参数值填写“5001,今天天气真好,出去散步啦!,{__time(yyyy-MM-dd HH:mm:ss)}”。
- Parameter Types 填写:“INTEGER,VARCHAR,VARCHAR”。
- 创建 JDBC 请求点赞动态:
- 选择 “Update Statement”,SQL Query 填写:“UPDATE posts SET like_count = like_count + 1 WHERE post_id =?”,用于增加动态的点赞数。
- Parameter Values 填写:假设要点赞的动态 ID 为 4001,则参数值填写 “4001”。
- Parameter Types 填写:“INTEGER”。
- 创建 JDBC 请求查询动态列表:
- 选择 “Prepared Select Statement”,SQL Query 填写:“SELECT post_id, post_content, like_count FROM posts WHERE user_id =?”,用于查询指定用户的动态列表及点赞数。
- Parameter Values 填写:假设查询用户 ID 为 5001,则参数值填写 “5001”。
- Parameter Types 填写:“INTEGER”。
- 在 Variable Names 中填写 “postId,postContent,likeCount”,以便将查询到的动态 ID、内容和点赞数分别存储在这些变量中,方便后续的处理和断言。
- 设置线程组和断言:
- 在测试计划中添加线程组,设置线程数为 15(模拟 15 个用户并发发布动态和点赞),ramp-up period 为 3 秒,循环次数为 2(每个用户发布 2 条动态并进行点赞操作)。
- 在查询动态列表的 JDBC 请求后添加响应断言,设置断言规则为检查返回的动态列表是否符合预期。例如,断言返回的动态数量是否正确,以及动态内容和点赞数是否在合理范围内。如果实际返回的动态数量与预期不符,或者点赞数出现异常,如负数或过大的数值,断言将失败,提示我们可能存在数据库数据更新不一致或查询逻辑错误等问题。
- 运行测试并分析结果:
- 运行测试计划,JMeter 将模拟 15 个用户的并发操作,包括发布动态、点赞和查询动态列表。
- 通过聚合报告监听器查看性能指标,如平均响应时间、吞吐量和错误率等。如果点赞操作的响应时间过长,可能是由于频繁更新数据库导致的性能问题,需要考虑优化数据库的更新策略,如批量更新或使用缓存机制等。如果查询动态列表的错误率较高,可能是由于查询语句复杂或数据库索引设置不合理,需要进一步分析和优化。
- 查看查看结果树监听器,详细检查每个请求的响应情况,对于出现问题的请求,根据其详细信息进行排查和修复,确保社交网络平台的动态发布和点赞功能正常运行,同时保证数据库操作的准确性和高效性。
(三)在线教育系统的课程管理测试
- 场景描述
- 在在线教育系统中,教师可以创建课程,课程信息包括课程名称、教师 ID、课程简介、创建时间等,这些信息会插入数据库。学生可以选修课程,选修操作会更新数据库中的选课记录和课程的选修人数。同时,学生和教师可能会查询课程的详细信息、选修情况等。
- 测试步骤
- 配置 JDBC 连接:针对在线教育系统的数据库,配置合适的连接池参数。例如,根据系统的用户数量和并发选课的高峰情况,将最大连接数设置为 40,最大等待时间为 4000 毫秒,确保在高并发选课期间数据库连接的稳定和高效。
- 创建 JDBC 请求创建课程:
- 选择 “Update Statement”,SQL Query 填写:“INSERT INTO courses (course_name, teacher_id, course_description, create_time) VALUES (?,?,?,?)”。
- Parameter Values 填写:假设课程名称为 “Java 编程基础课程”,教师 ID 为 6001,课程简介为 “这是一门适合初学者的 Java 编程课程”,创建时间为当前时间(“{__time(yyyy-MM-dd HH:mm:ss)}”),则参数值填写“Java 编程基础课程,6001,这是一门适合初学者的 Java 编程课程,{__time(yyyy-MM-dd HH:mm:ss)}”。
- Parameter Types 填写:“VARCHAR,INTEGER,VARCHAR,VARCHAR”。
- 创建 JDBC 请求学生选课:
- 选择 “Update Statement”,SQL Query 填写:“INSERT INTO student_course (student_id, course_id) VALUES (?,?)”,用于插入学生选课记录。
- Parameter Values 填写:假设学生 ID 为 7001,课程 ID 为 5001,则参数值填写 “7001,5001”。
- Parameter Types 填写:“INTEGER,INTEGER”。
- 同时,还需要更新课程的选修人数,再添加一个 “Update Statement” 请求:SQL Query 填写:“UPDATE courses SET enrollment_count = enrollment_count + 1 WHERE course_id =?”,参数 Values 填写 “5001”,Parameter Types 填写 “INTEGER”。
- 创建 JDBC 请求查询课程信息:
- 选择 “Prepared Select Statement”,SQL Query 填写:“SELECT course_name, teacher_id, enrollment_count FROM courses WHERE course_id =?”,用于查询指定课程的名称、教师 ID 和选修人数。
- Parameter Values 填写:假设查询课程 ID 为 5001,则参数值填写 “5001”。
- Parameter Types 填写:“INTEGER”。
- 在 Variable Names 中填写 “courseName,teacherId,enrollmentCount”,以便存储查询结果。
- 设置线程组和断言:
- 在测试计划中添加线程组,设置线程数为 25(模拟 25 个学生并发选课和查询课程信息),ramp-up period 为 5 秒,循环次数为 3(每个学生选修 3 门课程并查询课程信息)。
- 在查询课程信息的 JDBC 请求后添加响应断言,检查返回的课程信息是否准确。例如,断言课程名称是否正确,教师 ID 是否匹配,选修人数是否随着学生选课操作而正确增加。如果选修人数没有正确更新,或者课程信息与预期不符,断言将失败,提示我们数据库操作可能存在问题,需要进一步检查插入选课记录和更新选修人数的 SQL 语句逻辑。
- 运行测试并分析结果:
- 运行测试计划,模拟学生的选课和查询课程信息操作。
- 通过聚合报告监听器查看性能数据,如平均响应时间、吞吐量和错误率等。如果选课操作的响应时间过长,可能需要优化选课相关的数据库操作,如优化插入语句或考虑使用事务来保证数据的一致性和完整性。如果查询课程信息的错误率较高,可能需要检查查询语句的准确性和数据库索引的设置。
- 查看查看结果树监听器,对每个请求的详细响应进行分析,针对出现问题的请求进行排查和修复,确保在线教育系统的课程管理功能正常运行,数据库数据的准确性和一致性得到保障。
通过以上实际应用场景的教程,宝子们应该对如何在实际工作中使用 JMeter 的 JDBC 请求有了更直观的理解和掌握。在不同的业务场景中,根据具体的需求灵活配置 JDBC 请求的参数,并结合线程组、断言和监听器等组件,能够有效地对数据库驱动的应用程序进行功能测试和性能优化,及时发现并解决潜在的问题,提高系统的稳定性和可靠性。别着急,后面还有更厉害的技巧等着咱们去探索,继续往下看吧!