【GreatSQL优化器-08】statistics和index dives
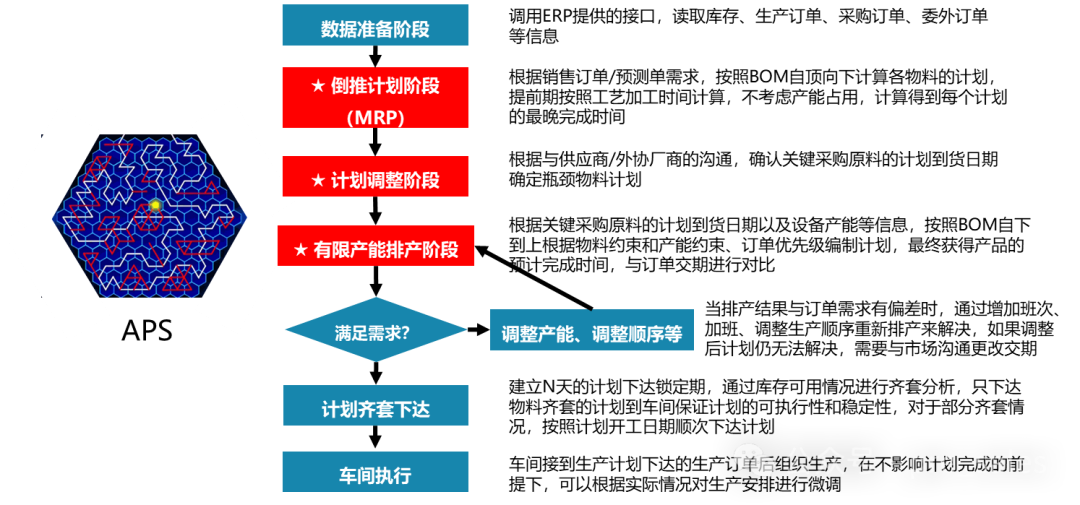
一、statistics和index_dives介绍
GreatSQL的优化器对于查询条件带有范围的情况,需要根据 mm tree 来估计该范围内大概有多少行,然后以此来计算cost。对于等号条件,给出了两种方法来估计对应行数--Statistics和index dives,前者不精确后者精确,可以通过系统变量eq_range_index_dive_limit设置阈值来决定用哪种方法来估计等号条件的行数。对于一条查询 SQL 如果等号条件太多的时候执行index dives会占用较多资源,这时候设置一个合理的阈值改为统计值估计可以有效避免占用过多资源,提升执行效率。
| 名称 | 定义 | 说明 |
|---|---|---|
| Statistics | 用统计值来估计等号条件的行数,不精确 | 意味着SKIP_RECORDS_IN_RANGE模式,计算方式: rows = table->key_info[keyno].records_per_key() |
| index dives | 精确计算等号条件的行数 | 意味着RECORDS_IN_RANGE,计算方式: rows = this->records_in_range() |
下面用一个简单的例子来说明index dives是什么:
greatsql> CREATE TABLE t1 (c1 INT PRIMARY KEY, c2 INT,date1 DATETIME);
greatsql> INSERT INTO t1 VALUES (1,10,'2021-03-25 16:44:00.123456'),(2,1,'2022-03-26 16:44:00.123456'),(3,4,'2023-03-27 16:44:00.123456'),(5,5,'2024-03-25 16:44:00.123456'),(7,null,'2020-03-25 16:44:00.123456'),(8,10,'2020-10-25 16:44:00.123456'),(11,16,'2023-03-25 16:44:00.123456');
greatsql> CREATE TABLE t2 (cc1 INT PRIMARY KEY, cc2 INT);
greatsql> INSERT INTO t2 VALUES (1,3),(2,1),(3,2),(4,3),(5,15);
greatsql> CREATE TABLE t3 (ccc1 INT, ccc2 varchar(100));
greatsql> INSERT INTO t3 VALUES (1,'aa1'),(2,'bb1'),(3,'cc1'),(4,'dd1'),(null,'ee');
greatsql> CREATE INDEX idx1 ON t1(c2);
greatsql> CREATE INDEX idx2 ON t1(c2,date1);
greatsql> CREATE INDEX idx2_1 ON t2(cc2);
greatsql> CREATE INDEX idx3_1 ON t3(ccc1);greatsql> SELECT * FROM t1 WHERE (c1=4 AND c2<10) OR (c2=4 AND c1<9) OR (c2=10 AND c1<9) OR (c2=12 AND c1=8) OR (c2<8 AND date1<'2023-03-25 16:44:00.123456') OR (c2<15 AND date1<'2023-03-25 16:44:00.123456');"analyzing_range_alternatives": {"range_scan_alternatives": [{"index": "idx1","ranges": ["NULL < c2 < 8","8 <= c2 < 10","c2 = 10","10 < c2 < 12","c2 = 12","12 < c2 < 15"],"index_dives_for_eq_ranges": true,"rowid_ordered": false,"using_mrr": false,"index_only": false,"in_memory": 1,"rows": 9, # 这里的值包含c2 = 10和c2 = 12根据index dive估算出来的值"cost": 4.66,"chosen": false,"cause": "cost"},{"index": "idx2","ranges": ["NULL < c2 < 4","c2 = 4","4 < c2 < 8","8 <= c2 < 10","c2 = 10","10 < c2 < 12","c2 = 12","12 < c2 < 15"],"index_dives_for_eq_ranges": true,"rowid_ordered": false,"using_mrr": false,"index_only": true,"in_memory": 1,"rows": 9, # 这里的值包含c2 = 10和c2 = 12根据index dive估算出来的值"cost": 1.16366,"chosen": false,"cause": "cost"}],}}}
上面的二叉树转置结果如下,按照左节点到最右节点来累计总行数。
idx1索引的结果:count=28<c2<10黑/ \0<c2<8红 c2=10\10<c2<12\c2=12\12<c2<15idx2索引的结果:count=3c2=4黑 / \0<c2<4红 4<c2<8\8<c2<10\c2=10\10<c2<12\c2=12 \12<c2<15
# 注:count表示c2等号条件的数量
二、test_quick_select代码解释
范围扫描计算行数和 cost 在test_quick_select函数实现,用来预估不同范围对应的行数和 cost,最后选取适合的 index 来进行查询。
# 代码流程:make_join_plan --> estimate_rowcount --> get_quick_record_count --> check_skip_records_in_range_qualification -> test_quick_select -> get_key_scans_params -> check_quick_selectint test_quick_select() {if (cond)tree = get_mm_tree(); # 这里创建mm treeif (tree) {Opt_trace_object trace_range_alt(trace, "analyzing_range_alternatives",Opt_trace_context::RANGE_OPTIMIZER);AccessPath *range_path = get_key_scans_params(thd, ¶m, tree, false, true, interesting_order,skip_records_in_range, best_cost, needed_reg);/* Get best 'range' plan and prepare data for making other plans */if (range_path) {best_path = range_path; # 行数信息在这里面best_cost = best_path->cost; # cost信息在这里面}}
}AccessPath *get_key_scans_params() {for (idx = 0; idx < param->keys; idx++) {// 主要计算下面2个参数的值,found_records是找到的行数,另一个就是costha_rows found_records;Cost_estimate cost;found_records = check_quick_select(thd, param, idx, read_index_only, key, update_tbl_stats,order_direction, skip_records_in_range, &mrr_flags, &buf_size, &cost,&is_ror_scan, &is_imerge_scan);}
}ha_rows check_quick_select() {# eq_ranges_exceeds_limit函数统计等号条件的行数,返回countparam->use_index_statistics = eq_ranges_exceeds_limit(tree, &range_count, thd->variables.eq_range_index_dive_limit);# 以下这行代码没用,是冗余代码*bufsize = thd->variables.read_rnd_buff_size;# multi_range_read_info_const函数累加找到的范围内的总行数,并且计算出所有rows对应的costrows = file->multi_range_read_info_const(keynr, &seq_if, (void *)&seq, 0,bufsize, mrr_flags, cost);# 设置quick_condition_rows用于后面best_access_path时候计算costparam->table->quick_condition_rows =min(param->table->quick_condition_rows, rows);
}ha_rows handler::multi_range_read_info_const() {if(SKIP_RECORDS_IN_RANGE)rows = table->key_info[keyno].records_per_key() # 对于SKIP_RECORDS_IN_RANGE模式,用records_per_key估计行数elserows = this->records_in_range() # 对于非SKIP_RECORDS_IN_RANGE模式,用records_in_range估计行数
}# 对于innodb计算范围内行数的时候,如果没有找到值那么就返回1
ha_rows ha_innobase::records_in_range() {if (n_rows == 0) {n_rows = 1;}
}
表一,skip_records_in_range为true的场景,意味着index dive可以被跳过,改为Statistics估计row和cost
| 场景 | 条件 |
|---|---|
| check_skip_records_in_range_qualification() (右边全都要满足) | 单表查询 |
| FORCE INDEX单个索引 | |
| 没有子查询 | |
| 不涉及Fulltext Index | |
| 没有GROUP-BY或者DISTINCT语句 | |
| 没有ORDER-BY语句 | |
| 不是EXPLAIN查询语句 | |
| param->use_index_statistics | 值为true的时候 |
注:skip_records_in_range的值由check_skip_records_in_range_qualification函数决定,具体可以看该函数
表二,param->use_index_statistics值
| thd->variables.eq_range_index_dive_limit | use_index_statistics | 说明 |
|---|---|---|
| 0 | false | 不用Statistics代替index dives |
| 1 | true | 用Statistics代替index dives |
| 其他值(默认200) :count>=limit | true | 用Statistics代替index dives |
| 其他值(默认200) :count<limit | false | 不用Statistics代替index dives |
注:count 是指mm二叉树里面等号的数量
三、实际例子说明
接下来看几个例子来说明上面的代码:
greatsql> SELECT * FROM t1 WHERE (c1=4 AND c2<10) OR (c2=4 AND c1<9) OR (c2=10 AND c1<9) OR (c2=12 AND c1=8) OR (c2<8 AND date1<'2023-03-25 16:44:00.123456') OR (c2<15 AND date1<'2023-03-25 16:44:00.123456');
场景一,eq_range_index_dive_limit=200,skip_records_in_range=false
"analyzing_range_alternatives": {"range_scan_alternatives": [{"index": "idx1","ranges": ["NULL < c2 < 8","8 <= c2 < 10","c2 = 10","10 < c2 < 12","c2 = 12","12 < c2 < 15"],"index_dives_for_eq_ranges": true,"rowid_ordered": false,"using_mrr": false,"index_only": false,"in_memory": 1,"rows": 9, # 按照上面的范围计算:3+1+2+1+1+1,这里找到的结果是0行的话也会返回1"cost": 4.66,"chosen": false,"cause": "cost"},{"index": "idx2","ranges": ["NULL < c2 < 4","c2 = 4","4 < c2 < 8","8 <= c2 < 10","c2 = 10","10 < c2 < 12","c2 = 12","12 < c2 < 15"],"index_dives_for_eq_ranges": true,"rowid_ordered": false,"using_mrr": false,"index_only": true,"in_memory": 1,"rows": 9, # 按照上面的范围计算:3+1+2+1+1+1,这里找到的结果是0行的话也会返回1"cost": 1.16366,"chosen": false,"cause": "cost"}],}}}
场景二,eq_range_index_dive_limit=3,skip_records_in_range=true or false
greatsql> SET eq_range_index_dive_limit=3;"analyzing_range_alternatives": {"range_scan_alternatives": [{"index": "idx1","ranges": ["NULL < c2 < 8","8 <= c2 < 10","c2 = 10","10 < c2 < 12","c2 = 12","12 < c2 < 15"],"index_dives_for_eq_ranges": true,"rowid_ordered": false,"using_mrr": false,"index_only": false,"in_memory": 1,"rows": 9, # 这里等号数量为2个,数量没有超过3个,因此还是用原来的index dive计算方法,公式:3+1+2+1+1+1"cost": 4.66,"chosen": false,"cause": "cost"},{"index": "idx2","ranges": ["NULL < c2 < 4","c2 = 4","4 < c2 < 8","8 <= c2 < 10","c2 = 10","10 < c2 < 12","c2 = 12","12 < c2 < 15"],"index_dives_for_eq_ranges": false,"rowid_ordered": false,"using_mrr": false,"index_only": true,"in_memory": 1,"rows": 8, # 这里等号数量为3个,等于eq_range_index_dive_limit,因此用statistics方法来统计行数,公式:3+1+1+1+1+1"cost": 1.0632,"chosen": false,"cause": "cost"}],
场景三,eq_range_index_dive_limit=2,skip_records_in_range=true
greatsql> SET eq_range_index_dive_limit=2;"analyzing_range_alternatives": {"range_scan_alternatives": [{"index": "idx1","ranges": ["NULL < c2 < 8","8 <= c2 < 10","c2 = 10","10 < c2 < 12","c2 = 12","12 < c2 < 15"],"index_dives_for_eq_ranges": false,"rowid_ordered": false,"using_mrr": false,"index_only": false,"in_memory": 1,"rows": 8, # 这里等号数量为2个,等于eq_range_index_dive_limit,因此用statistics方法来统计行数,公式:3+1+1+1+1+1"cost": 4.31,"chosen": false,"cause": "cost"},{"index": "idx2","ranges": ["NULL < c2 < 4","c2 = 4","4 < c2 < 8","8 <= c2 < 10","c2 = 10","10 < c2 < 12","c2 = 12","12 < c2 < 15"],"index_dives_for_eq_ranges": false,"rowid_ordered": false,"using_mrr": false,"index_only": true,"in_memory": 1,"rows": 8, # 这里等号数量为3个,等于eq_range_index_dive_limit,因此用statistics方法来统计行数,公式:3+1+1+1+1+1"cost": 1.0632,"chosen": false,"cause": "cost"}],
上面结果总结如下,可以看出 index dive 对于等号计算精确,而 statistics 方法计算等号条件是不精确的。也可以看出优化器预估范围行数肯定是比实际值大于或者等于的。
| eq_range_index_dive_limit | NULL < c2 < 8 | 8 <= c2 < 10 | c2 = 10 | 10 < c2 < 12 | c2 = 12 | 12 < c2 < 15 | 总计 | |
|---|---|---|---|---|---|---|---|---|
| 实际分布 | 3 | 0 | 2 | 0 | 0 | 0 | 5 | |
| 场景一 | 200 | 3 | 1 | 2 | 1 | 1 | 1 | 9 |
| 场景二 | 3 | 3 | 1 | 2 | 1 | 1 | 1 | 9 |
| 场景三 | 2 | 3 | 1 | 1 | 1 | 1 | 1 | 8 |
注:index dive只针对等号条件进行精确计数
四、总结
从上面我们认识了对于带有条件的查询语句,对等号条件有两种预估行数方法,认识了他们的区别以及使用方法。对于系统变量eq_range_index_dive_limit的设置也有了一个比较好的认识。在以后的使用中,对于等号条件太多的情况,可以通过设置eq_range_index_dive_limit阈值来控制等号条件估计行数的行为。
考考你:如果上面例子的eq_range_index_dive_limit设为1的话,估计结果是多少行?欢迎下方留言评论~
Enjoy GreatSQL 😃
关于 GreatSQL
GreatSQL是适用于金融级应用的国内自主开源数据库,具备高性能、高可靠、高易用性、高安全等多个核心特性,可以作为MySQL或Percona Server的可选替换,用于线上生产环境,且完全免费并兼容MySQL或Percona Server。
相关链接: GreatSQL社区 Gitee GitHub Bilibili
GreatSQL社区:
社区博客有奖征稿详情:https://greatsql.cn/thread-100-1-1.html

技术交流群:
微信:扫码添加
GreatSQL社区助手微信好友,发送验证信息加群。