0. 前记
创建这个随笔的想法其实也很简单,这个学期因为有一些课程需要线下上课所以回学校上了AI实践的课程,然后做了几个比较简单的AI实践项目,同时感觉有的项目还挺有意思,就记录一下。比较有代表性,之后有需要的话大概可以通过这篇随笔来简要回顾自己当时的一个做的策略。
为了简要起见,这里就不谈原理只聊应用,聊原理需要花太久的时间去推公式测正伪了,只是应用的话会快一些。(什么调库达人2333
主要包括四个实验:人脸识别、Clip图文对应、Aircraft数据挖掘分析、SAM图像分割。
这其中的可视化界面主要都是基于Tkinter实现的,而实现的平台有Win有Linux,具体到实验上会提一句比较关键的配置。
1. Face_recognition
(发现这个图的测试效果涉及到了拍照,保护隐私起见还是不放互联网上了)
这个实验主要做的是基于python中的Dlib库完成对人脸识别。主要包括三个部分:人脸特征点识别与标准匹配、前端UI呈现、机器学习的分类训练。这个过程我们当时还设计了两种,分别是静态识别和动态识别,静态识别就是上传照片进行匹配,动态识别就是调用摄像头权限然后对拍摄的内容进行分析。相应的,我们就肯定需要包括上传数据、更新数据等方式在内的一些辅助方法。
人脸特征点识别
这个实际上直接调用Dlib库的compute_face_descriptor等方法就可以,把特征点应用于静态图像中的点上,对于动态图像就抽帧获取当前帧后再进行处理。
同时还有一个检测活体的方法,当我们需要启用实时识别时,肯定是不能让用户拿着一张人脸的照片就可以糊弄过去的,所以需要整一个活体检测。这个活体检测的思路大家也见仁见智,因为Dlib的模型特征点包括每个眼睛的上下特征点,所以我们就把眨眼这个过程来作为判断活体的依据了,需要眨眼两三次,我们才可以确定是一个活人,虽然在某种程度上还是可以伪造通过,不过就普遍实用角度来说问题也不大。
def process_face_recognition(self, image, faces):# 进行人脸识别gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)descriptors = []labels = []# 保存匹配到的人脸区域xx = []yy = []for face in faces:shape = predictor(gray, face)face_descriptor = self.model.compute_face_descriptor(image, shape)descriptors.append(np.array(face_descriptor))labels.append(self.get_label(face))# print(len(faces))match_found = Falsefor input_descriptor, face in zip(descriptors, faces):x, y, w, h = (face.left(), face.top(), face.width(), face.height())xx.append(x)xx.append(x+w)yy.append(y)yy.append(y+h)min_d = 0.5res = 0for id, db_descriptors in self.face_database.items():distance = compare_faces(input_descriptor, np.mean(db_descriptors, axis=0))if distance:if(distance < min_d):min_d = distanceres = idif res: # 在图像上绘制匹配的人脸框cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)text = f"ID: {res}"cv2.putText(image, text, (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)match_found = Trueelse:# 没有匹配到,显示红色框cv2.rectangle(image, (x, y), (x + w, y + h), (0, 0, 255), 2)text = "Not Found!"cv2.putText(image, text, (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 0, 255), 2)self.display_image(image)self.status_label.config(text="状态:识别完成" if match_found else "状态:未匹配到人脸")self.stop_recognizing()# 显示识别结果self.display_result(image[int(min(yy)*0.75):int(max(yy)*1.25), int(min(xx)*0.75):int(max(xx)*1.25)])self.show_update_button()
UI制作
UI制作说实话我并不是很擅长,所以还是受了很多伙伴的帮助。采用tkinter的方法构建的话,我们就初始构建一个类,然后规划好大的功能包括哪几个部分(静态识别、动态识别、添加人脸),然后通过点击按钮与可视化呈现的方法来完成。需要注意的是,这里的可视化呈现需要有一个格式转换的过程,我们是采用PIL.Image和ImageTk的方法来做的。Tkinter比较简单可以这么做,但是如果涉及到streamlit或者web,html之类的,那种的话一般就构建整个系统了,也就不是从一个类的角度可以完整搭建解释清楚的事了。
def display_result(self, face_image):face_rgb = cv2.cvtColor(face_image, cv2.COLOR_BGR2RGB)max_width = 160 max_height = 160 original_width, original_height = face_rgb.shape[1], face_rgb.shape[0]if original_width > original_height:new_width = max_widthnew_height = int(original_height * max_width / original_width)else:new_height = max_heightnew_width = int(original_width * max_height / original_height)face_pil = Image.fromarray(face_rgb)# face_resized = face_pil.resize((new_width, new_height), Image.ANTIALIAS)face_resized = face_pil.resize((new_width, new_height), Image.LANCZOS)self.result_image = face_resizedface_tk = ImageTk.PhotoImage(face_resized)if self.result_image_label:self.result_image_label.config(image=face_tk)self.result_image_label.image = face_tkelse:self.result_image_label = tk.Label(self, image=face_tk)self.result_image_label.image = face_tkself.result_image_label.pack(pady=10)
机器学习人脸特征点
这个我做的效果不太好,可能是因为数据量的原因,也没有大量的数据训练,就简单从十几张人脸数据以及Dlib的特征点信息训练的,采用的是SVM最简单的分类模型。虽然效果不是很好,但是多少都算有点效果,如果应用的话,在后面数据量上来之后可能会有不错的效果。这一部分的识别代码在第一块人脸识别那里就是做了更改,就是SVC的那里。
如果采用SVC:
def process_face_recognition(self, image, faces):gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)descriptors = []labels = []# 保存匹配到的人脸区域xx = []yy = []for face in faces:shape = predictor(gray, face)face_descriptor = self.model.compute_face_descriptor(image, shape)descriptors.append(np.array(face_descriptor))labels.append(self.get_label(face))# print(len(faces))match_found = Falsele = LabelEncoder()integer_encoded = le.fit_transform(labels)self.classes = le.classes_model = SVC(kernel='linear', probability=True)model.fit(descriptors, integer_encoded)predictions = model.predict(descriptors)for i, face in enumerate(faces):x, y, w, h = (face.left(), face.top(), face.width(), face.height())label = self.classes[predictions[i]]cv2.rectangle(image, (x, y), (x + w, y + h), (0, 255, 0), 2)cv2.putText(image, label, (x, y - 10), cv2.FONT_HERSHEY_SIMPLEX, 0.5, (0, 255, 0), 2)self.display_image(image)self.status_label.config(text="状态:识别完成" if match_found else "状态:未匹配到人脸")self.stop_recognizing()# 显示识别结果self.display_result(image[int(min(yy)*0.75):int(max(yy)*1.25), int(min(xx)*0.75):int(max(xx)*1.25)])self.show_update_button()
2. Clip文字识别分类
效果如下:

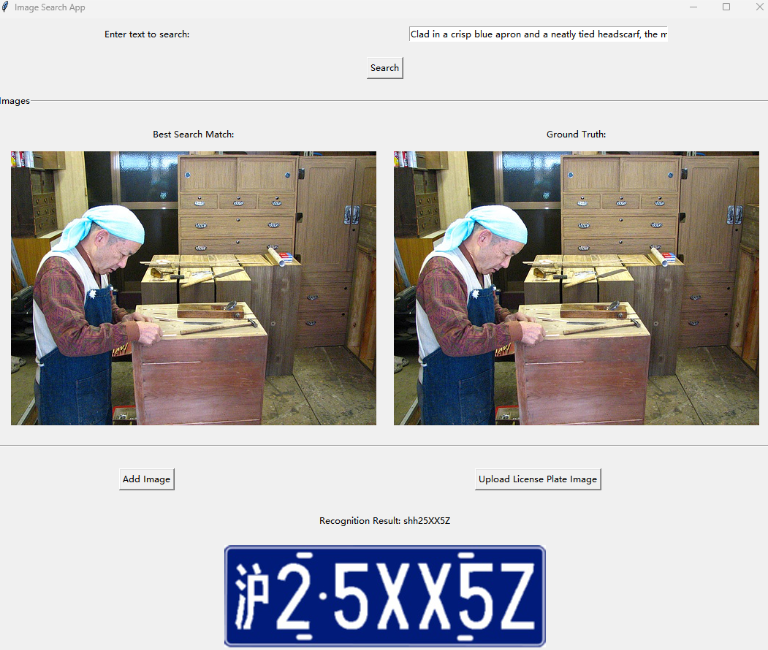
CLIP模型应该都很熟悉,就是文字,图片这两者的对应关系以及多模态这个方面的工作。这个我们也做了根据CLIP的车牌识别的工作。主要的点就是使用预训练模型来完成工作的。程序主要内容包括加载相应的文本信息,提取关键词,根据关键词重构文本信息(因为原文本可能过长从而导致不对齐以及无法继续运算的问题),提取图像特征,选取最佳匹配(这里还是通过循环找最优匹配做的,比较naive)。
图像文本识别
这个地方主要的就是根据输入文本来匹配图像,其中ground_truth这个只是为了方便查看正确与否设置的,是根据测试集单独设置的,而并非是人根据文本自己选。
最优匹配是根据向量的余弦相似度算的,越优即代表两个方向越贴近一致。
ef select_best_match(captions, image_features_list, model, preprocess, device, keywords_list, image_paths):best_matches = []for caption, keywords in zip(captions, keywords_list):# Ensure the caption is within the allowed token lengthcaption_text = caption['caption'].strip()text_token = clip.tokenize([caption_text], truncate=True).to(device)text_features = model.encode_text(text_token)text_features /= text_features.norm(dim=-1, keepdim=True)best_match_index = Nonehighest_similarity = 0for i, image_features in enumerate(image_features_list):image_features_torch = image_featuresimage_features_torch /= image_features_torch.norm(dim=-1, keepdim=True)similarity = (image_features_torch @ text_features.T)similarity_value = similarity[0][0].item()if similarity_value > highest_similarity:highest_similarity = similarity_valuebest_match_index = iif best_match_index is not None:best_match = image_paths[best_match_index]keywords_string = ""for keyword in keywords:keywords_string = keywords_string + keyword + ", "keywords_string = keywords_string[:-2]best_matches.append({'caption': caption['caption'], 'keywords': keywords_string, 'image': best_match[20:]})return best_matches
车牌识别
整体过程大差不差,主要多一步考虑的可能就是需要对图像进行处理然后分割出每个车牌符号的位置,然后分别进行特征识别最后再判断。
车牌识别效果:
3. 数据分析与处理
这个实验主要是以二战空袭数据作为例子的,主要内容大致有:数据清洗与可视化、ARIMA模型的时间序列预测模型。
数据清洗与可视化
其中数据清洗这一部分还是有不少地方需要注意的,比如在处理数据的时候不应该只是关注NaN值等“不寻常”值,对于“不正确值”和“用户分析不需要值”也是需要关注清洗的。比如经纬度达到1000多度,那肯定是不需要的需要删掉,比如用户只需要某个时间段的数据,那就需要根据时间段做好筛选。
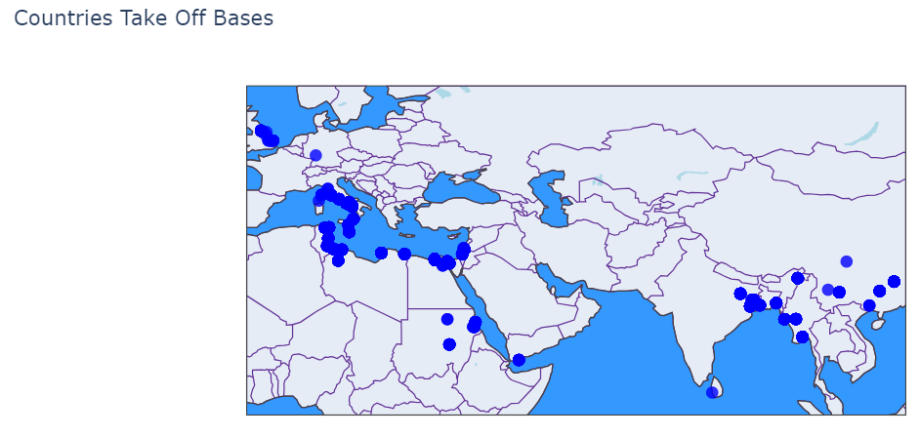
可视化这里我们分为了传统可视化和基于地理信息的可视化,基于地理信息的可视化主要是采用plotly.graph_objs这个库来作为方法从而进行下一步可视化的,可以展示一下效果:
ARIMA
ARIMA模型效果挺一般,但是从PACF和ACF推出来的p和q值的选取应该也没问题,那总不会是d值的差分有问题()。估计应该是数据不太准确或者量不太够,一半预测一半可能训练的量不太行,需要多一点训练集。
PACF和ACF选取ARIMA的参数p, q值:
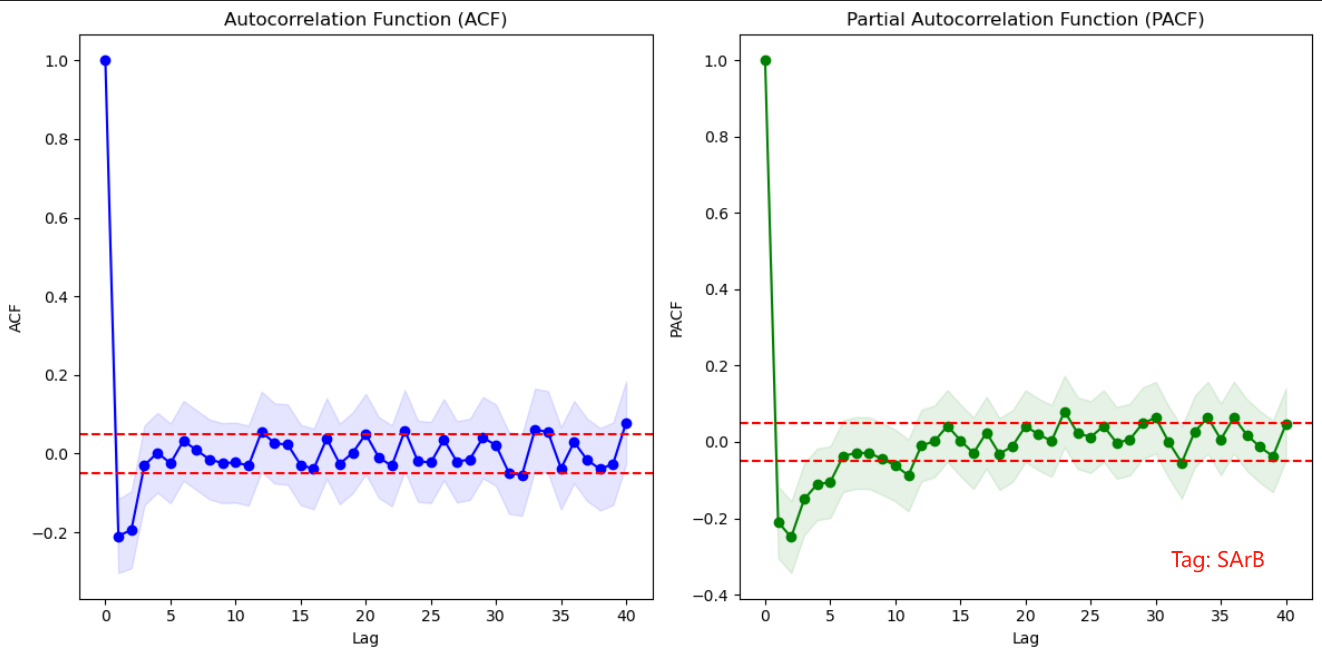
ARIMA模型预测效果:

4. SAM图像分割模型
这个和第二个实验一样,都是调用预训练模型来处理的。SAM主要包括两个实验部分:对图像分割与交互式标注,分类的机器学习。
这其中也夹杂了一个内容:如何将交互式标注的信息保存到文件中并可以被后续的分类机器学习方法利用。这里我采用的是json文件的格式进行保存,也方便后续进行交互。
图像分割与交互式标注
这里还是用的Tkinter,不过难点在于交互式图像分割。用户不知道哪些区域分割的情况的话就不容易做标注来标记特殊区域,如果已经预先统一设置颜色高亮之后的话又不好查看之前的原图效果,所以我就把分割效果单独高亮之后放到了右侧,用其比对着来对左侧的原图进行分割与交互式标记操作,当然肯定也包括取消高亮等手段。对于新的图片的处理的话,就需要新"Select"一张图片进行处理;需要保存标注信息的话,点击"Save"就可以将信息储存到标记的json文件之中了。
代码的话,放一些关于鼠标点击的交互式标注的代码吧:
def on_click(event):global labels, original_width, original_height, mask_original, original_image_np, selected_regionsx, y = event.x, event.yx_original = int((x / 600) * original_width)y_original = int((y / 600) * original_height)selected_label = mask_original[y_original, x_original]if selected_label in labels:if selected_label in selected_regions:del selected_regions[selected_label]print(f"Label {selected_label} removed from selection.")else:selected_regions[selected_label] = label_colors[selected_label]print(f"Label {selected_label} selected.")combine_overlays()else:choice = messagebox.askyesno("Label Choice", "Do you want to create a new label? (No to join an existing label)")if choice:while True:label_type = simpledialog.askstring("Input", "Enter the label type (e.g., building, rice field, square):")if not label_type:returnif label_type in labels.values():messagebox.showwarning("Warning", f"Label '{label_type}' already exists. Please enter a unique label name.")else:breaklabels[selected_label] = label_typelabel_colors[selected_label] = get_random_color()selected_regions[selected_label] = label_colors[selected_label]print(f"Label {selected_label} added with type {label_type}.")dict_region[str(selected_label)] = label_typecombine_overlays()update_label_list()else:existing_labels = list(labels.values())if not existing_labels:messagebox.showinfo("Info", "No existing labels to join.")return# 选择一个现有标签selected_label_type = simpledialog.askstring("Select Label", f"Choose an existing label to join:\n{', '.join(existing_labels)}")if selected_label_type in labels.values():# 找到对应的 label_idtarget_label_id = next(key for key, value in labels.items() if value == selected_label_type)mask_original[mask_original == selected_label] = target_label_idlabels[target_label_id] = selected_label_typelabel_colors[target_label_id] = label_colors.get(target_label_id, get_random_color())print(f"Region {selected_label} joined to label {target_label_id}.")dict_region[str(selected_label)] = selected_label_typecombine_overlays()update_label_list()else:messagebox.showinfo("Info", "Invalid label selected.")
效果如下:
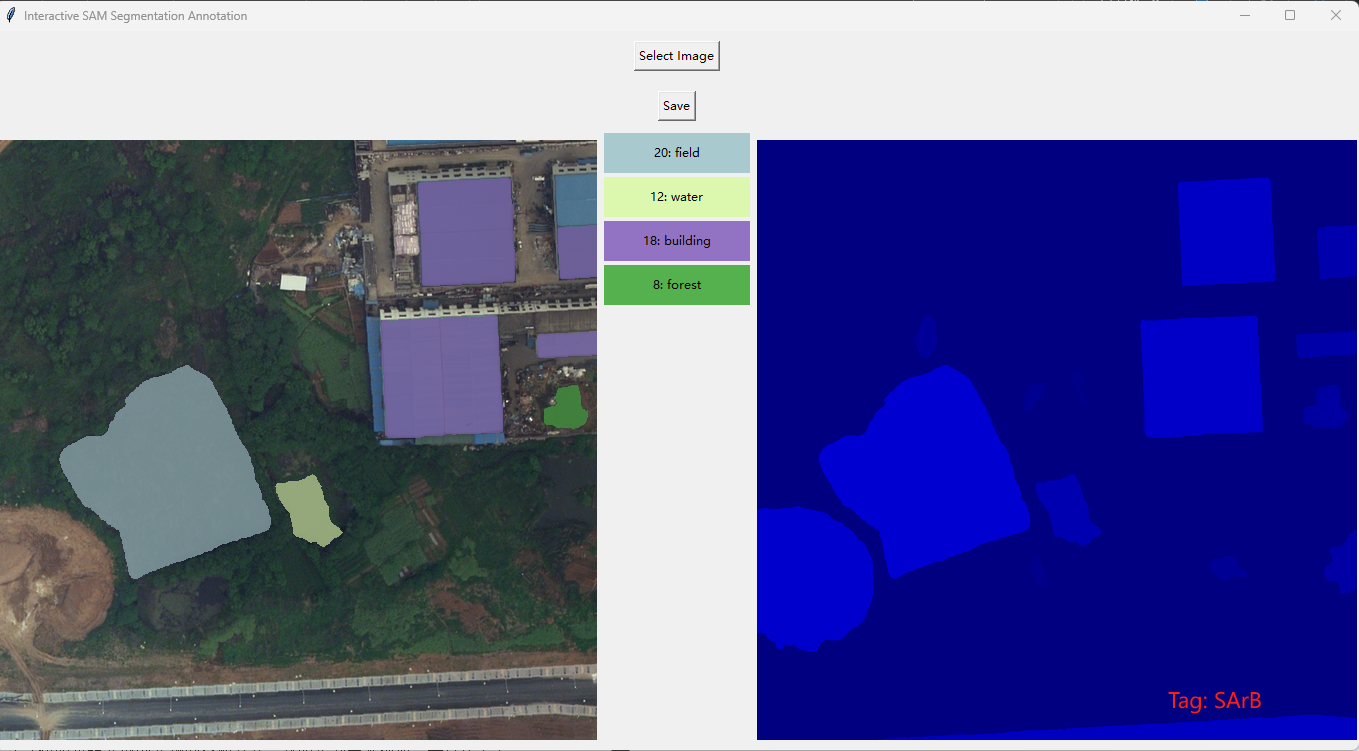
分类
这里的分类就是根据标注信息然后划分训练集、测试集,之后再进行分类了,可以采用的方法有很多,包括随机森林、决策树等,也尝试了SVC,效果比前两种方法差的比较多。分类效果的查验就采用的是计算OA与Kappa系数来计算了,比较方便且效果比较通用。
效果如下:
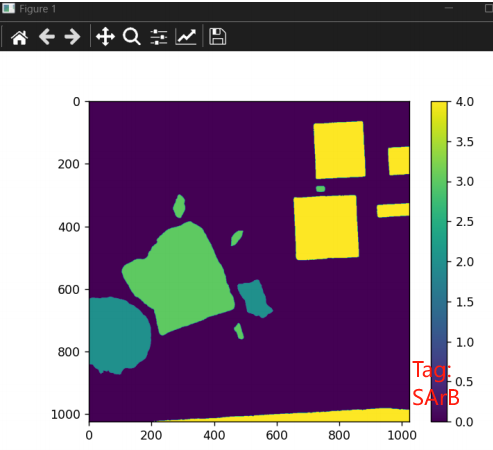
(好久没码字了,突然感觉写代码貌似比写字更快一点2333)





![[ 2024 CISCN x 长城杯 ] pwn avm](https://img2024.cnblogs.com/blog/3096265/202412/3096265-20241227203048939-905697326.png)