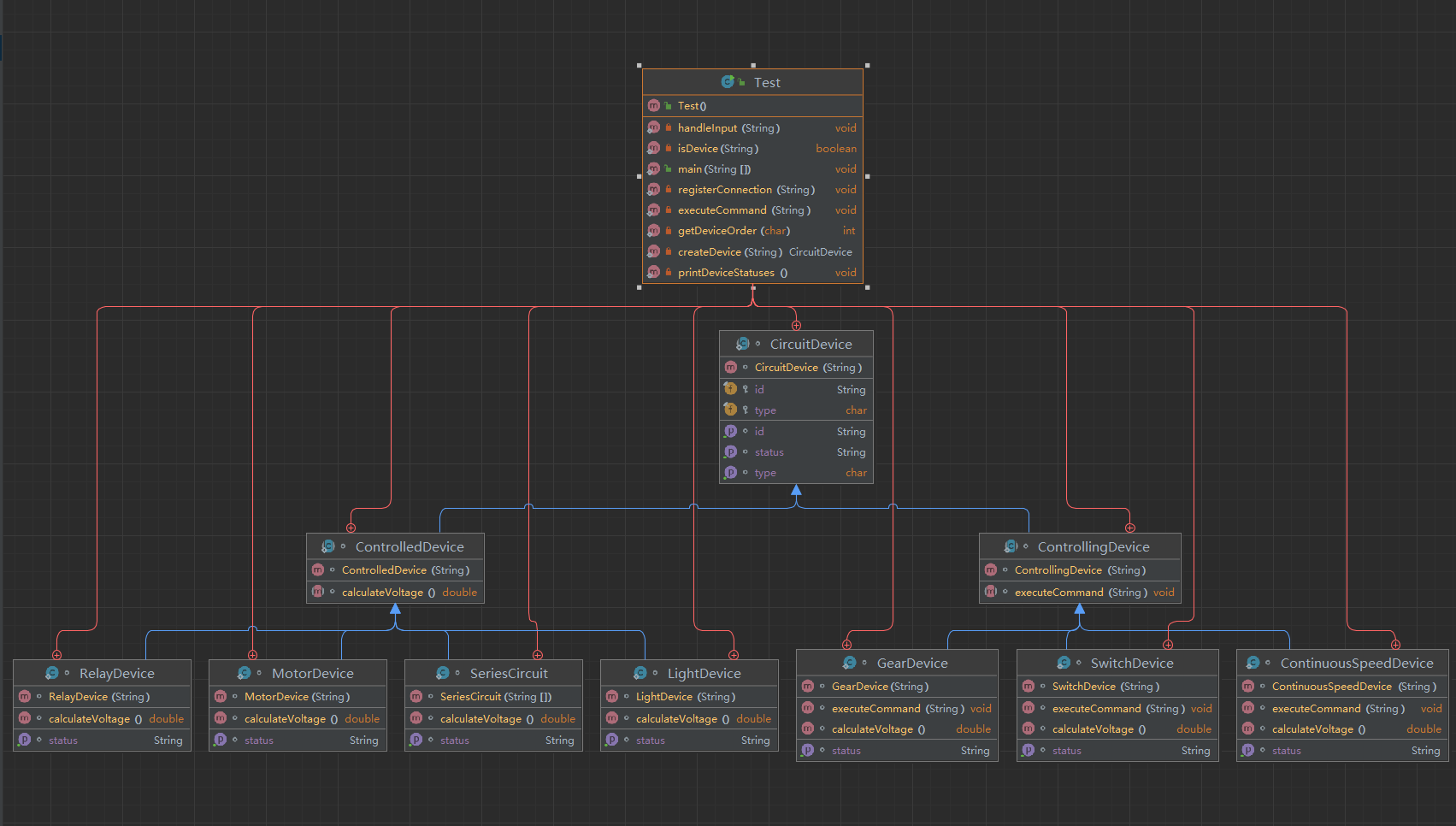
Python 正则表达式进阶用法:字符集与字符范围详解
正则表达式是文本处理和数据清洗中不可或缺的工具。在前面的学习中,我们已经了解了基本的正则表达式匹配,如匹配单个字符、字符串开始和结束的位置等。今天,我们将进入正则表达式的一个进阶主题:字符集(Character Set)和字符范围(Character Range)。
这两个概念是正则表达式强大匹配功能的基石。掌握它们后,您能够更高效地处理各种文本模式,进行更复杂的数据匹配和清洗。

一、字符集(Character Set)的概念
字符集(Character Set)是正则表达式中用于匹配特定一组字符的集合。字符集可以包含多个字符,也可以使用特殊的字符类来匹配一组常见的字符。
字符集的基本形式是将字符放入一对方括号 [] 中。例如,[abc] 匹配字符 a、b 或 c 中的任意一个。字符集是正则表达式中非常常见且重要的组成部分。
示例:简单的字符集匹配
假设我们有一个字符串 text = "apple banana cherry", 并且我们希望匹配所有包含字母 a、b 或 c 的单词:
import retext = "apple banana cherry"
pattern = r"\b[abc]\w*\b" # 匹配以 a, b, c 开头的单词
matches = re.findall(pattern, text)print(matches)
在这个例子中:
\b表示单词边界,确保我们匹配的是完整的单词。[abc]是字符集,表示我们要匹配的字符可以是a、b或c中的任意一个。\w*匹配单词字符(字母、数字和下划线),*表示匹配零次或多次。
输出结果:
['apple', 'banana', 'cherry']
这里的正则表达式成功地找到了所有以 a、b 或 c 开头的单词。
字符集中的特殊字符
字符集不仅限于字母和数字,还可以使用一些特殊字符来匹配特定类型的字符。例如:
\d:匹配任何数字,相当于[0-9]。\w:匹配任何字母、数字或下划线,相当于[a-zA-Z0-9_]。\s:匹配任何空白字符(如空格、制表符等)。.:匹配除换行符外的任何单个字符。
示例:匹配包含数字的单词
如果我们想从文本中匹配包含数字的单词,可以使用 \d 来匹配数字:
text = "apple 123banana cherry 4567"
pattern = r"\b\w*\d\w*\b" # 匹配包含数字的单词
matches = re.findall(pattern, text)print(matches)
输出结果:
['123banana', '4567']
在这个例子中,[abc] 被替换为 \d 来匹配包含数字的单词。
二、字符范围(Character Range)的概念
字符范围(Character Range)是正则表达式中用于表示一个连续字符集合的方式。它使用连字符 - 来指定一个字符范围。例如,[a-z] 匹配小写字母的任意一个字符。
示例:匹配小写字母
如果我们要匹配文本中的小写字母,可以使用字符范围 [a-z]:
import retext = "apple Banana Cherry"
pattern = r"[a-z]" # 匹配所有的小写字母
matches = re.findall(pattern, text)print(matches)
输出结果:
['a', 'p', 'p', 'l', 'e', 'a', 'n', 'a', 'b', 'a', 'n', 'a']
在这个例子中,正则表达式 [a-z] 匹配了所有的小写字母,包括 a、p、l 和 e 等。
字符范围的组合
字符范围不仅限于单一范围,还可以组合多个范围来匹配不同类型的字符。例如,[a-zA-Z] 匹配所有的字母,无论是小写还是大写。
text = "apple Banana Cherry 123"
pattern = r"[a-zA-Z]" # 匹配所有字母(包括大小写)
matches = re.findall(pattern, text)print(matches)
输出结果:
['a', 'p', 'p', 'l', 'e', 'B', 'a', 'n', 'a', 'n', 'a', 'C', 'h', 'e', 'r', 'r', 'y']
示例:匹配小写字母、数字和下划线
我们可以使用 \w 来匹配字母、数字和下划线,它等同于 [a-zA-Z0-9_]:
text = "apple_123 Banana Cherry_456 789"
pattern = r"\w+" # 匹配字母、数字和下划线组成的单词
matches = re.findall(pattern, text)print(matches)
输出结果:
['apple_123', 'Banana', 'Cherry_456', '789']
在这个例子中,\w+ 匹配一个或多个字母、数字或下划线。
三、使用字符集和字符范围匹配复杂的模式
字符集和字符范围为正则表达式提供了强大的灵活性,能够帮助我们匹配更复杂的文本模式。接下来,我们将通过一些实际的例子,演示如何使用字符集和字符范围来匹配更复杂的字符串。
示例:匹配包含数字和字母的单词
假设我们有以下文本,并希望匹配包含字母和数字的单词:
text = "apple 123banana Cherry_456 789"
pattern = r"\b[a-zA-Z0-9_]+\b" # 匹配包含字母、数字和下划线的单词
matches = re.findall(pattern, text)print(matches)
输出结果:
['apple', '123banana', 'Cherry_456', '789']
在这个例子中,\b[a-zA-Z0-9_]+\b 表示匹配由字母、数字和下划线组成的单词。
示例:匹配日期格式(yyyy-mm-dd)
假设我们有一个日期格式为 yyyy-mm-dd 的字符串,并且希望提取所有日期:
text = "Today is 2023-11-05, tomorrow is 2023-11-06."
pattern = r"\b\d{4}-\d{2}-\d{2}\b" # 匹配日期格式
matches = re.findall(pattern, text)print(matches)
输出结果:
['2023-11-05', '2023-11-06']
在这个例子中,\d{4}-\d{2}-\d{2} 匹配由 4 位数字、2 位数字和 2 位数字组成的日期。
示例:匹配手机号
如果我们想从文本中提取手机号,可以使用字符集和字符范围来匹配符合格式的手机号。假设手机号的格式为 “(xxx) xxx-xxxx”:
text = "My number is (123) 456-7890 and your number is (987) 654-3210."
pattern = r"\(\d{3}\) \d{3}-\d{4}" # 匹配手机号
matches = re.findall(pattern, text)print(matches)
输出结果:
['(123) 456-7890', '(987) 654-3210']
在这个例子中,\(\d{3}\) \d{3}-\d{4} 匹配括号中的三位数字和格式为 “xxx-xxxx” 的电话号码。
四、字符集和字符范围的注意事项
虽然字符集和字符范围是正则表达式非常强大的特性,但在使用时有一些注意事项需要了解:
- 字符集是贪婪的:如果没有使用
^或$来限制匹配的起始和结束位置,正则表达式会尽可能匹配更多的字符。 - 字符范围的顺序很重要:字符范围中的顺序会影响匹配的结果,例如,
[a-zA-Z]和[A-Za-z]都可以匹配字母,但如果定义的字符范围顺序不同,结果会有所不同。
五、总结
通过本文的讲解,我们深入了解了 Python 正则表达
式中的字符集和字符范围。这些进阶用法为我们提供了强大的匹配能力,可以应对各种复杂的文本处理任务。通过合理使用字符集和字符范围,我们能够高效地提取文本中的信息,进行数据清洗和转换。
在实际应用中,正则表达式的强大功能不仅限于这两个概念,还可以与其他高级特性如分组、反向引用等结合使用,从而实现更为复杂的文本匹配任务。掌握字符集和字符范围,将大大提高我们编写正则表达式的效率和准确性。