Service Worker 和 Web Worker 是两种不同类型的 JavaScript 工作者(worker),它们在浏览器环境中提供了不同的功能和使用场景。下面我们将分别介绍这两种工作者的使用场景、最佳实践以及它们之间的主要区别。
Service Worker
使用场景
- 离线支持:缓存静态资源,使网站可以在没有网络连接的情况下正常工作。
- 推送通知:即使网页不在前台,也能接收和显示推送通知。
- 背景同步:在网络恢复时自动重试失败的操作。
- 性能优化:通过拦截请求并从缓存中提供资源来加速页面加载。
- SEO 和渐进式 Web 应用 (PWA):提高应用的表现,使其更像本地应用程序。
最佳实践
- 仅注册 HTTPS 网站:为了安全起见,Service Worker 只能在 HTTPS 环境下注册。
- 最小化范围:尽量缩小 Service Worker 的作用范围,只覆盖必要的路径。
- 版本控制:为每个新版本的 Service Worker 添加唯一的缓存名,确保旧版缓存可以被正确清理。
- 缓存策略:根据资源类型选择合适的缓存策略(如 Cache-only, Network-only, Cache-first, Network-first 等)。
- 更新机制:实现 Service Worker 的更新逻辑,包括激活后清除过期缓存。
- 错误处理:捕获并记录任何可能发生的错误,以便调试和改进。
- 测试:使用工具(如 Lighthouse)对 PWA 功能进行全面测试。
Web Worker
使用场景
- 复杂计算:将耗时的计算任务放到后台线程执行,避免阻塞主线程。
- 数据处理:例如图像处理、音频处理等需要大量 CPU 资源的任务。
- 游戏开发:用于物理模拟、AI 逻辑等实时性要求高的场景。
- 长时间运行的任务:如轮询服务器、WebSocket 连接管理等。
最佳实践
- 通信方式:使用
postMessage方法与主线程交换信息,确保传递的数据是可序列化的。 - 生命周期管理:明确 Web Worker 的创建和销毁时机,防止内存泄漏。
- 避免频繁创建:Web Worker 的启动有一定的开销,因此应尽量复用已有的 Worker 实例。
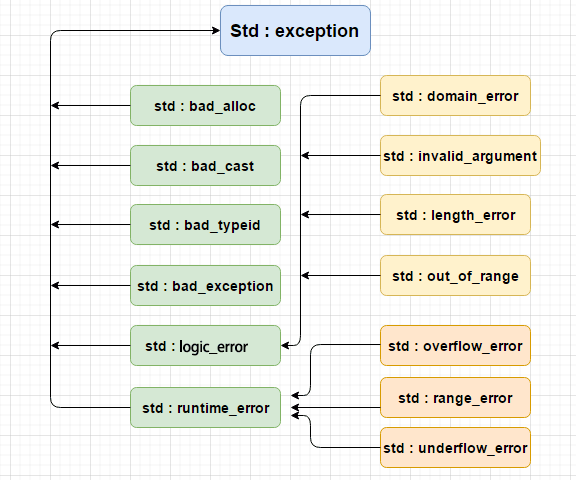
- 错误处理:监听
error事件以捕获并处理 Web Worker 中的异常。 - 隔离环境:理解 Web Worker 拥有独立的作用域和全局对象(如
self),并且不能直接访问 DOM。 - 文件分离:通常会将 Web Worker 的代码放在单独的文件中,尽管也可以使用内联 Worker(Blob URL)。
- 权限限制:注意 Web Worker 对某些 API 的访问权限有限制,比如它不能直接发起 HTTP 请求(需通过主线程代理)。
主要区别
- 作用范围:Service Worker 可以拦截和处理整个站点的网络请求,而 Web Worker 只能执行分配给它的特定任务。
- 生命周期:Service Worker 由浏览器管理其生命周期,并且可以在用户关闭标签页后仍然保持活跃;Web Worker 的生命周期由开发者控制,通常随着页面刷新而终止。
- API 访问:Service Worker 提供了额外的功能,如推送通知和背景同步,而 Web Worker 更专注于并发执行和计算密集型任务。
结论
选择 Service Worker 或 Web Worker 应基于具体的应用需求和技术栈。对于需要提升用户体验和构建 PWA 的项目来说,Service Worker 是不可或缺的一部分;而对于需要高性能计算或长时间运行的任务,Web Worker 则是理想的选择。遵循上述的最佳实践可以帮助你更好地利用这两种工作者的优势,构建高效且响应迅速的 Web 应用程序。




![[GPT] LangChain : `LLM` 编程框架](https://blog-static.cnblogs.com/files/johnnyzen/cnblogs-qq-group-qrcode.gif?t=1679679148)