今天是我们的第3站,了解下AI项目实践的5大环节,并通过一个预测直播带货销售额的案例来感受下。
今天是我们的第3站,了解下AI项目实践的5大环节,并通过一个预测直播带货销售额的案例来感受下。大家好,我是Edison。
最近入坑黄佳老师的《AI应用实战课》,记录下我的学习之旅,也算是总结回顾。
今天是我们的第3站,了解下AI项目实践的5大环节,并通过一个预测直播带货销售额的案例来感受下。
AI项目的5大环节
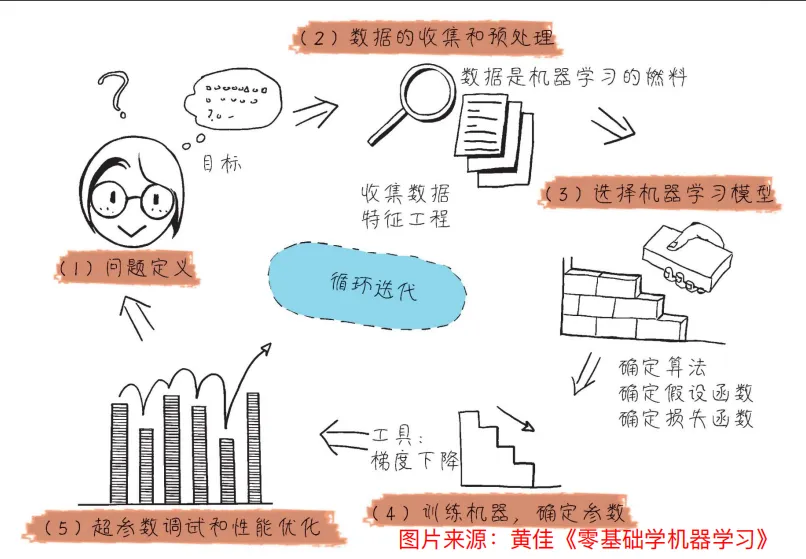
对于一个AI项目的实战大概有以下5大环节:
-
问题定义:需要明确定义需要解决什么问题,然后如何去衡量这个问题。
-
比如:现状是啥?目标是啥?谁会受益?如何解决?
-
数据准备:围绕着要解决的问题去准备数据和做特征工程,数据是机器学习的燃料。
-
比如:数据收集、清洗、转换、特征选择、特征工程
-
选择模型:根据问题和数据选择合适的机器学习模型,即确定算法以及算法中的假设函数和损失函数的过程。
-
比如:回归 or 分类?决策树?随机森林?神经网络?大语言模型?
-
训练调参:在模型内部调整它的参数,让这个模型适应我们的具体问题和具体数据。
-
比如:关注模型的拟合程度:过拟合 or 刚刚好 or 欠拟合
-
评估优化:模型的上限不是一蹴而就的,它需要一个反复的循环迭代,可能需要多种算法和数据相互比较才能得到最好的解决方案。比如:可以关注R平方分数、分类准确率等。
预测直播带货销售额
Step1 问题定义
问题背景:某直播带货平台,已知转发量、流量指数(平台推广力度)、商品类型。
问题定义:如何根据历史数据,预估本次直播带货成交量?
Step2 数据准备
假设我们有一些模拟出来的数据集如下:
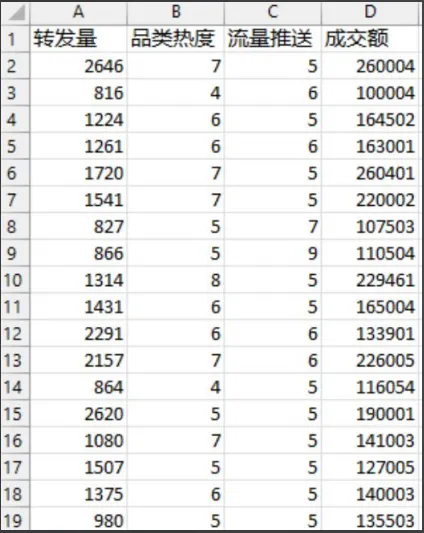
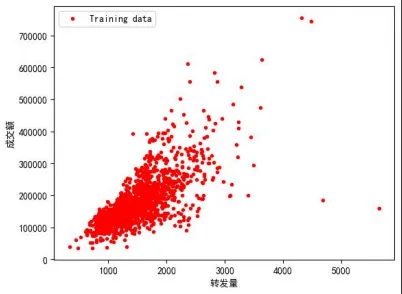
将这个模拟数据集读入后,可以发现存在一个转发量和成交额存在一个线性关系:当 一个商品被转发次数越多,其成交额也就越多。
Step3 选择模型
由于这个问题很简单,属于一个线性分布的问题,所以直接选择线性回归算法即可。杀鸡焉用牛刀,软件开发中的KISS原则,在AI项目中依然适用!
Step4 训练模型
用训练集数据训练模型,拟合函数,然后确定线性回归函数的参数(也就是y=ax+b中的a和b,即斜率和截距)。
Step5 评估结果
当拿到线性函数之后,得到训练集和测试集的R平方分数,越接近于1结果越好。
Python代码实现
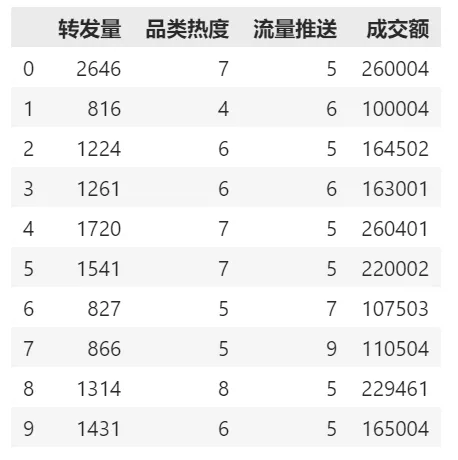
导入基本的数据处理工具
# 导入最基本的数据处理工具 import pandas as pd # 导入Pandas数据处理工具包 df_ads = pd.read_csv('demo-data.csv') # 读入数据 df_ads.head(10) # 显示前几行数据
显示的前几行数据如下图所示:
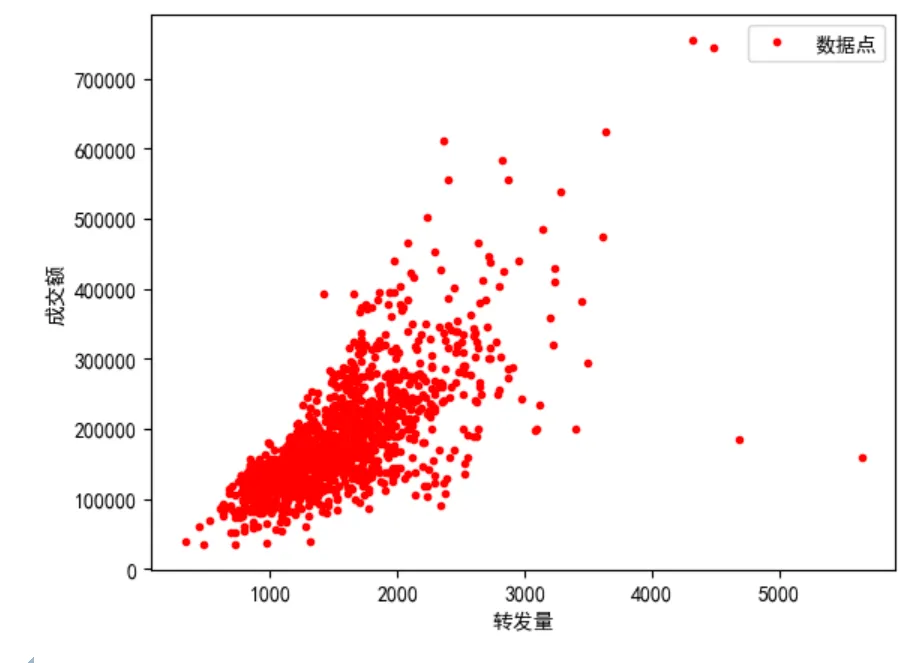
数据可视化辅助分析
# 导入数据可视化所需要的库 import matplotlib.pyplot as plt #Matplotlib – Python画图工具库 import seaborn as sns #Seaborn – 统计学数据可视化工具库 plt.plot(df_ads['转发量'],df_ads['成交额'],'r.', label='数据点') # 用matplotlib.pyplot的plot方法显示散点图 plt.xlabel('转发量') # x轴Label plt.ylabel('成交额') # y轴Label plt.legend() # 显示图例 plt.show() # 显示绘图结果
得到的散点图如下所示:
特征选择
X = df_ads.drop(['成交额'],axis=1) # 特征集,Drop掉标签字段 y = df_ads.成交额 # 标签集 X.head() # 显示前几行特征集数据 y.head() # 显示前几行标签集数据
数据集切分训练集和测试集
# 将数据集进行80%(训练集)和20%(验证集)的分割 from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)
导入算法模型并训练模型
from sklearn.linear_model import LinearRegression # 导入线性回归算法模型 model = LinearRegression() # 使用线性回归算法创建模型 model.fit(X_train, y_train) # 用训练集数据,训练机器,拟合函数,确定参数
预测测试集Y值并显示预测值
y_pred = model.predict(X_test) #预测测试集的Y值 df_ads_pred = X_test.copy() #测试集特征数据 df_ads_pred['成交额真值'] = y_test #测试集标签真值 df_ads_pred['成交额预测值'] = y_pred #测试集标签预测值 df_ads_pred #显示数据
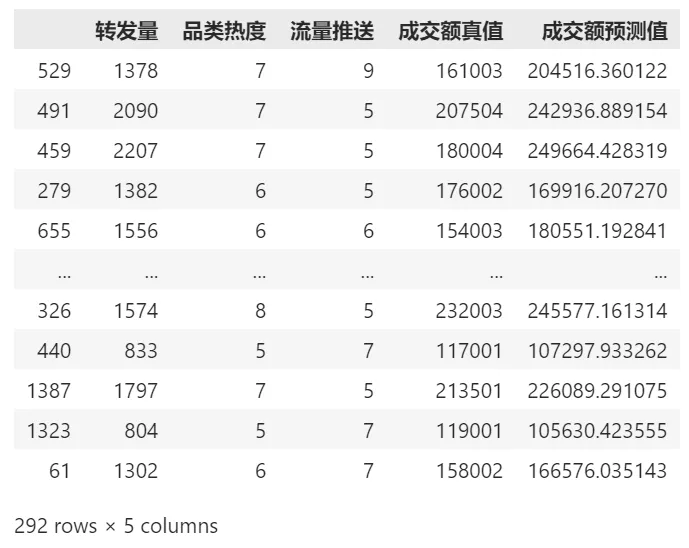
可以看到,成交额真实数值(位于测试集中)高一些,模型预测出来的预测值也会高一些,有的差的多一些,有的差的少一些。
评估模型的评分
print("线性回归预测集评分:", model.score(X_test, y_test)) #评估模型 print("线性回归训练集评分:", model.score(X_train, y_train)) #训练集评分
得到的评分信息如下:
线性回归预测集评分: 0.662399563560639
线性回归训练集评分: 0.7293166018868376
可以看到,该模型在训练集上的评分要高一些,而在预测集上的评分要低一些,不过也差得不是太多。
至此,这个项目的模型就算初步训练完成了。
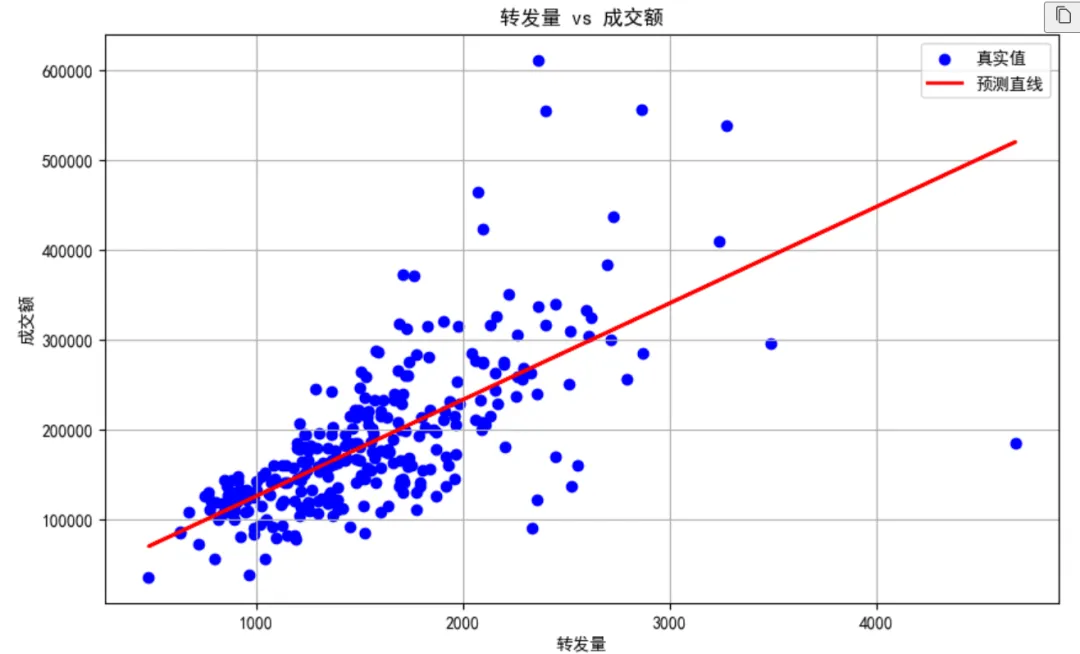
最后,如果我们想要了解这个模型到底长什么样(即线性函数长啥样),也可以通过下面的代码来绘制预测直线,这样就能在图中看到一个形象的感受:
# 分离特征和标签 X = df_ads[['转发量']] y = df_ads.成交额# 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)# 使用线性回归模型 model = LinearRegression() model.fit(X_train, y_train)# 预测 y_pred = model.predict(X_test)# 绘制预测直线 plt.figure(figsize=(10, 6)) plt.scatter(X_test, y_test, color='blue', label='真实值') # 画散点图 plt.plot(X_test, y_pred, color='red', linewidth=2, label='预测直线') # 画预测线 plt.xlabel('转发量') plt.ylabel('成交额') plt.title('转发量 vs 成交额') plt.legend() plt.grid(True) plt.show()
最终得到的预测直线如下图所示:
小结
本文快速了解了AI项目实战的五大环节,并通过一个预测直播带货销售额的案例来感受了一下。
推荐学习
黄佳,《AI应用实战课》(课程)

黄佳,《图解GPT:大模型是如何构建的》(图书)
黄佳,《动手做AI Agent》(图书)

作者:周旭龙
出处:https://edisonchou.cnblogs.com
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文链接。

![[论文速览] Vector Quantized Image-to-Image Translation](https://img2023.cnblogs.com/blog/1593499/202401/1593499-20240113154522952-1396962135.png)


![[转] Android源码对应分支、buildID](https://img2024.cnblogs.com/blog/597729/202412/597729-20241230183112857-685071515.png)