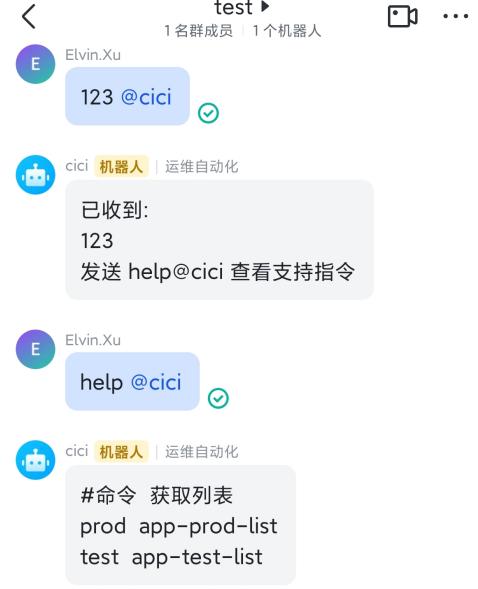
# 导入必要的库 from sklearn import datasets from sklearn.model_selection import train_test_split from sklearn.cluster import KMeans from sklearn.metrics import silhouette_score, accuracy_score, adjusted_rand_score import numpy as np# (1)加载数据集并划分数据集为训练集和测试集 iris = datasets.load_iris() # 加载 iris 数据集 X = iris.data # 特征值 y = iris.target # 目标值(仅用于最终评估)# 使用train_test_split函数进行数据集分割,留出1/3的样本作为测试集 # stratify=y 参数确保训练集和测试集中各类别的比例相同(同分布取样) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=1/3.0, random_state=42, stratify=y)# (2)初始化 K 均值聚类算法并训练,类别数为 3 kmeans = KMeans(n_clusters=3, random_state=42) # 创建 KMeans 实例,指定类别数为 3 kmeans.fit(X_train) # 使用训练集训练 KMeans 模型# 计算轮廓系数以评估聚类质量 silhouette_avg = silhouette_score(X_train, kmeans.labels_) print(f"训练集上的平均轮廓系数: {silhouette_avg}")# (3)使用测试集评估模型性能 y_pred = kmeans.predict(X_test) # 使用测试集预测聚类标签# 因为聚类是无监督的,所以需要调整随机指数 (Adjusted Rand Index, ARI) 来比较两个分配之间的相似性 ari = adjusted_rand_score(y_test, y_pred) print(f"测试集上的调整后的兰德指数 (ARI): {ari}")# (4)为了方便理解,我们还可以尝试计算一个简单的准确度分数,但要注意这个准确度可能不是最准确的评估指标 # 因为 K 均值聚类的标签是任意的,它们不一定与原始分类标签相匹配。 # 这里我们只是简单地用作参考。 accuracy = accuracy_score(y_test, y_pred) print(f"测试集上的简单准确度分数 (仅供参考): {accuracy}")