文章目录
- 概要
- 预备知识点学习
- 整体流程
- 技术名词解释
- 技术细节
- 小结
- 代码
概要
破解Vigenere需要Kasiski测试法与重合指数法的理论基础
具体知识点细节看下面这两篇文章
预备知识点学习
下面两个是结合起来使用猜测密钥长度的,只有确认了密钥长度之后才可以进行破解。
❀点击学习Kasiski测试法❀
❀点击学习重合指数法❀
整体流程
破解的方法就是不同的凯撒表中每个字母相乘得到的交互重合指数是否接近0.065,并且每两个表都要通过将凯撒表位移得到最接近0.065的那个偏移量,然后就可以得知这两个表相对位移多少的时候交互重合指数最接近0.065,以此类推将所有单表能够一起的可能组合都算一遍指数,最后观察每个组合MIC然后找出接近0.065且算出偏移量将所有未知数列出公式计算可得出26份密钥(难点在于如何计算出26份密钥!!!为此本座真的头秃了一大片)
流程如下
按照猜测的密钥长度分组计算单个凯撒表的每一个字母出现的频率
↓
所有凯撒表两两组合
↓
计算俩表之间的偏移量为g的时候,对应的交互重合指数为MIC
这里的重合指数计算是通过两个表的下标一致来进行相乘,只是偏移量不同
然后会出现26次偏移,因为凯撒密钥空间为26个字母
因此俩凯撒表组合就会产生26份重合指数。如图所示为任意两组的MIC数据
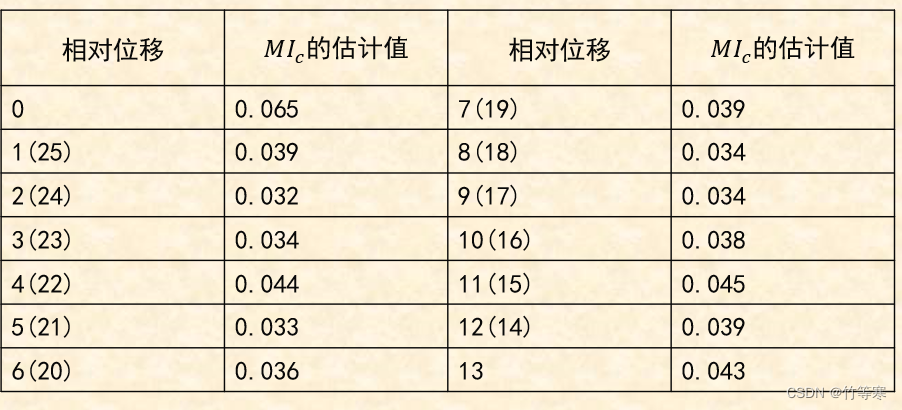
↓
得到了任意组合的26份交互重合指数后我们要找出最接近0.065的,并且算出他的相对位移(偏移量),就会得到类似的公式。如何在程序中实现,这个让我头秃了(后面附上代码)
当
i=0,j=1,相对位移s=?时,MIc=最接近0.065
…
…
…
i=4,j=5,相对位移s=?时,MIc=最接近0.065
则有:
k0-k2=2
k0-k3=9
…
…
…
k4-k5=4
由此求得密钥字间的相对位移
因为已知k0 ~ k5运算得到的公式,然后我们可以假定k0为a ~ z的字母,得到一个字母之后其他未知数也就能够计算了,因此会产生26份密钥出来
↓
有26份密钥之后,需要找出最真密钥,其他都是伪密钥。
需要用到统计的26个字母常用的频率,这个可能就是Vigenere的缺陷了,一旦是一个非正常文本就几乎破解不了。因为用的就是常用词频统计的出来的概率,同样这个表不用我们统计,网上一查一堆。这里将其称为AZ表
'''a-z的频率,这是不是指你加密的词频,
而是大家阅读各式各样的文章中出现次数
最多的也可以理解为大数据统计出来的'''
[0.082, 0.015, 0.028, 0.043,
0.127, 0.022, 0.02, 0.061,0.07, 0.002, 0.008,0.04, 0.024, 0.067, 0.075, 0.019, 0.001, 0.06, 0.063, 0.091,0.028, 0.01, 0.023, 0.001, 0.02, 0.001]
由于已知密钥了,所以只需要将其密钥的单个字母对单个凯撒解密之后,将其解密的凯撒表与AZ表对应的字母概率相乘,最后将其所有结果加起来是否接近0.065,如果接近则可以考虑将其纳入真实密钥的列表名单。
↓
最后缩小范围得到所有最接近密钥之后,我们可以选择采用一个一个的将密文解密,解出来之后看是否读的通顺即为密钥。(我到了这一步就用肉眼观察了)
技术名词解释
- Ic重合指数:指的是单个凯撒表的每一个字母概率的平方,最后26个字母得出的概率相加
- MIc交互重合指数:不同表之间对应字母概率相乘,最后26个字母得出的概率相加
- 相对位移:不同表之间虽然用不同密钥加密,但是不同密钥之间又有一个密钥距离,比如1表用a加密,2表用c加密,那么这两个表的相对位移就是2,但是在破解的时候不知道是偏移多少,所以需要循环将其偏移,然后计算MIc计算出最接近0.065的就是可能的真实偏移量。
具体为何要偏移26,是因为密钥空间26,所以你必须位移26次。
技术细节
程序中实现的分工必须要很明确,否则乱成一坨。
- 函数分工
- shiftCaserCode:将密文成不同的凯撒表
- caltMIC:计算重合指数
- caltResult:找出所有可能的密钥
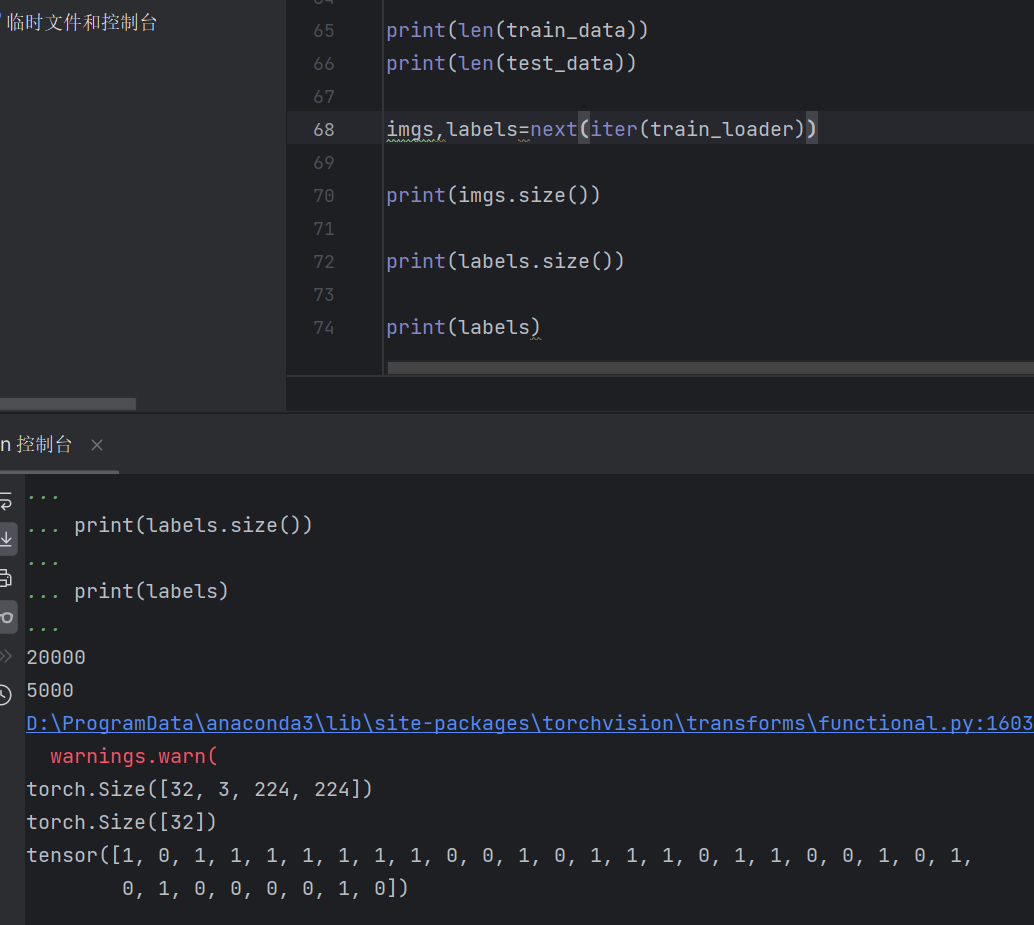
- findEndKey:通过与AZ表概率交互重合得出最接近0.065的密钥
小结
破解Vigenere十分艰辛,但是收获满满,不仅对破解有了一定了解,很大一部分影响是编程技巧在此得到了提升,对自己的编程能力更加有信心。
比如如何在Kasiski测试法中如何找到片段出现次数最多且要考虑不同的长度片段的统计还要计算出相同长度出现次数最高的那一个。
在计算重合指数的时候对字典有了一个更深的了解,字典可以按需使用,我这里就采用数组作为键,大大提高了编程效率,还认识到了在3.6版本之后的Python已经支持按顺序打印输出了,不再是无序的字典,这也帮我解决了很大一部分繁琐的操作。
代码
由于在我的程序中是用类和pyqt5结合使用,所以下面的函数都是在类中定义的,主要运行功能在outputKeys函数中进入。
class CrackVigenere(ModuleCode):name = 'CrackVigenere'# 正常文本统计出来的概率NormalFrequ = [0.082, 0.015, 0.028, 0.043, 0.127, 0.022, 0.02, 0.061, 0.07, 0.002, 0.008,0.04, 0.024, 0.067, 0.075, 0.019, 0.001, 0.06, 0.063, 0.091, 0.028, 0.01, 0.023, 0.001, 0.02, 0.001]def __init__(self, appInit):super().__init__(appInit, self.name)def newMe(self, appInit):return CrackVigenere(appInit)def InitUI(self):super(CrackVigenere, self).InitUI()def bindCapabilities(self):self.enterbtn.clicked.connect(lambda: self.outputKeys())self.save_file_btn.clicked.connect(lambda: self.saveFileText())self.choice_file_btn.clicked.connect(lambda: self.choiceFIleText())# ===============================================找出所有可能的密钥==================================================def shiftCaserCode(self, mess, keylen):newdit = {}for i in range(keylen):newdit[i] = []c = self.messGroupByN(mess, keylen) # 将密文分组for i in range(len(c)): # 将分好组的c密文抽出每一行对应一个加密字母,变成一行的单行凯撒加密for j in range(len(c[i])):if j < len(c[i]):newdit[j].append(ord(c[i][j]) - ord('A'))return newditdef messGroupByN(self, mess, n): # 根据密钥长度分组sunlist = []temp = [''] * n# print(math.ceil(len(mess) / n))count = 0# print(mess)for ch in mess:if ord('A') <= ord(ch) <= ord('Z') or ord('a') <= ord(ch) <= ord('z'):temp[count % n] = ch.upper()count += 1if count % n == 0 and count != 0:sunlist.append(temp[0:n + 1])temp = [''] * nif count % n != 0:sunlist.append(list(temp[0:count % n]))return sunlistdef caltMIC(self, newdit, keylen):dit_A_Z = {} # 保存本行每一个字母出现的次数curr_p = {} # # 对应该行每一个字母出现的概率nextdit_A_Z = {} # 保存本行每一个字母出现的次数nextcurr_p = {} # # 对应该行每一个字母出现的概率MIc = {} # 是curr_p * nextcurr_p 的遍历,交互重合指数for i in range(26): # 初始化字典,分别用于存放26个 字母出现次数 和 相对位移的概率dit_A_Z[i] = 0curr_p[i] = 0nextdit_A_Z[i] = 0nextcurr_p[i] = 0for i in range(keylen - 1): # (keylen - 1 * keylen)/ 2 = 总次数,因为每一行都要对应进行一次重合指数的计算for j in range(len(newdit[i])): dit_A_Z[newdit[i][j]] += 1 # 统计i行中字母次数,newdit[i]对应每一行的长度for row in range(i + 1, keylen): # 操作i行后面的行p = [] # 存放一组某行j中与i的相对位移的每一个概率for j in range(len(newdit[row])): nextdit_A_Z[newdit[row][j]] += 1 # 同理先统计j行中字母次数sum = 0for j in range(26): # 统计每一个字母出现的概率curr_p[j] = dit_A_Z[j] / len(newdit[i]) # i行每个字母出现的概率,放进这里一起统计能够减少i的一次统计循环nextcurr_p[j] = nextdit_A_Z[j] / len(newdit[row]) # j行出现字母的概率maxnum = 0temp_Mic = {}print("========================{},{}=================================\n".format(i, row))for g in range(26): # 开始计算相对位移的每个概率for index in range(26): # 计算MIc交互重合指数,相对位移是 gsum += curr_p[(index + g) % 26] * nextcurr_p[index] # 本行位移,往后的行不位移if float(self.Icleft.toPlainText()) < sum < float(self.Icright.toPlainText()):# 目前是按照区间寻找接近0.065# 若在本轮ij的重合指数最接近0.065,然后记录下对应的i j g 和概率p(保留三位小数)temp_Mic[(i, row, g)] = self.loseTailNum(sum, 3)# MIc[(i, row, g)] = self.loseTailNum(sum, 3)# break(是否退出循环?有待考证)print("{}".format(self.loseTailNum(sum, 3)), end=' ')if (g + 1) % 9 == 0: print()sum = 0 # 清空继续存下一个相对位移概率print("\n=========================================================")if self.checkbox.isChecked():if len(temp_Mic) != 0: # 当26个相对位移计算完就找出本轮i j交互重合指数最大的,并且是上面判断过要接近0.065的max_item = sorted(temp_Mic.items(), key=lambda x: x[1], reverse=True)[0]MIc[max_item[0]] = max_item[1]else:for item in temp_Mic.items():MIc[item[0]] = item[1]for d in range(26): # 清空数据重新加载下一j行的数据curr_p[d] = 0nextdit_A_Z[d] = 0nextcurr_p[d] = 0for d in range(26): dit_A_Z[d] = 0 # 返回循环之后,i需往后移动,所以保存上一行的数据要清空print("每一项元素为:(i, j, g): (i和j的交互重合指数)\n", MIc)return MIcdef loseTailNum(self, num, Tailindex):newnum = str(num).split(".")[0] + "." + str(num).split(".")[1][0:Tailindex]# print(float(newnum))return float(newnum)def caltResult(self, DIT_jie, MIc):keylen = len(DIT_jie)save = [] # 保存每一组解,每组解都是一个字典for i in range(26):for j in range(keylen): DIT_jie[j] = NoneDIT_jie[0] = i # 仅用第一个未知变量可就出所有for k in MIc.keys(): # MIc.keys()的结构: (i,j,g),可以通过i j来判断是代表keys哪一个位置的字母for j in range(26):trigger = Truefor v in DIT_jie.values():if v == None:trigger = Falsebreakif trigger == True: breakif DIT_jie[k[0]] == None: # 最后左边DIT_jie[k[0]] = 0for j_2 in range(26):if (DIT_jie[k[0]] - DIT_jie[k[1]]) % 26 == k[2]:breakelse:DIT_jie[k[0]] = j_2elif DIT_jie[k[1]] == None: # 最后右边DIT_jie[k[1]] = 0for j_2 in range(26):if (DIT_jie[k[0]] - DIT_jie[k[1]]) % 26 == k[2]:breakelse:DIT_jie[k[1]] = j_2else: # 正常计算if DIT_jie[k[1]] == None: DIT_jie[k[1]] = 0if (DIT_jie[k[0]] - DIT_jie[k[1]]) % 26 == k[2]:# print(DIT_jie[k[0]],"-",DIT_jie[k[1]], "=", k[2])breakelse:DIT_jie[k[1]] = jif j == 25: DIT_jie[k[1]] = 0# 如果说在本轮的k中符合了该方程就退出循环,# 否则一直通过循环j改变第二个值,因为这里i必定大于j,所以只要i对应的未知变量确定了第二个只需通过迭代循环找出符合条件即可save.append(DIT_jie.copy()) # 保存本轮循环的解return savedef findKeys(self, cipher, keylen):# =======================================================================================================================# 定义MIc = {} # 是curr_p * nextcurr_p 的遍历,交互重合指数newdit = {} # 首先生成一个新表,存放对应每一个key的单行凯撒加密,长度为keylen的表,即row为keylenDIT_jie = {} # 键:keylen就有多少个键,键对应着是第i?key,值对应着第i个key等于多少# =======================================================================================================================# 初始化for i in range(keylen):DIT_jie[i] = 0# =======================================================================================================================# 生成每一行的凯撒加密newdit = self.shiftCaserCode(cipher, keylen)# =======================================================================================================================# MIC重合指数计算MIc = self.caltMIC(newdit, keylen)# =======================================================================================================================# 找出所有可能的密钥save = [] # 保存每一组解,每组解都是一个字典save = self.caltResult(DIT_jie, MIc)# =======================================================================================================================# 下面是密钥数字转密钥字母re = [] # 保存每一组的数字解allkeys = [] # 保存每一组密钥的字母解t = []for i in save: re.append(i.values()) # 取出每一组解的字典的值,即该组解的结果for i in re:for j in i: t.append(chr(j + ord('A')))allkeys.append(t.copy())t.clear() # 清空列表,继续循环保存每个字母解# print(allkeys) # 打印测试self.showPLT(MIc) # 显示每一组解对应的i,j的MIC值return allkeys, newdit # 返回所有字母解def showPLT(self, MIc):plt.close()x_data = ["({},{})\ng={}".format(i[0][0], i[0][1], i[0][2]) for i in MIc.items()]y_data = [round(i, 3) for i in MIc.values()]plt.rcParams["font.sans-serif"] = ['SimHei']plt.rcParams["axes.unicode_minus"] = Falseplt.subplot(111)plt.plot(x_data, y_data, marker='.', c='r', ms=5, linewidth='1', label="线形交互重合指数")plt.legend(loc="lower right")for i in range(len(x_data)):plt.text(i, y_data[i], str(y_data[i]), ha="center", va="bottom", fontsize=10)plt.title("密文子串中最接近0.065的交互重合指数")plt.xlabel("(i,j)和相对位移g")plt.show()# ========================================找出最后最符合的唯一密钥======================================================================def findEndKey(self, keys, newdit):dit_A_Z = {} # 保存本行每一个字母出现的次数curr_p = {} # # 对应该行每一个字母出现的概率MIc = {} # 是curr_p * nextcurr_p 的遍历,交互重合指数for i in range(26): # 初始化字典,分别用于存放26个 字母出现次数 和 相对位移的概率dit_A_Z[i] = 0curr_p[i] = 0A_Z_P = []for key in keys:sum = 0 # 清空继续存下一个相对位移概率for i in range(len(key)): # (keylen - 1 * keylen)/ 2 = 总次数,因为每一行都要对应进行一次重合指数的计算# g = keysfor j in range(len(newdit[i])): dit_A_Z[newdit[i][j]] += 1 # 统计i行中字母次数,newdit[i]对应每一行的长度for j in range(26): # 统计每一个字母出现的概率curr_p[j] = dit_A_Z[j] / len(newdit[i]) # i行每个字母出现的概率g = ord(key[i]) - ord('A') # 密钥中一个字符就是一个相对位移for index in range(26): # 计算MIc交互重合指数,相对位移是 gsum += curr_p[(index + g) % 26] * self.NormalFrequ[index] # 本行位移,往后的行不位移# print(sum)for d in range(26): # 清空数据重新加载下一j行的数据curr_p[d] = 0dit_A_Z[d] = 0 # 返回循环之后,i需往后移动,所以保存上一行的数据要清空A_Z_P.append(sum / len(key))max_num = 0max_index = 0for i in range(len(A_Z_P)):if A_Z_P[i] > max_num:max_index = imax_num = A_Z_P[i]return [A_Z_P, (max_index, max_num)]#功能运行入口def outputKeys(self):key = self.keytext.toPlainText()c = self.input_text.toPlainText()if c == '':self.input_text.setText('what is your text?')returnelif key == '':self.input_text.setText('what is your key?')returnsave_Ic = Noneself.outPut_text.clear() # 清理掉之前保留的文本,以防每次输出都叠加cipher = '' # 存放没有非法符号的密文for ch in c:if ord('A') <= ord(ch) <= ord('Z') or ord('a') <= ord(ch) <= ord('z'):cipher += chprint('发现密钥中...')chkeys, newdit = self.findKeys(cipher, int(key))A_Z_P, data = self.findEndKey(chkeys, newdit) # 拆包keyIndex, keyIc = data # 拆包keyIc = self.loseTailNum(keyIc, 3)endkey = ""for ch in chkeys[keyIndex]:endkey += chself.message += "最有可能的密钥:{}\n重合指数为:{}\n".format(endkey, keyIc)for i in chkeys:self.message += ''.join(i)self.message += '\n'self.outPut_text.setText(self.message)self.toSaveFile = ''.join(self.message)self.finalizeGC() # 清除保存的数据用于下次计算print('成功')