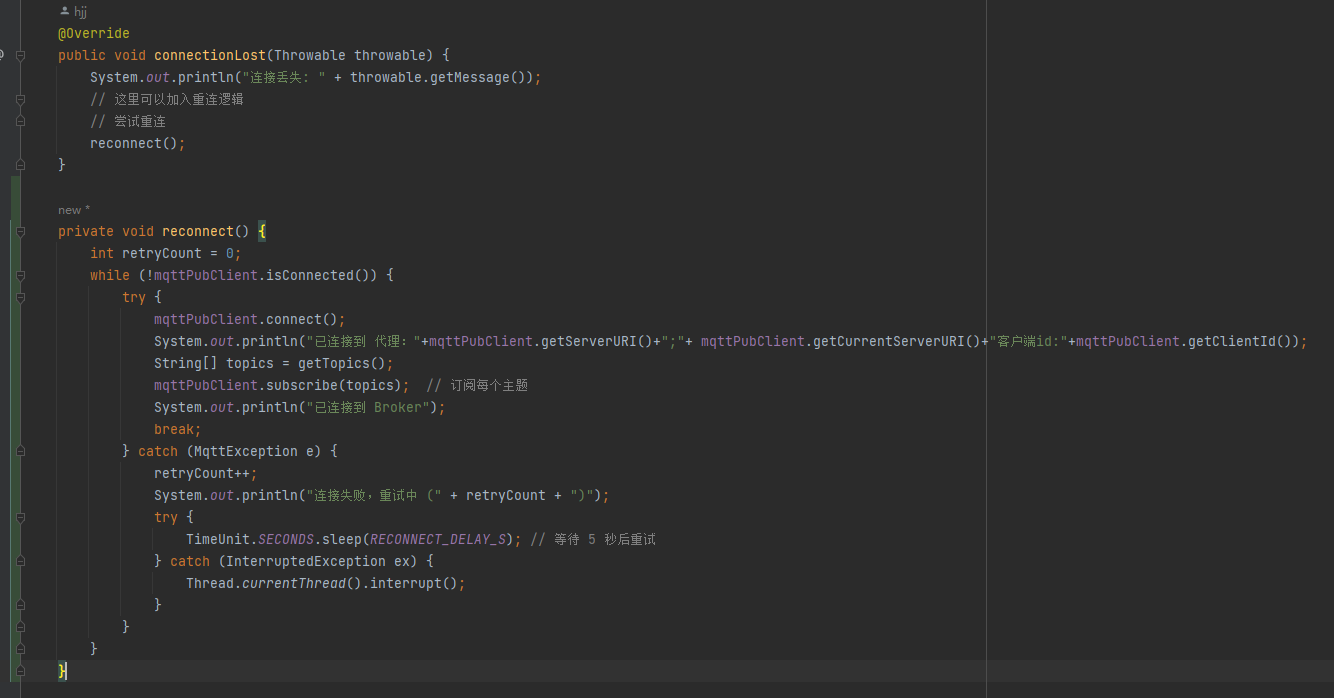
首先我们知道hashMap在存取元素的时候的下标算法是这样子的
根据当前元素(e)的hash值((e.hashCode()) ^ (e.hashCode() >>> 16))去与上当前hashMap的容量减一(Cap-1)
put和get都是如此
put

get

所以在扩容算法中,元素的坐标也应是用这种方式存的,看一下代码

我们会发现,
当,当前元素不存在链表的小尾巴时,他放入扩容以后的新数组(newTab),计算下标的时候,使用的还是很直白的方式,即元素hash值与上新数组的容量减一(newCap - 1);
当,当前元素是存在链表结构的时候,会用元素hash与上老数组的容量(oldCap),根据结果是否为0,来拆分成高位链表(hiHead->hiTail)和低位链表(loHead->loTail),并,分别存入到新数组的高位(newTab[j + oldCap])和低位(newTable[j]);
以前我看的时候只知道是把长链表拆了两段分别放入新数组,没有想过为什么要根据e.hash() & oldCap == 0 来拆分,为什么新数组的下标可以直接写成 newTab[j] 和 newTab[j + oldCap];
这是我想记下来的;
-------------------------------------------
这里举个例子方便理解,比如原来的oldCap是16 (0001 0000(这里只写8位)),现在的newCap是32(0010 0000)
先看e.hash() & oldCap == 0,根据结果是否为0判断,其实就是判断下标为4的位是否为0;
如果为0,那就说明e.hash() & (oldCap - 1) == e.hash() & (newCap - 1) // 下标位4的位为0时 & 0000 1111 & 0001 1111 相同
因此可以直接把原先老数组的下标j直接带入到新的数组,也就是newTab[j] = loHead;
同时,看高位链表的下标,j + oldCap 等于 e.hash() & (oldCap - 1) + oldCap,
等于 e.hash() & 0000 1111 的值 加上 0001 0000,
等于 e.hash() & 0001 1111,
等于 e.hash() & (newCap - 1) // 直白的下标写法
所以newTab[e.hash() & (newCap - 1)] 在这里才可以被表示成newTab[j + oldCap]
//想到了就先记下来,怕我以后会忘记