主要介绍单精度/半精度/混合精度训练,以及部分框架(DeepSpeed/Apex)
不同精度训练
单精度训练(single-precision)指的是用32位浮点数(FP32)表示所有的参数、激活值和梯度
半精度训练(half-precision)指的是用16位浮点数(FP16 或 BF16)表示数据。(FP16 是 IEEE 标准,BF16 是一种更适合 AI 计算的变种)
混合精度训练(mixed-precision)指的是同时使用 FP16/BF16 和 FP32,利用二者的优点。通常,模型权重和梯度使用 FP32,而激活值和中间计算使用 FP16/BF16
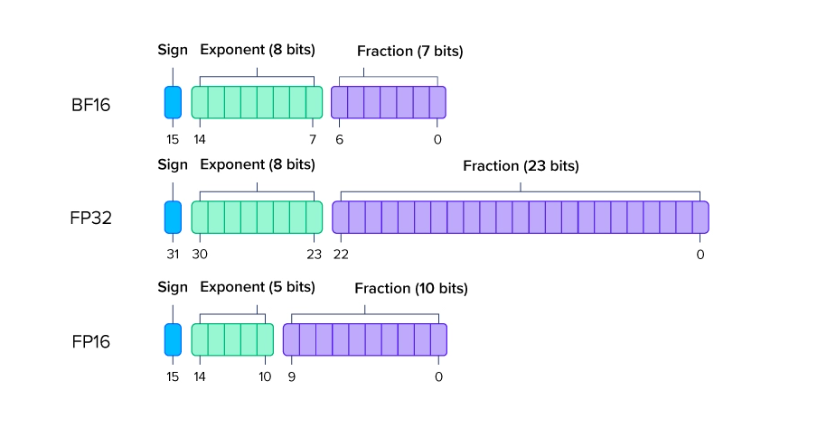
Image From: https://www.exxactcorp.com/blog/hpc/what-is-fp64-fp32-fp16
不同精度之间对比:
| 指标 | 单精度(FP32) | 半精度(FP16/BF16) | 混合精度 |
|---|---|---|---|
| 精度 | 高 | 较低(FP16),中(BF16) | 中高 |
| 显存占用 | 高 | 低 | 较低 |
| 训练速度 | 较慢 | 快 | 快 |
| 稳定性 | 最佳 | 稳定性低(FP16) | 稳定 |
| 适用场景 | 小规模任务 | 性能优先,大规模模型 | 性能与稳定的平衡 |
混合精度训练(https://arxiv.org/pdf/1710.03740):
为什么不只用单精度训练(速度快/显存占用少)
1、直接使用半精度(FP16)容易引发数值问题,如溢出(overflow)和下溢(underflow):这里是因为单精度有效尾数(约10位尾数)较单精度要小得多,那么就会有一个问题因此在训练过程中,如果激活函数的梯度非常小,可能会因精度不足而被舍弃为零,导致梯度下溢。此外,当数值超过半精度的表示范围时,也会发生溢出问题。这些限制会使训练难以正常进行,导致模型无法收敛或性能下降;
2、舍入误差(Rounding Error) 舍入误差指的是当梯度过小,小于当前区间内的最小间隔时,该次梯度更新可能会失败,用一张图清晰地表示:Image: https://zhuanlan.zhihu.com/p/79887894
总的来说就是:如果只用半精度会导致精度损失严重,因此就会提出用混合精度进行训练

解决上面用单精度造成的问题,在混合精度训练中论文提到的解决办法:
- 1、
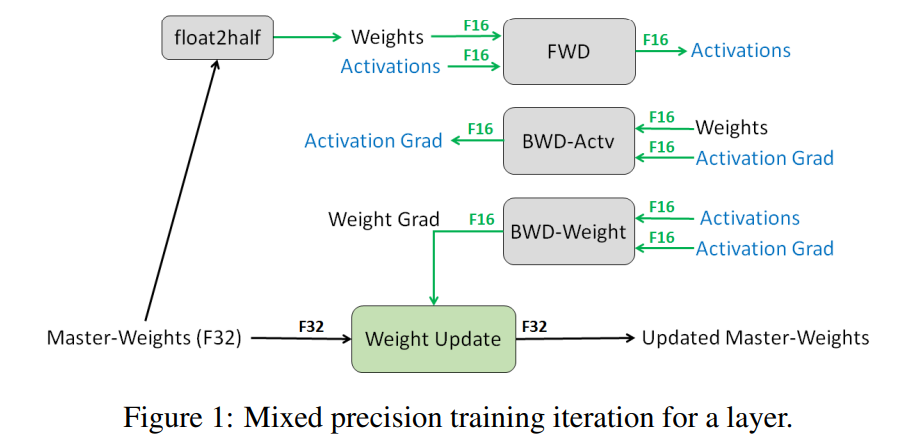
FP32 MASTER COPY OF WEIGHTS
模型权重会同时维护两个版本:1、FP32权重(Master Copy):以32位浮点数表示,用于存储和更新权重的精确值。2、FP16权重(Working Copy):以16位浮点数表示,用于前向传播和反向传播的计算,减少显存占用并加速运算。
这里就会有一个问题,反向传播过程中要计算梯度,如果(梯度用FP16)梯度很小,不也还是会出现溢出问题,作者后续提到
LOSS SCALING可以解决这种问题。如果梯度很大也会导致溢出问题,梯度计算使用FP16,但在权重更新之前,梯度会转换为 FP32 精度进行累积和存储,从而避免因溢出导致的权重更新错误。
另外之所以要用FP32对权重进行保存这是因为,作者研究发现更新 FP16 权重会导致 80% 的相对准确度损失。
we match FP32 training results when updating an
FP32 master copy of weights after FP16 forward and backward passes, while updating FP16 weights
results in 80% relative accuracy loss
另外一方面,如果拷贝权重,不也等同于把显存的占用拉大了?参考知乎上描述显存占用上主要是中间过程值
- 2、
LOSS SCALING
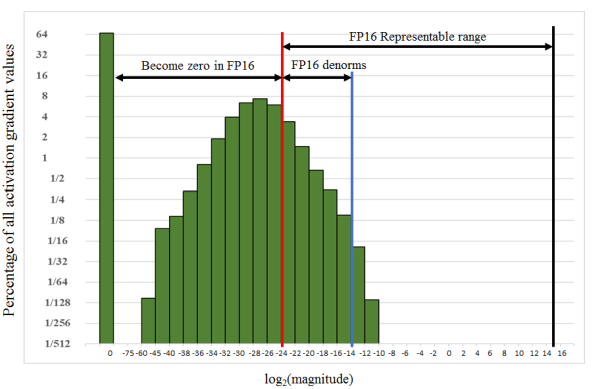
下图展示了 SSD 模型在训练过程中,激活函数梯度的分布情况,容易发现部分梯度值如果用FP16容易导致最后的梯度值变为0,这样就会导致上面提到的溢出问题,那么论文里面的做法就是:在反向传播前将loss增打\(2^k\)倍,这样就会保证不发生下溢出(乘一个常数,后面再去除这个常数不影响结果),如何反向传播再去除这个常数即可。
- 3、
Apex实现混合精度训练
git clone https://github.com/NVIDIA/apex
cd apex
python3 setup.py install
分别用Apex和torch原生的amp在MNIST数据集上进行测试(模型:1层卷积+池化+2层全连接层)
# Apex
from apex import amp
...
model, optimizer = amp.initialize(model, optimizer, opt_level="O1", loss_scale="dynamic")
...
with amp.scale_loss(loss, optimizer) as scaled_loss:scaled_loss.backward()# Amp
from torch.cuda.amp import autocast, GradScaler
...
scaler = GradScaler()
...
scaler.scale(loss).backward()
scaler.step(optimizer)
scaler.update()
Apex中Amp参数(https://nvidia.github.io/apex/amp.html):
1、opt_level(欧1而不是零1):
O0:纯FP32训练,可以作为accuracy的baseline;
O1:混合精度训练(推荐使用),根据黑白名单自动决定使用FP16(GEMM, 卷积)还是FP32(Softmax)进行计算。
O2:“几乎FP16”混合精度训练,不存在黑白名单,除了Batch norm,几乎都是用FP16计算。
O3:纯FP16训练,很不稳定,但是可以作为speed的baseline;
2、loss_scale="dynamic"
损失值处理(LOSS SCALING)默认是动态(初始一个较大的值,检查到溢出就减小)
测试效果:
准确率变化上:
在公开数据集(CIFAR10)上进行测试(模型为resnet50)测试使用的设备为4090
训练集上变化
| Run | Smoothed | Value | Step | Time | 显存占用 |
|---|---|---|---|---|---|
| scalar-CIFAR10/scalar-256-amp | 0.8026 | 0.9364 | 11 | 16.99 min | 15508 |
| scalar-CIFAR10/scalar-256-apex | 0.8093 | 0.9366 | 11 | 16.51 min | 13166 |
| scalar-CIFAR10/scalar-256-fp32 | 0.7946 | 0.9456 | 11 | 22.27 min | 22818 |
测试集上变化
| Run | Smoothed | Value | Step | Time | 显存占用 |
|---|---|---|---|---|---|
| scalar-CIFAR10/scalar-256-amp | 0.7302 | 0.8031 | 11 | 16.99 min | 15508 |
| scalar-CIFAR10/scalar-256-apex | 0.7323 | 0.7956 | 11 | 16.51 min | 13166 |
| scalar-CIFAR10/scalar-256-fp32 | 0.7250 | 0.8092 | 11 | 22.27 min | 22818 |
根据知乎:Nicolas和Dreaming.O实验建议:
- 1、判断你的GPU是否支持FP16:支持的有拥有Tensor Core的GPU(2080Ti、Titan、Tesla等),不支持的(Pascal系列)
import torchif torch.cuda.is_available():device = torch.device("cuda")compute_capability = torch.cuda.get_device_capability(device)print(f"Compute Capability: {compute_capability[0]}.{compute_capability[1]}")
else:print("CUDA is not available.")
结果\(≥7\)说明支持
- 2、开启混合精度加速后,Training 对 CPU 的利用率会变得很敏感
如果训练时候 CPU 大量被占用的话,会导致严重的减速。具体表现在:CPU被大量占用后,GPU-kernel的利用率下降明显。估计是因为混合精度加速有大量的cast操作需要CPU参与,如果CPU拖了后腿,则会导致GPU的利用率也下降。
- 3、使用
Apex框架会出现溢出情况
因为在Apex的amp默认使用的是dynamic可以改为1024或者2048
显存优化
gradient-checkpoint参考: https://www.cnblogs.com/Big-Yellow/p/18646083
参考
1、https://arxiv.org/pdf/1710.03740
2、https://www.exxactcorp.com/blog/hpc/what-is-fp64-fp32-fp16
3、https://zhuanlan.zhihu.com/p/79887894
4、https://zhuanlan.zhihu.com/p/84219777
5、https://nvidia.github.io/apex/amp.html