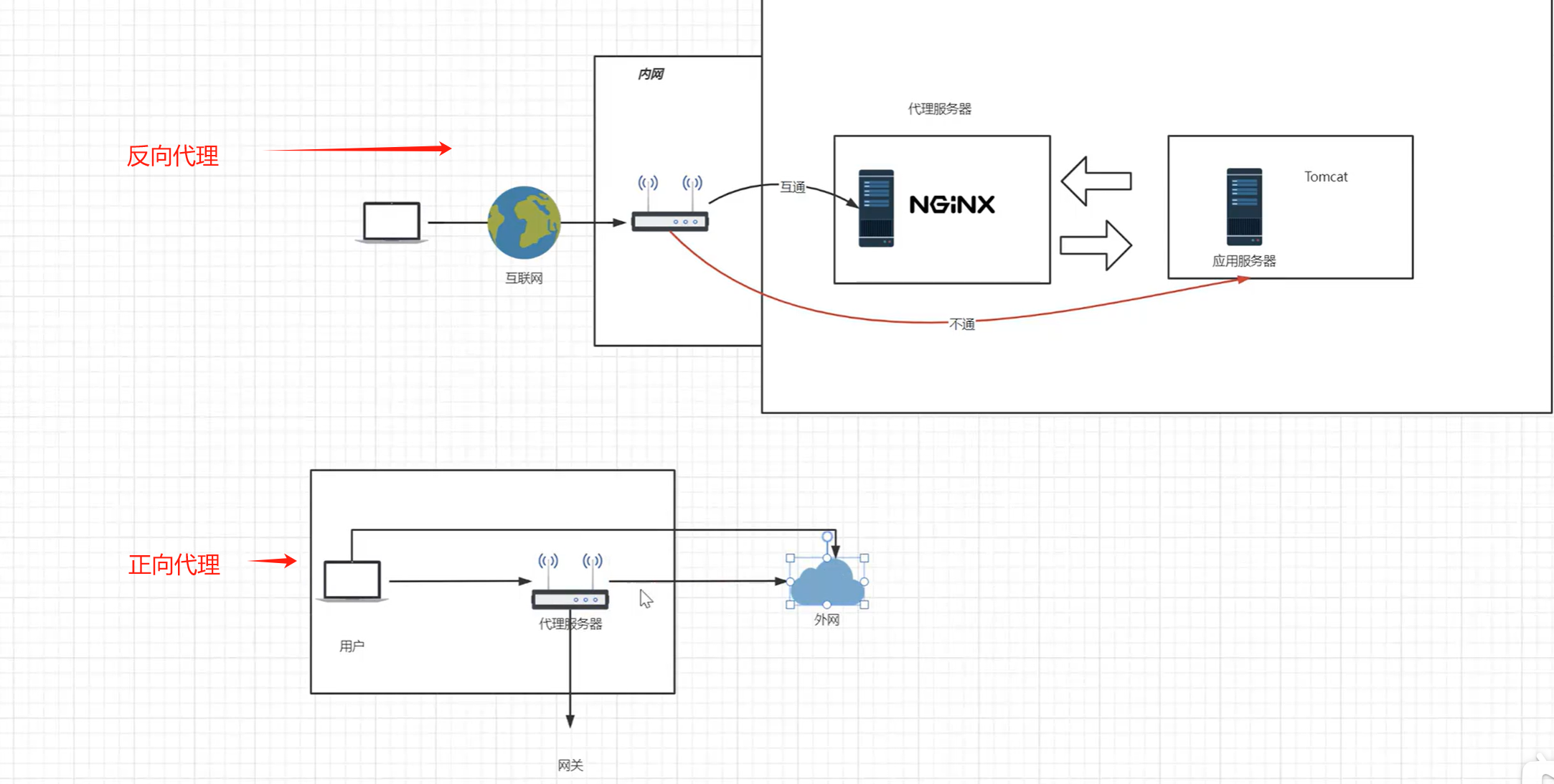
国外大模型
| 模型 | 技术架构 | 优势 | 劣势 |
| GPT系列(OpenAI) | 性能卓越,具备强大的文本生成、对话理解、知识问答等能力,能够进行复杂的逻辑推理和代码生成。 | ||
| Claude系列(Anthropic) | 整体性能强劲,尤其在语义理解和作为智能体的能力评测中表现突出 | ||
| Gemini系列(谷歌) | 原生多模态大模型,多模态能力、跨模态能力取得突破 | ||
| LLaMA系列(Meta) | 塑造了庞大的开源模型家族,LLaMA3能力大幅提升 | ||
| Bard(谷歌) | 擅长多模态信息的综合理解和分析,能够处理文本、图像、音频等多种类型的数据 | ||
国内大模型
| 模型 | 技术架构 | 优势 | 劣势 |
| 文心一言(百度) | 善于生成高品质的文章,能为创作者在内容创作方面提供智能助力,其翻译功能在国际教育交流中也有出色表现 | ||
| 讯飞星火(科大讯飞) | 语音识别技术在课堂录音、语音助手以及口语练习方面优势明显,可有效提升学生的口语水平和学习效率 | ||
| 通义千问(阿里巴巴) | 支持多模态数据处理、智能问答以及个性化学习路径推荐等教育应用场景 | ||
| Kimi模型(Moonshot AI) | 在自然语言处理领域表现出色,擅长情感分析和文本分类任务 | ||
| 豆包大模型(字节跳动) | |||
| 智谱ChatGLM系列(清华大学) | |||
| 日日新SenseNova(商汤) | |||
| DeepSeek-V3(深度求索) | 6710亿参数的混合专家架构,包含256个专家,每次选取前8个专家参与计算 | 训练成本仅为557.6万美元(其他主流大模型如GPT-4o等数亿美元训练成本) | |