你好呀,我是歪歪。
前几天打开知乎的时候,在付费咨询模块,我看到了一个差不多两年半前没有回答的技术问题。

其实这个问题问的很清晰了,但是当时我拒绝了:

虽然过去快两年半的时间,但是我记得还是比较清楚,当时拒绝的理由是如果让我来回答这个问题,我肯定是首选基于 Redis 来做。
大家想到排行榜一般也会首先想到 Redis。
所以为了不让这个咨询的朋友浪费钱,我想先进一步了解一下他们是否考虑过 Redis 的方案。
如果考虑过,但是发现不符合他们的业务场景,来我这里问,我还是建议他们用 Redis,这不就是浪费钱了。
如果没有考虑过,我先提示一下这个方案,可以先去调研一下。
然后,他可能是去调研方案去了,就没有回来补充问题,所以这个问题一直是拒绝状态。
既然时隔两年半,又让我看到了这个问题,那我准备还是来盘一下。
前面问题以及非常清晰了,从背景、现状、问题、诉求这四个维度进行了描述,然后还配了一张图,我把图单独拿出来给你看看:
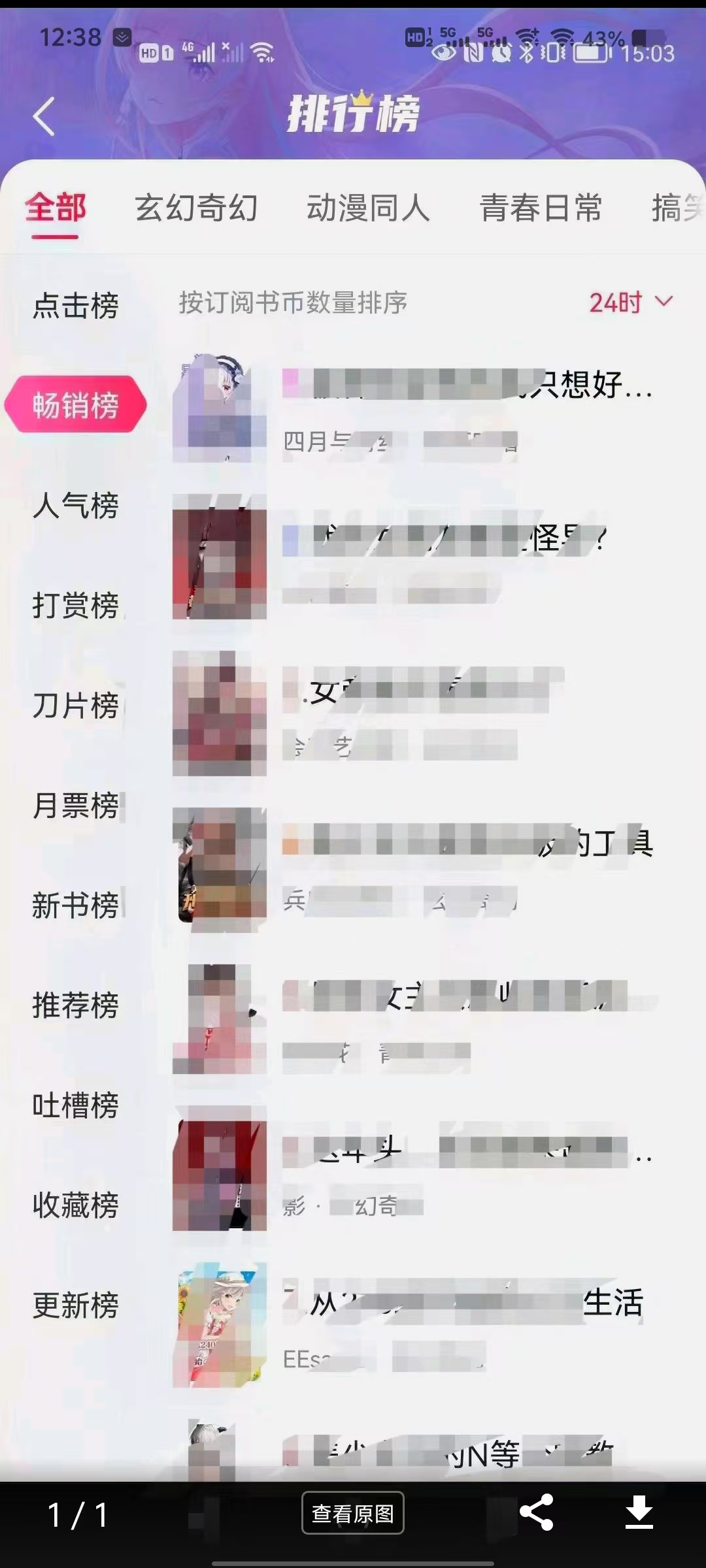
图片中显示了不同维度小说的榜单,例如点击榜、畅销榜、人气榜等,同时按分类,比如玄幻奇幻、动漫同人等。右上角还有一个“24 小时”,所以还有一个时间维度。
和提问者描述的内容一致。
现在想要将单次查询从 500 毫秒优化到 100 毫秒以下。
来吧,你先闭着眼睛,翻翻自己背过的八股文,想想有没有啥解决方案。
一会我们对对答案。

优化
MySQL 方面
由于目前是基于 MySQL 做的,那我们先从 MySQL 的角度去回答一下。
提到 MySQL,大家最直观的一个反应肯定是:索引。
在这个场景中,索引肯定是加了的,只是额外提醒一下,遇到 MySQL 的问题,首先我们都会考虑从索引的角度去看看有没有优化空间,因为这是投入最少,收益最大的一个角度。
比如,基于现状我要查询玄幻奇幻、畅销榜前十的小说,对应的 SQL,我猜测大概应该是这样的:
SELECT
*
FROM
books_sales
WHERE
category = '玄幻奇幻'
AND date = '某一天'
ORDER BY
sales_count DESC
LIMIT 10;
那肯定要在 category、date、sales_count 上加一个索引的。
另外,也别 SELECT * 了,要啥取啥,SELECT book_name,sales_count 就行了,能节约一点是一点。
现在的数据量只有 120w,确实不大,甚至对于 MySQL 来说,有点少。
但是为了考虑到后期的发展,可以先做垂直分表,而且这个业务场景简直就是和垂直分表非常匹配了。
比如根据书籍分类(玄幻、仙侠等)对数据进行垂直分表,即一个分类一个单独的表,每个表结构相同,但存储不同分类的数据。
这样的好处是可以减少单表数据量,查询玄幻类书籍时,不会涉及其他分类的数据。数据量少了,配上合理的索引,查询速度不就上去了吗。
这样应该能顶上相当长一段时间了,如果再因为数据量出现性能瓶颈,就可以进一步考虑分库。
然后还可以基于时间维度,做一个水平分表。分出日数据表、周数据表、月数据表。
数据库层面大概也就是这些手段了。
程序方面
这种排行榜,肯定是不需要实时生成的。
数据可以提前准备好,比如在白天准实时维护每本小说的点击量、打赏量等。
从提问者的描述来看,他们确实也是基于 MQ 来这样做的。
数据在日间准备好了,然后 0 点一过,就可以起一个定时任务,把各个维度、各个时段的排行榜算出来。
然后往 Redis 中一放,白天查询的时候就去 Redis 里面查询,不用走数据库了。
在 Redis 能命中缓存的情况下,别说 100ms 了,10ms 那也是手拿把掐的事儿啊。
定时任务跑的时候你也别一个个的去处理,多线程用起来,同时查询多个维度的排行榜结果。
最大化的减少定时任务维护排行榜的时间。
另外,页面上这么多类型的小说、每个类型下这么多分类、每个类型的每个分类又有多个时间维度,这一套组合拳下来,得有多少个排行榜了?
这么多排行榜,我就不信了每个都会有人去点?
所以,这里面还有一个优化空间,只维护用户查看率较高的排行榜,节约性能,缩短时间。
如果真的有冷门的排行榜被点到了,从 MySQL 里面实时计算一把,问题不大。
Redis
使用 Redis 来优化排行榜的实现,主要思路是利用 Sorted Set 这个数据结构。
Sorted Set 支持快速的范围查询、排序和分页,非常适合排行榜场景。
那么怎么去设计 key 和 value 呢?
key,以分类和统计维度作为键名的标识。比如:
rank:click:玄幻:24h rank:vote:仙侠:week
value 由 Score 和 Member 组成。
Score:根据排行榜维度(如点击数、月票数等)存储累计值。
Member:就是书的唯一标识,比如 book_id。
其实我觉得 Redis 做排行榜,最关键的就是 key value 的设计,其他的主要是考察的 Redis 命令使用情况了。
比如,Sorted Set 的操作函数,一共有 32 个:
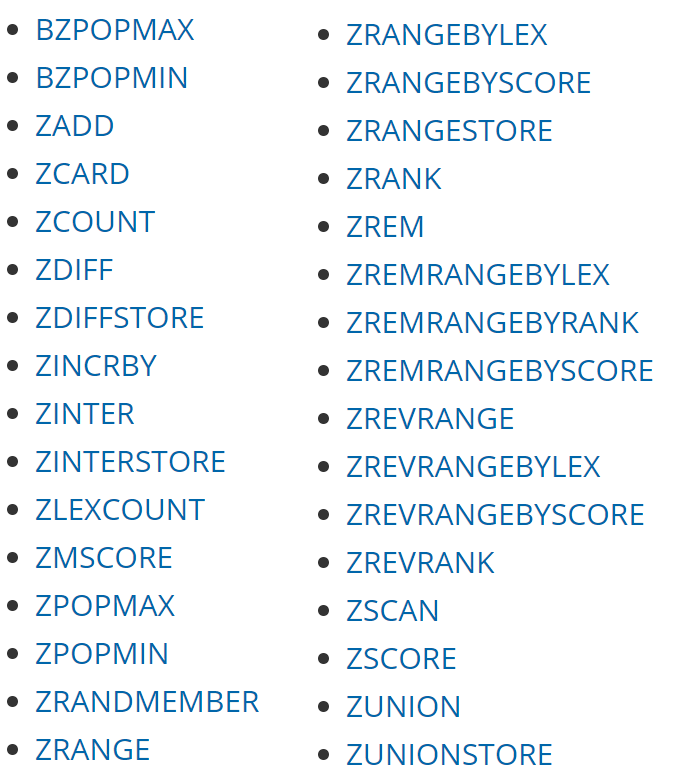
我这里就不一个个的做 API 教学了,官网上已经写的很清楚了,如果对于不熟悉的命令,可以去官网上查看,都是有示例代码的。
我曾经也写过两篇关于 Redis 做排行榜的文章,有一定的参考性:
《凉了呀,面试官叫why哥设计一个排行榜。》 《排行榜续集》
回到我们的场景下,简单的说几个常用的命令。
当书籍的某个维度数据变化时(如点击或月票),通过以下命令更新 Redis 中对应的 Sorted Set:
ZINCRBY rank:click:玄幻:24h 1 book_id_123
ZINCRBY rank:vote:仙侠:week 5 book_id_456
获取 24 小时维度的前 10 名:
ZREVRANGE rank:click:玄幻:24h 0 9 WITHSCORES
获取指定书在某个榜单中的排名:
ZREVRANK rank:click:玄幻:24h book_id_123
摊牌了
你再看看这篇文章的标题:《用 2025 年的工具,秒杀了 2022 年的题目。》
所以,摊牌了。
写这篇文章的时候,我大量使用了 ChatGPT 最基础最基础的功能来辅助我:





前面说了,这个问题是差不多两年半前提出来的,2022 年 5 月 12 日:
当年提问的时候,ChatGPT 还没出来,大家对于 AI 都还仅仅停留在概念的维度。
如果当时有这个神兵利器,我就直接让提问者把问题扔给 ChatGPT 就行了,还费劲给钱问我干啥。
不知道你是否还记得 ChatGPT 大概是什么时候出来的。
但是歪师傅记得特别清楚:2022 年 12 月左右。
当年还写了一篇文章蹭热点:《这玩意也太猛了!朋友们。我在此严正呼吁大家:端好饭碗,谨防 AI!》
现在来看,这也不算是标题党了,这玩意确实猛。确实是踢翻了一部分朋友的饭碗。
这篇文章的评论区中,有部分人站在当时的节点上,对于这个新鲜玩意的评价,现在来看,还真是“一语成谶”。
特别是这个评论:
当时我的回复是“我还是相信手动挡”。
现在来看,各个新能源汽车大厂都在大模型领域拼命厮杀,刹车逻辑确实变成了由大模型来控制了。
特别是百度旗下的“萝卜快跑”,已经在某些地方在一定程度上实现了 L3 级别的自动驾驶。
在自动驾驶领域,仅仅两年半的时间,也是完全走入了另外一片天地。
现在 AI 几乎已经是深入人心了,大家也从有一个模糊概念,变成了有一个具体的认知。
作为程序员来说,我觉得不一定非得站到风口浪尖上去当一个弄潮儿,但是我觉得至少应该全面拥抱 AI,面向 AI 编程。
这也是我个人与 ChatGPT 的一个和解吧。
这个“和解”从何而来呢?
在 ChatGPT 最开始问世的时候,我觉得它确实很厉害,感觉到了它对于程序员的一点威胁性。再后来随着关于这方面的消息关注的越多,看到关于它的消息越让我惊喜的同时也越让我焦虑。
焦虑来源于未知。
随着后面各类大模型相继问世,对于各类基于 AI 工具的运用越来越熟练,彻底消除了焦虑。
也用了一些宣传起来非常牛逼,但是实际用起来却非常拉胯的产品。
了解到的信息也越来越多,焦虑感也逐渐消退。
反而甚至开始抱怨:
更新啊!嘛呢?赶紧更新啊!放点大招出来让我玩玩啊。
好了,本文的技术部分就到这里了。
下面这个环节叫做[荒腔走板],技术文章后面我偶尔会记录、分享点生活相关的事情,和技术毫无关系。我知道看起来很突兀,但是我喜欢,因为这是一个普通博主的生活气息。
荒腔走板

前几年元旦这天我都会去跑步,今年按计划应该是要跑一个 20.25km,我一直也是按照这个计划准备的。
但是我在小红书上关注了几个天气博主,这几个天气博主都预测,元旦节前两天到元旦节整个川西都是大太阳,元旦节适合出行。
新年的第一天如果能干点不一样的就更好了。
于是提前一天临时决定,元旦翻过巴朗山,再上猫鼻梁观景台,去看四姑娘山。
一路上天气果然非常好,在服务器看到了 2025 年的第一个日出。过了都江堰,穿过隧道群后,蓝天就显出来了。
可能是只放了一天时间,大家都不愿意走远了,一路上都没啥车,非常畅通。边走边玩,到了猫鼻梁还不到 14 点,一算时间返程尚早。
于是又临时起意,往前再开一个小时,直奔夹金山垭口。

虽然我之前从来没去过夹金山垭口,但是我知道它长什么样子,过去的路上就像一个去过好多次的人一样,给 Max 同学它的样子。
当车子停在夹金山垭口的时候,算是在 2025 年的第一天,了却了我在大学时的一个小小的心愿。
能有这样的体验,完全得益于元旦放假一天。
上二天,休一天,再上二休二,这日子,真的是太有奔头了。