如何进一步做好信息收集
前言
前面一节介绍了一些信息收集的网站和工具,今天主要介绍一下如何进行半自动化的信息收集,全自动化的信息收集容易出现一些脏数据,而完全手工进行信息收集速率又太低,所以为了提高速率,我们需要充分利用一些脚本和工具
WHOIS半自动化收集
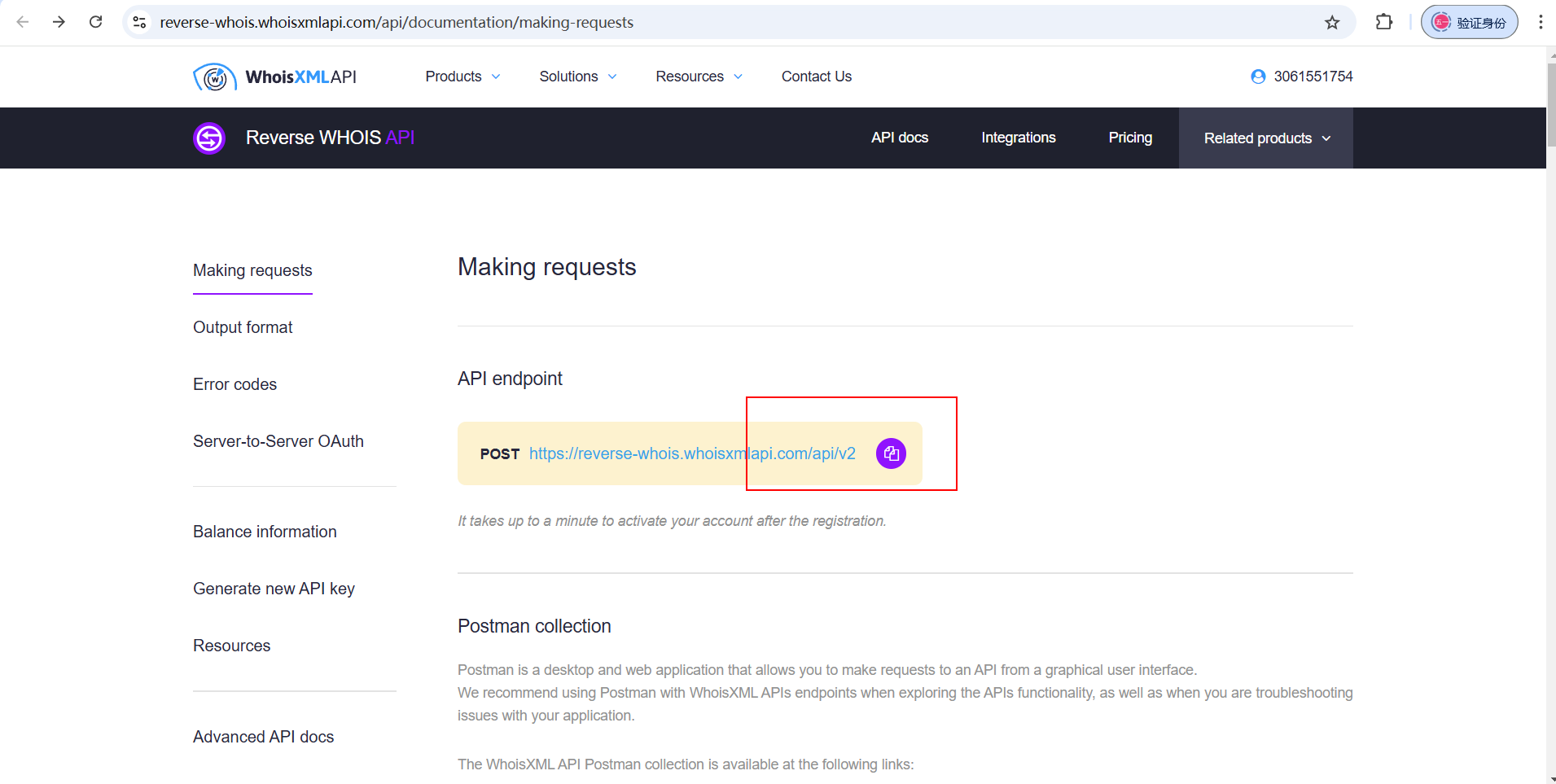
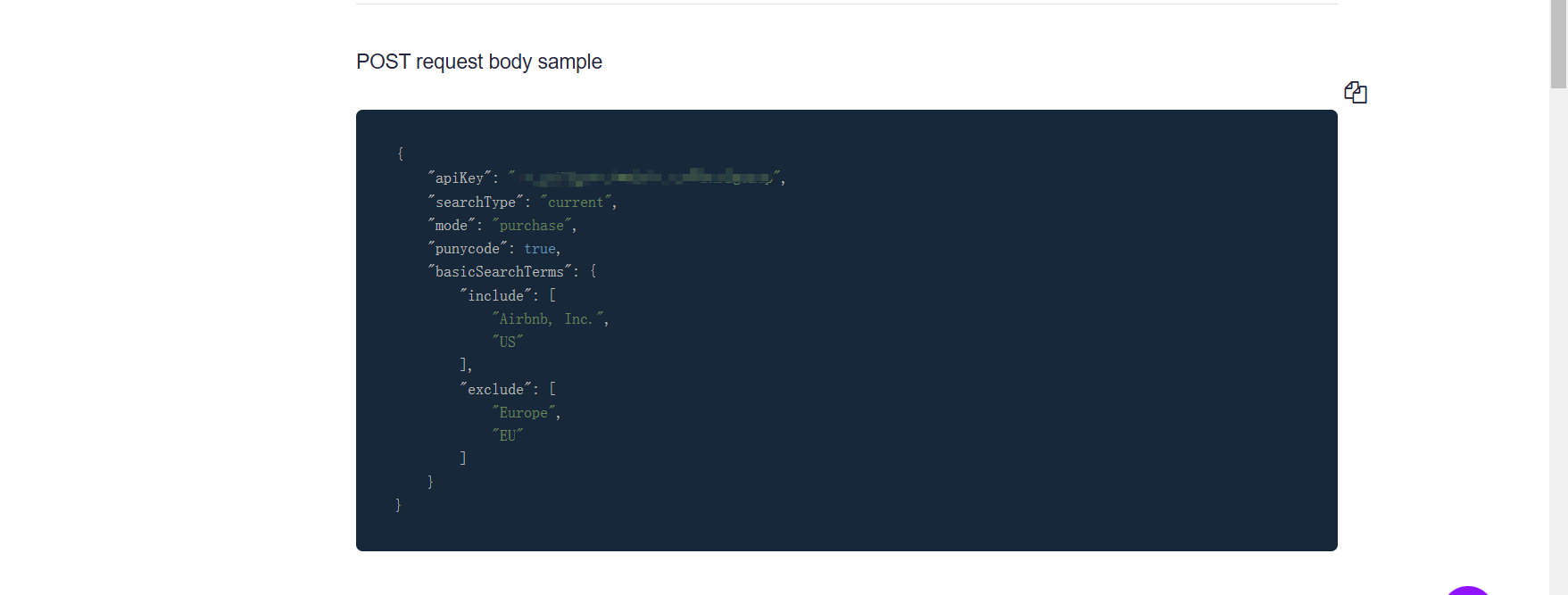
通过WHOIS网站https://reverse-whois.whoisxmlapi.com/api/documentation/making-requests来编写脚本
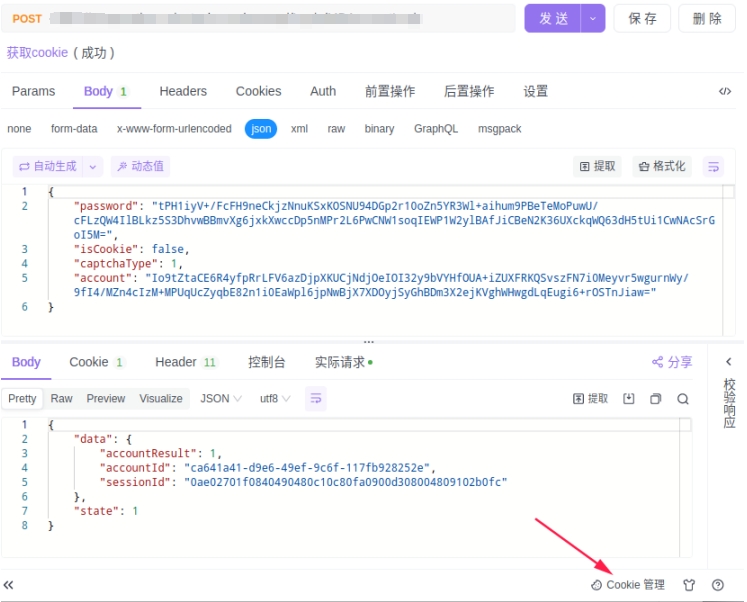
复制请求包后放到bp中,修改请求方法,并改为json格式
接着复制数据到数据包中
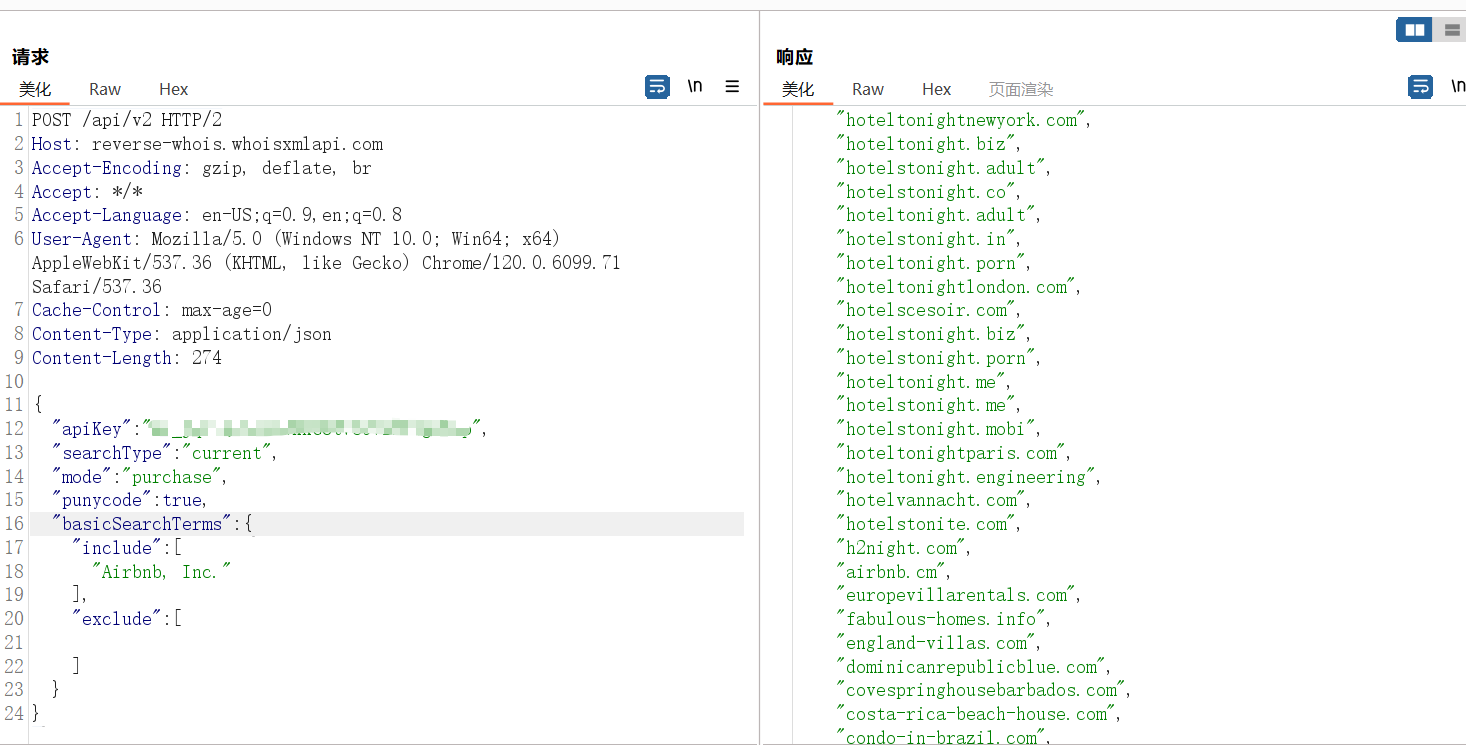
运行该脚本即可返回查询到的信息
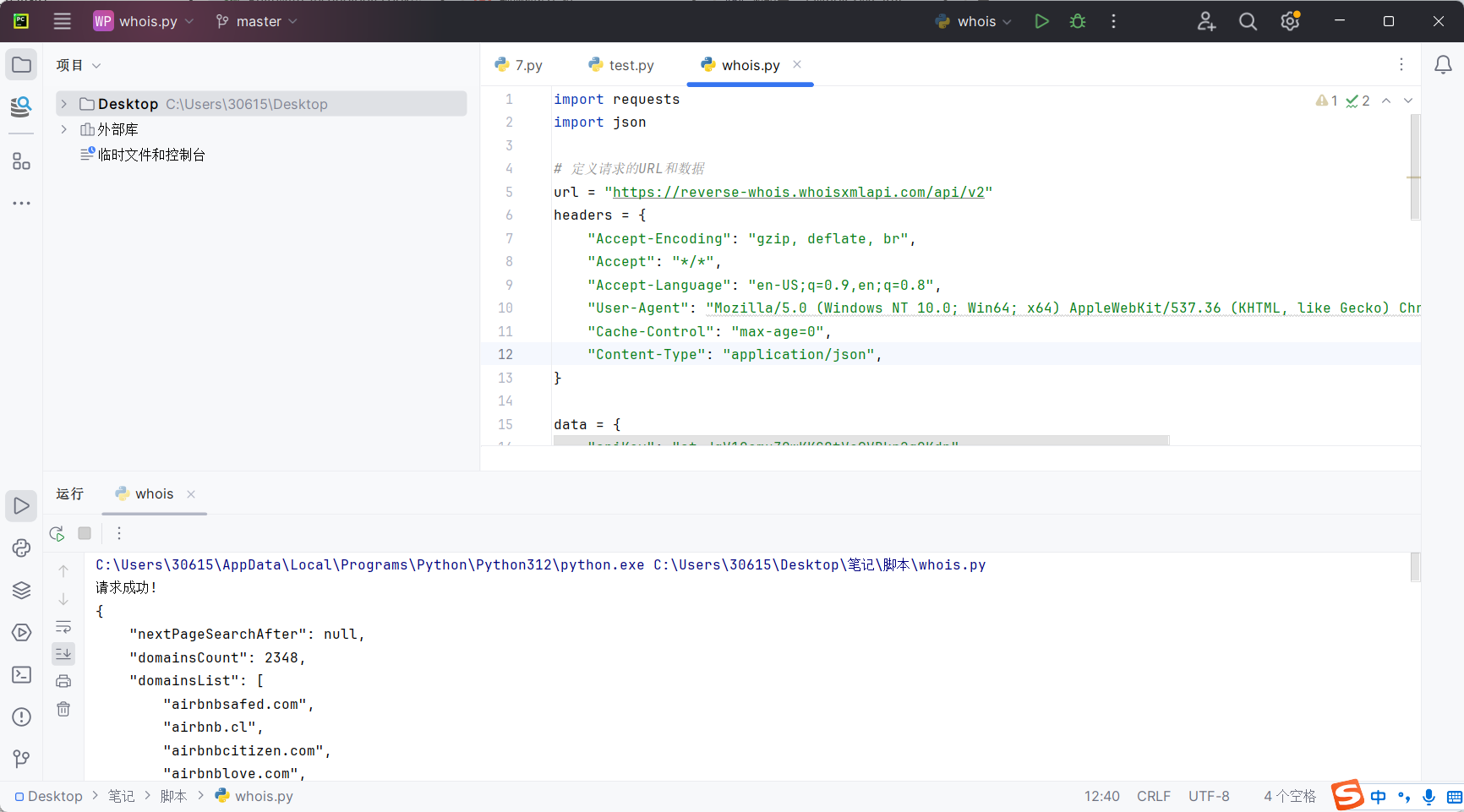
但显然这种程度还不够,我们需要提取域名到新的文本文件中
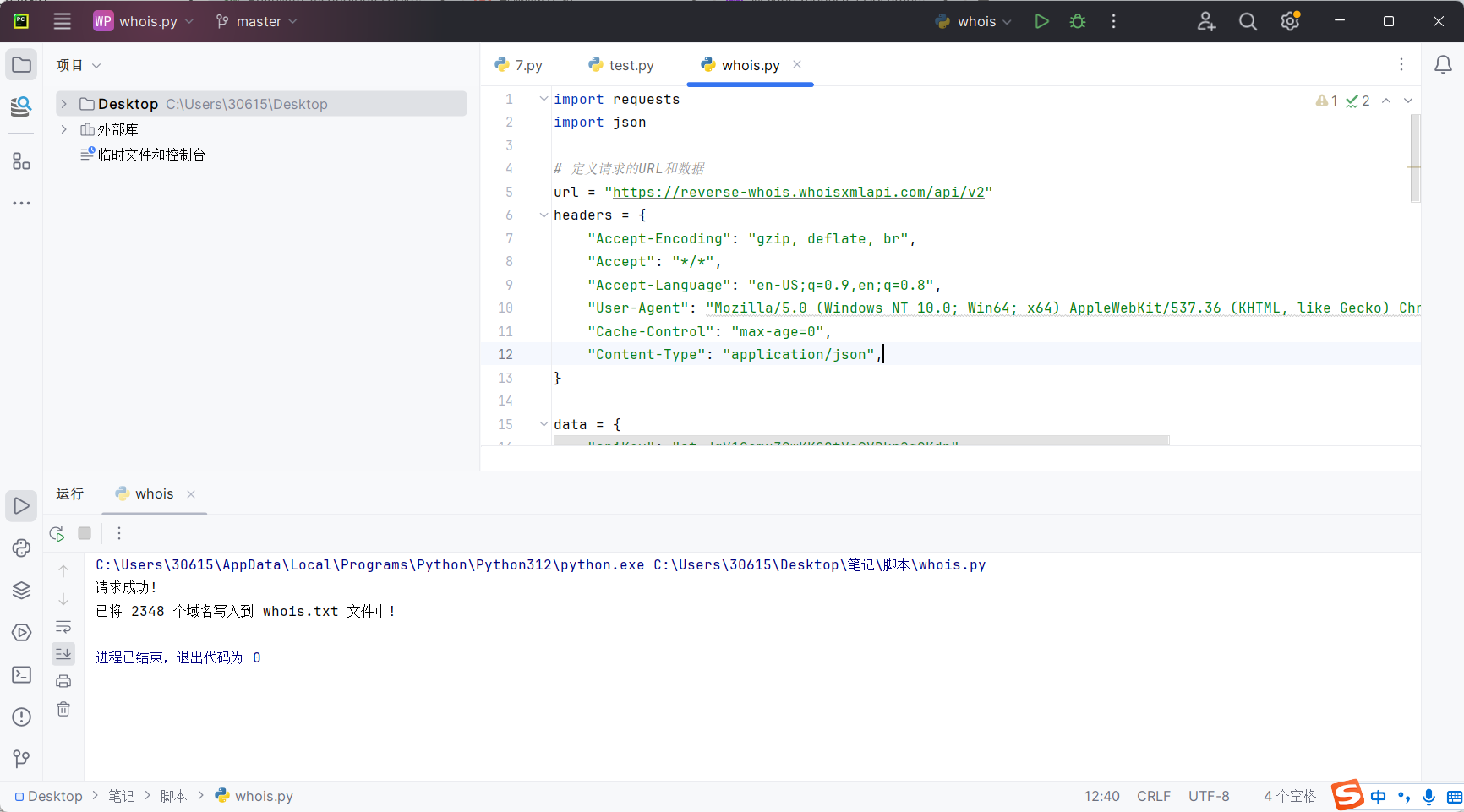
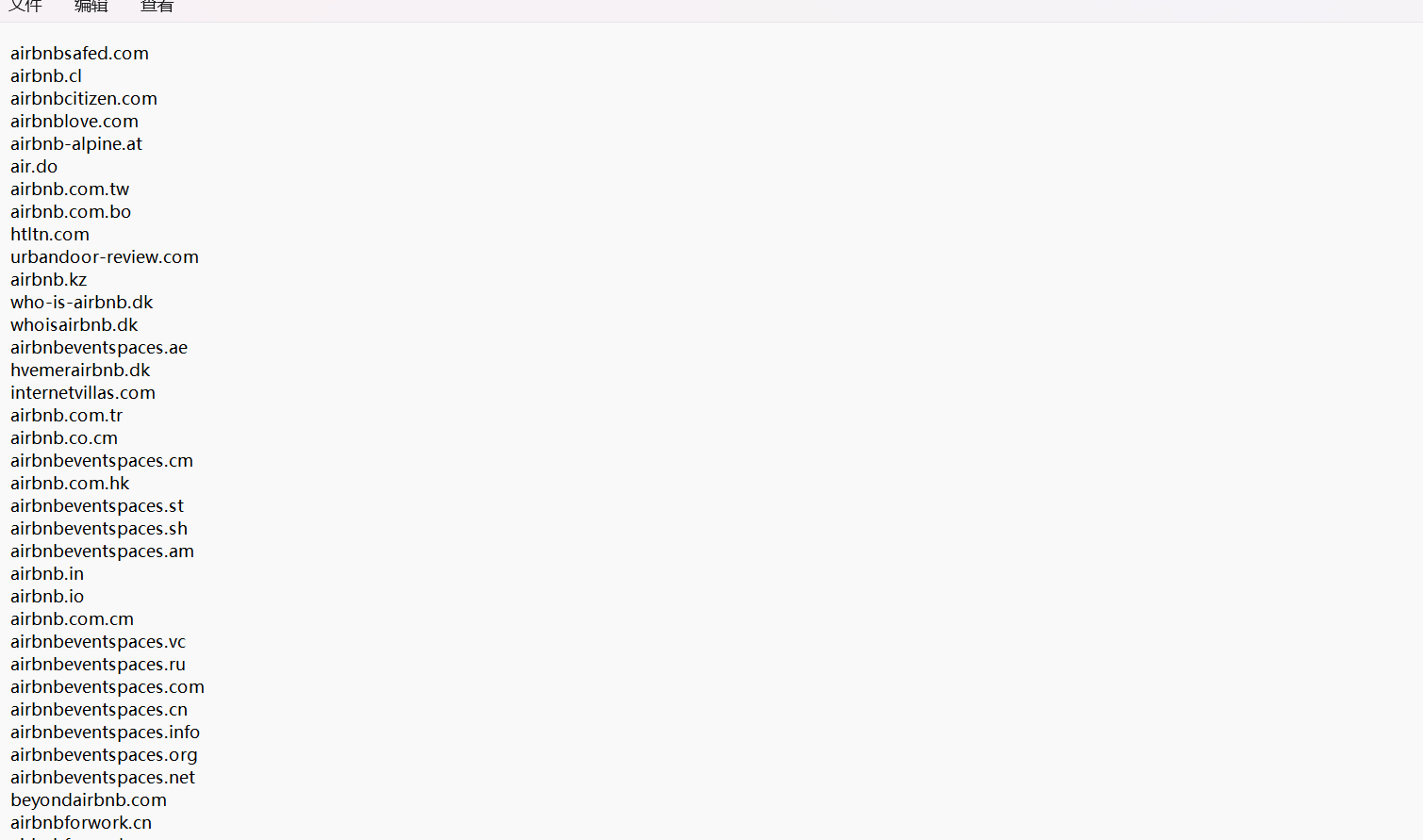
这样进行下一步测试时就会方便很多,那还能不能进一步优化呢,目前的代码来看,每次进行whois查询时,都要手动在脚本中进行组织名的更换,这样很不方便,于是便可以将组织名写一如一个新的文件中,每次从文件中提取组织名就方便很多,这边直接给出最后的脚本
import requests
import json# 定义函数从 orgs.txt 文件中读取内容
def load_organizations(file_path):try:with open(file_path, "r") as file:# 逐行读取文件内容,并去除空行和首尾空格organizations = [line.strip() for line in file if line.strip()]return organizationsexcept FileNotFoundError:print(f"错误:文件 {file_path} 未找到。")return []# 定义请求的URL和头部
url = "https://reverse-whois.whoisxmlapi.com/api/v2"
headers = {"Accept-Encoding": "gzip, deflate, br","Accept": "*/*","Accept-Language": "en-US;q=0.9,en;q=0.8","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.6099.71 Safari/537.36","Cache-Control": "max-age=0","Content-Type": "application/json",
}# 从 orgs.txt 文件加载组织名称
orgs_file_path = "orgs.txt"
organizations = load_organizations(orgs_file_path)if not organizations:print("没有组织名称可供查询,脚本退出。")
else:# 定义请求数据data = {"apiKey": "at_JqV1QomuZ0wKKG8tVc9VBkr2g0Kdp","searchType": "current","mode": "purchase","punycode": True,"basicSearchTerms": {"include": organizations,"exclude": []}}try:# 发送POST请求response = requests.post(url, headers=headers, data=json.dumps(data))# 检查响应状态if response.status_code == 200:print("请求成功!")# 解析JSON响应result = response.json()# 提取 domainsListdomains_list = result.get("domainsList", [])if domains_list:# 将 domainsList 写入到 whois.txt 文件with open("whois.txt", "w") as file:for domain in domains_list:file.write(domain + "\n")print(f"已将 {len(domains_list)} 个域名写入到 whois.txt 文件中!")else:print("响应中没有找到 domainsList 或其为空。")else:print(f"请求失败,状态码: {response.status_code}")print(response.text)except requests.RequestException as e:print(f"请求时发生错误: {e}")通过证书进行半自动化信息收集
这是我们正常访问网站进行查询的样子,我们需要的就是common name字段
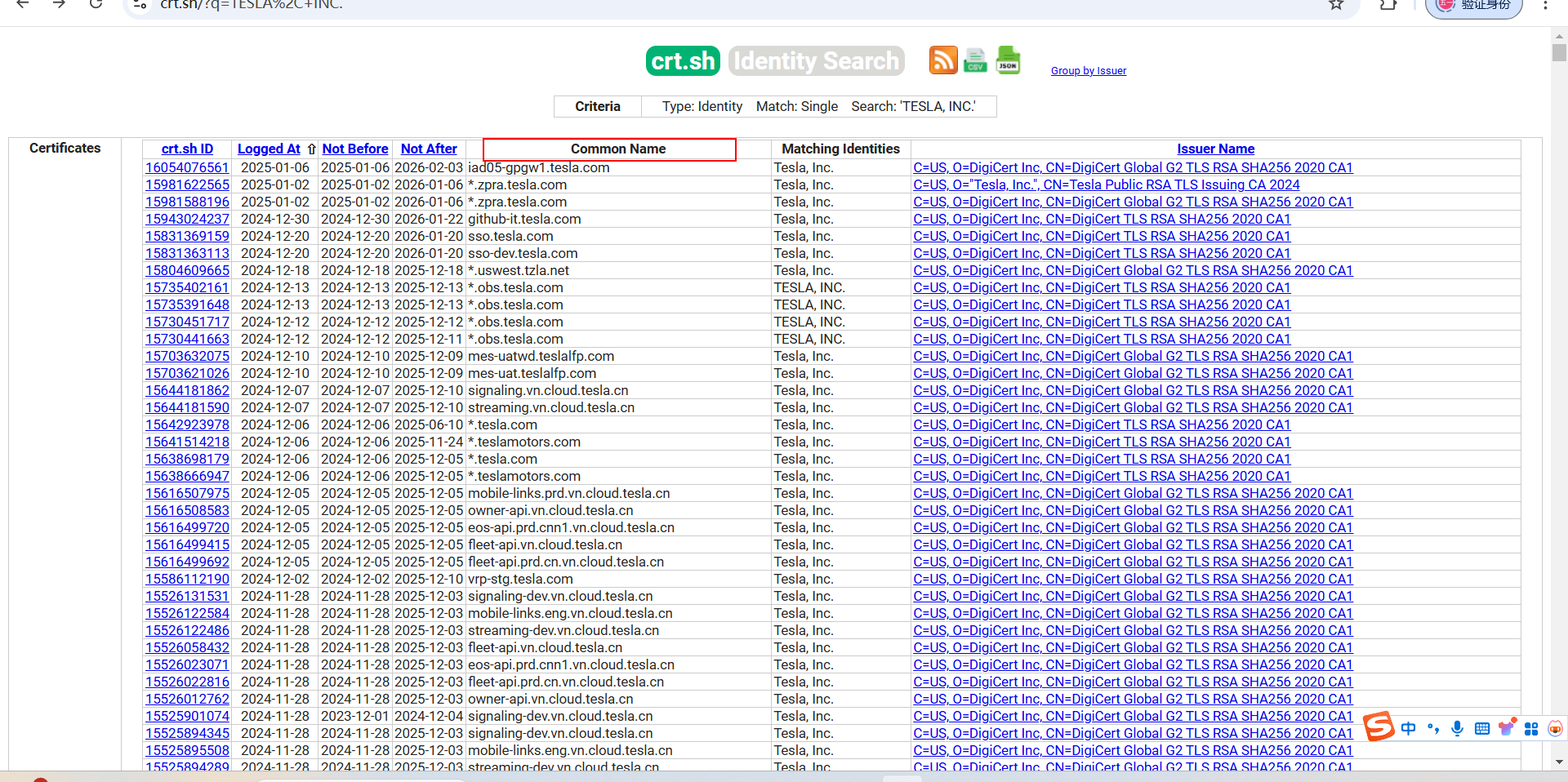

这样子提取common_name的值到cert.txt文件中去,但这同样也有一些问题:
1.并不是所有的common_name的值都是我们需要的域名,其中有一些是组织名和重复的,所以我们需要对结果进行进一步的提取和去重。
2.实际查询过程中会出现超时链接的情况,所以我们可以设置请求的超时时间,并进行重复请求几次
最后的脚本如下,结果会提取到cert.txt中
import requests
import tldextract# 定义请求的 URL 和参数
url = "https://crt.sh/"
params = {"q": "TESLA, INC.","output": "json"
}
headers = {"Accept-Encoding": "gzip, deflate, br","Accept": "*/*","Accept-Language": "en-US;q=0.9,en;q=0.8","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.6099.71 Safari/537.36","Cache-Control": "max-age=0"
}def extract_root_domain(domain):"""提取域名的根域名(例如,从 'www.example.com' 提取 'example.com')"""extracted = tldextract.extract(domain)if extracted.domain and extracted.suffix:return f"{extracted.domain}.{extracted.suffix}"return Nonedef fetch_data_with_retries(url, headers, params, max_retries=3, timeout=120):"""尝试请求数据,状态码不为200时重试,最多重试 max_retries 次"""attempt = 0while attempt < max_retries:try:response = requests.get(url, headers=headers, params=params, timeout=timeout)if response.status_code == 200:return responseelse:print(f"请求失败,状态码: {response.status_code}。尝试重新请求 ({attempt + 1}/{max_retries})...")except requests.RequestException as e:print(f"请求时发生错误: {e}。尝试重新请求 ({attempt + 1}/{max_retries})...")attempt += 1return Nonetry:# 尝试请求数据response = fetch_data_with_retries(url, headers, params)if response and response.status_code == 200:print("请求成功!")try:# 尝试解析 JSON 响应data = response.json()# 提取 common_name 中的域名并提取根域名domains = set() # 使用集合去重for entry in data:common_name = entry.get("common_name", "")root_domain = extract_root_domain(common_name)if root_domain: # 如果提取成功domains.add(root_domain)# 写入去重后的根域名到文件if domains:with open("cert.txt", "w") as file:for domain in sorted(domains): # 按字母顺序写入file.write(domain + "\n")print(f"已将 {len(domains)} 个根域名写入到 cert.txt 文件中!")else:print("没有找到有效的域名。")except ValueError:print("响应不是有效的 JSON 格式。")print(response.text)else:print("最终请求失败,无法获取数据。")except requests.Timeout:print("请求超时!请稍后重试。")
except requests.RequestException as e:print(f"请求时发生错误: {e}")合并
可以将两个脚本进行合并,进一步提高速率
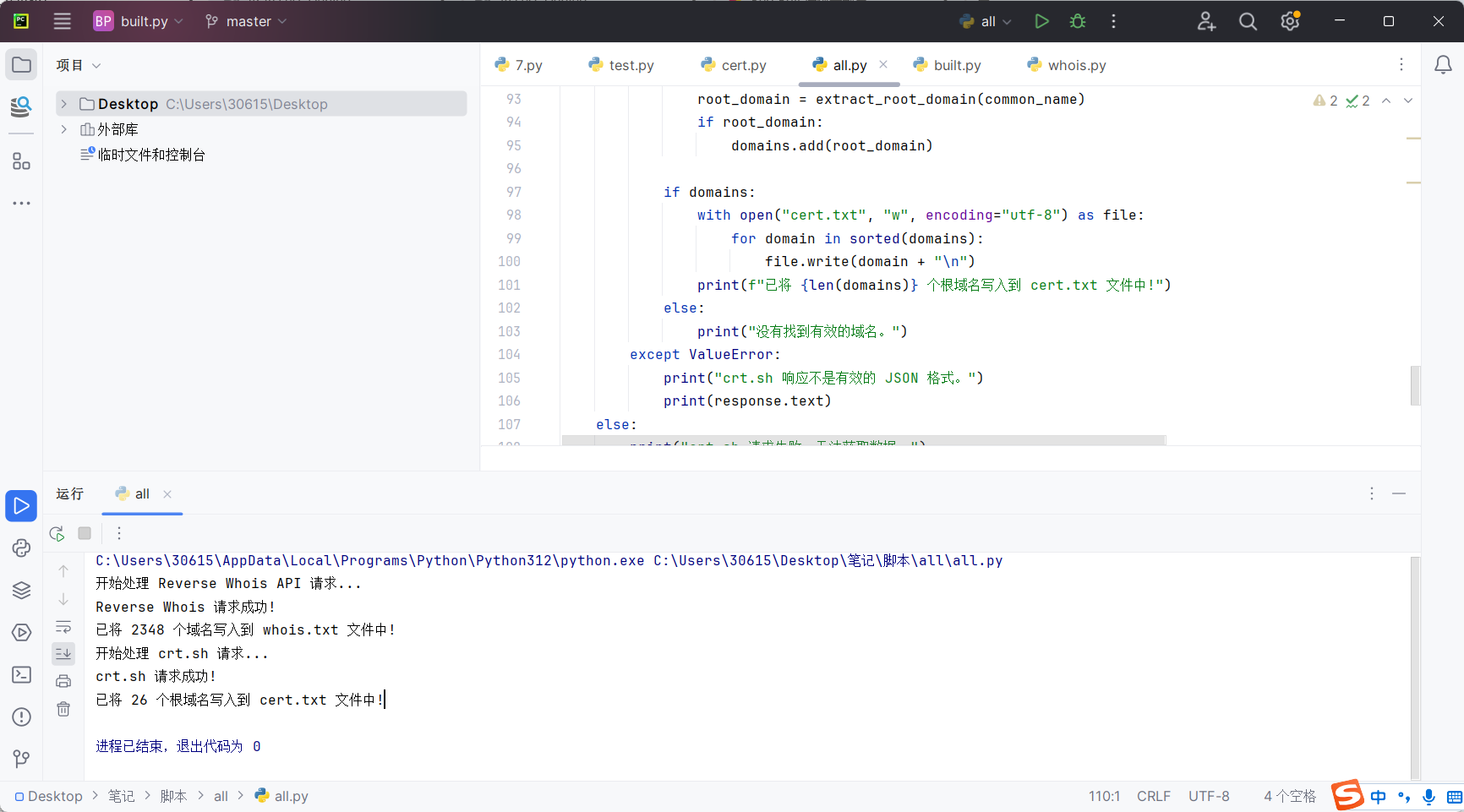
可以将两个输出文件也合并一下,并且去重
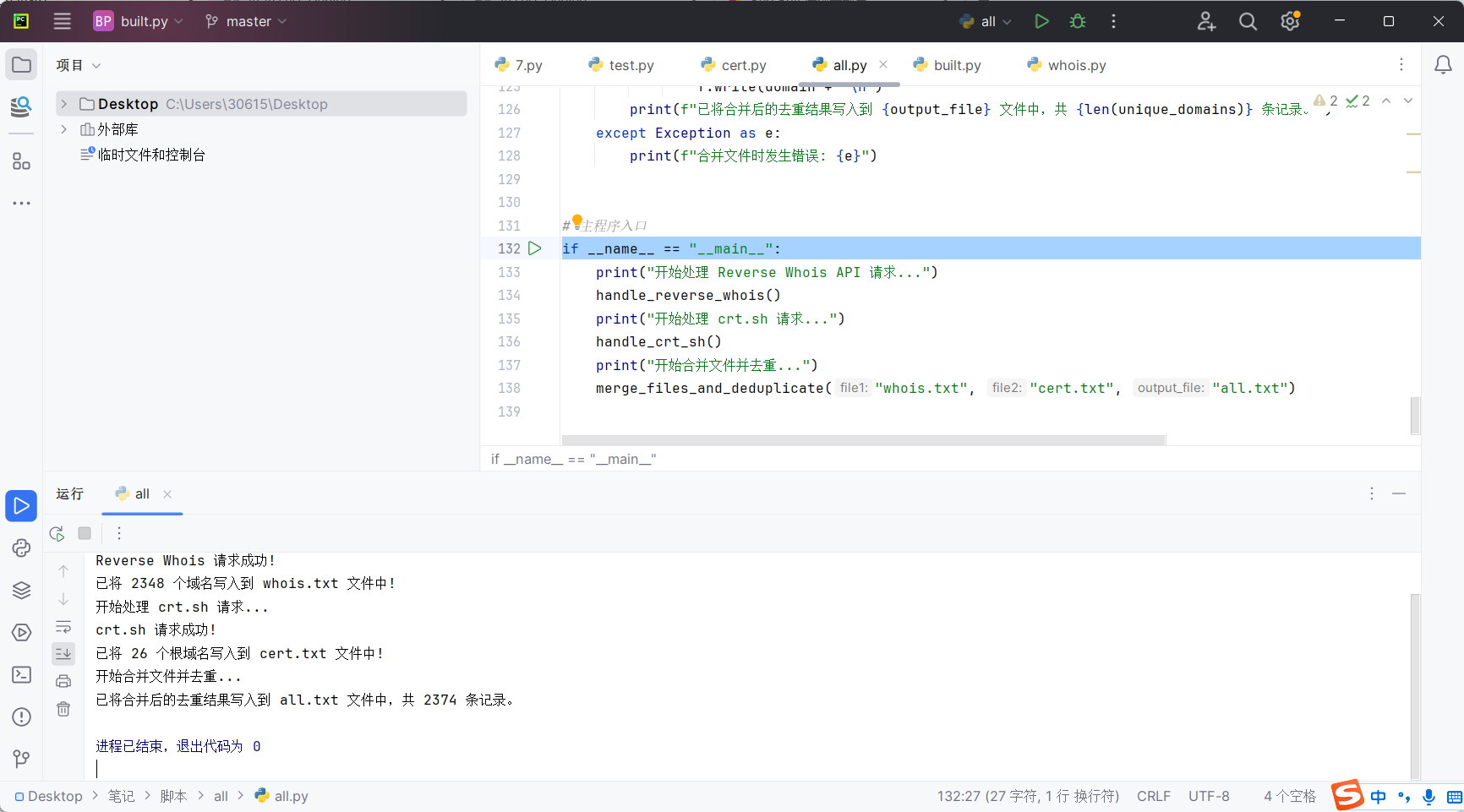
最后的代码如下
import requests
import json
import tldextract# 定义公共请求头
headers = {"Accept-Encoding": "gzip, deflate, br","Accept": "*/*","Accept-Language": "en-US;q=0.9,en;q=0.8","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.6099.71 Safari/537.36","Cache-Control": "max-age=0",
}# 提取根域名
def extract_root_domain(domain):"""从域名中提取根域名(如从 'www.example.com' 提取 'example.com')"""extracted = tldextract.extract(domain)if extracted.domain and extracted.suffix:return f"{extracted.domain}.{extracted.suffix}"return None# 发送请求并重试逻辑
def fetch_data_with_retries(url, headers, params=None, data=None, method="GET", max_retries=3, timeout=120):"""尝试请求数据,状态码不为 200 时重试,最多重试 max_retries 次"""attempt = 0while attempt < max_retries:try:if method.upper() == "GET":response = requests.get(url, headers=headers, params=params, timeout=timeout)elif method.upper() == "POST":response = requests.post(url, headers=headers, data=json.dumps(data), timeout=timeout)else:raise ValueError("Unsupported HTTP method.")if response.status_code == 200:return responseelse:print(f"请求失败,状态码: {response.status_code}。尝试重新请求 ({attempt + 1}/{max_retries})...")except requests.RequestException as e:print(f"请求时发生错误: {e}。尝试重新请求 ({attempt + 1}/{max_retries})...")attempt += 1return None# 任务1:处理 reverse-whois API 请求
def handle_reverse_whois():url = "https://reverse-whois.whoisxmlapi.com/api/v2"data = {"apiKey": "at_JqV1QomuZ0wKKG8tVc9VBkr2g0Kdp","searchType": "current","mode": "purchase","punycode": True,"basicSearchTerms": {"include": ["Airbnb, Inc."],"exclude": []}}response = fetch_data_with_retries(url, headers, data=data, method="POST")if response and response.status_code == 200:print("Reverse Whois 请求成功!")result = response.json()domains_list = result.get("domainsList", [])if domains_list:with open("whois.txt", "w", encoding="utf-8") as file:for domain in domains_list:file.write(domain + "\n")print(f"已将 {len(domains_list)} 个域名写入到 whois.txt 文件中!")else:print("没有找到 domainsList 或其为空。")else:print("Reverse Whois 请求失败,无法获取数据。")# 任务2:处理 crt.sh 请求
def handle_crt_sh():url = "https://crt.sh/"params = {"q": "TESLA, INC.","output": "json"}response = fetch_data_with_retries(url, headers, params=params, method="GET")if response and response.status_code == 200:print("crt.sh 请求成功!")try:data = response.json()domains = set()for entry in data:common_name = entry.get("common_name", "")root_domain = extract_root_domain(common_name)if root_domain:domains.add(root_domain)if domains:with open("cert.txt", "w", encoding="utf-8") as file:for domain in sorted(domains):file.write(domain + "\n")print(f"已将 {len(domains)} 个根域名写入到 cert.txt 文件中!")else:print("没有找到有效的域名。")except ValueError:print("crt.sh 响应不是有效的 JSON 格式。")print(response.text)else:print("crt.sh 请求失败,无法获取数据。")# 任务3:合并文件并去重
def merge_files_and_deduplicate(file1, file2, output_file):try:unique_domains = set()for file in [file1, file2]:with open(file, "r", encoding="utf-8") as f:for line in f:domain = line.strip()if domain:unique_domains.add(domain)# 写入去重后的结果with open(output_file, "w", encoding="utf-8") as f:for domain in sorted(unique_domains):f.write(domain + "\n")print(f"已将合并后的去重结果写入到 {output_file} 文件中,共 {len(unique_domains)} 条记录。")except Exception as e:print(f"合并文件时发生错误: {e}")# 主程序入口
if __name__ == "__main__":print("开始处理 Reverse Whois API 请求...")handle_reverse_whois()print("开始处理 crt.sh 请求...")handle_crt_sh()print("开始合并文件并去重...")merge_files_and_deduplicate("whois.txt", "cert.txt", "all.txt")