目录
一、NoSQL概述
1、数据的高并发读写
2、海量数据的高效率存储和访问
3、数据库的高扩展和高可用
二、NoSQL的类别
1、键值存储数据库
2、列存储数据库
3、文档型数据库
4、图形化数据库
三、分布式数据库中的CAP原理
1、传统的ACID
1)、A--原子性
2)、C--一致性
3)、I--隔离性
4)、D--持久性
2、CAP
四、Redis概述
五、Redis特点
六、Redis部署
一、NoSQL概述
NoSQL指非关系型的数据库,它可以作为关系型数据库的良好补充,在Web2.0网站的兴起,非关系型的数据库现在成为了一个极其热门的新领域,非关系数据库产品的发展非常迅速。传统的关系型数据库只能存储结构化数据,对于非结构化的数据支持不够完善。NoSQL数 据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。例如
1、数据的高并发读写
网站要根据用户个性化信息来实时生成动态页面和提供动态信息,所有基本上无法使用动态页面静态化技术,因此数据库并发负载非常高,往往要达到每秒上万次读写请求。例如网站的实时统计在线用户状态,记录热门帖子的点击次数。
2、海量数据的高效率存储和访问
像阿里、腾讯等大型网站的用户登录系统,在一张海量的关系数据库,使用SQL语句查找效率是极其低下的。
3、数据库的高扩展和高可用
基于Web网站的架构中,数据库是最难进行横向扩展的,当一个网页的系统的用户量不断增大,对数据库进行升级和扩展时,事很困难的,往往只有停机进行升级维护和数据迁移等。因此需要数据库具有高扩展和高可用性。
NoSQL数据库主要应用场景:
1). 数据模型比较简单
2). 需要灵活性更强的IT系统
3). 对数据库性能要求较高
4). 不需要高度的数据一致性
5). 对于给定key,比较容易映射复杂的环境
6). 取最新的N个数据(如排行榜)
7). 数据缓存
二、NoSQL的类别
1、键值存储数据库
这一种数据库类型主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。key/value模型对于IT系统来说优势在于简单,容易部署。
应用:内容缓存,主要用于处理大量数据高访问负载。
优点:快速查询。
缺点:存储的数据缺少结构化。
2、列存储数据库
这部分数据库通常事用来对分布式存储的海量数据,键依然存在,但是它们的特点是指向了多个列。
应用:分布式文件。
优点:查询速度快,可扩展性强,更容易进行分布式扩展。
缺点:功能相对局限。
3、文档型数据库
该类型的数据库模型是版本化的文档,半结构化的文档以特定的格式存储,入JSON。文档类型数据库可以看作是键值数据库的升级版,允许之间嵌套键值,而且文档型数据库比键值数据库的查询效率更高。
应用:Web应用。
优势:数据结构要求不严格。
缺点:查询性能不高,且缺乏统一的查询语句。
4、图形化数据库
图形结构的数据同其他行列以及刚性结构的SQL数据不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上,NoSQL数据库没有标准的查询语言(SQL),因此进行数据库查询需要定制数据模型。许多NoSQL数据库都有REST格式的数据接口或者查询API。
应用:社交网络。
优点:利用图结构相关算法。
缺点:需要整个图做计算才能得出结果,不容易做分布式的集群方案。
三、分布式数据库中的CAP原理
1、传统的ACID
关系型数据库遵循ACID规则,事务(transaction)
1)、A--原子性
指事物里所有操作要么都成功,要么都失败。事物的成功条件是事物中所有操作都成功,如果只要有其中一个操作失败,整个事物都失败,需要回滚。
2)、C--一致性
指数据库要一直处于一直的状态,事物的运行不会该百年数据库原本的一致性约束。
3)、I--隔离性
指并发的事物之间互不影响,如果一个事物要访问数据正在被另一个事务修改,只要另外一个事务未提交,它所访问的数据就不受未提交事务的影响。
4)、D--持久性
指事物一旦提交,它所作的修改将会永久的保存在数据库中,即使宕机也不会丢失。
2、CAP
CAP理论是指在分布式存储系统中,最多能实现上面得两点,由于当前网络硬件存在延迟丢包等问题,所以分区容忍性是我们必须要实现得,因此我们只能在一致性和可用性进行权衡,没有NoSQL系统能同时保证这三点。
C--强一致性、A--可用性、P--分区容错性
CA--单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。如传统的Oracle数据库。
AP-- 满足可用性,分区容忍性的系统,通常可能对一致性要求低一些如,大多数网站架构的选择。
CP--满足一致性,分区容忍必的系统,通常性能不是特别高,如Redis、Mongodb
注:在做分布式架构的时候必须做出取舍。 一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。因此一致性和可用性之间取一个平衡。对于大多数web应用,并不需要一致性。
四、Redis概述
Redis(REmote D Ictionary Server 远程字典服务器),是完全开源免费的,用C语言编写的,遵守BSD 协议,是一个高性能的(key/value)分布式内存数据库,基于内存运行,并支持持久化的NoSQL数据库, 是当前最热门的NoSQL数据库之一,也被人们称为数据结构服务器。
Redis是一个开源的高性能键值对(Key-Value)数据库。它通过提供多种键值数据类型来适应不同场景 下的存储需求,目前为止Redis支持的键值数据类型如下:
字符串类型、散列类型、列表类型、集合类型、有序集合类型。
五、Redis特点
- 性能极高:Redis 读的速度是 110000 次 /s,写的速度是 81000 次 /s 。
- 丰富的数据类型:Redis 支持二进制案例的 String,List,Hash,Set及 ZSet 数据类型操作。
- 原子性:Redis 的所有操作都是原子性的,意思就是要么成功执行要么失败完全不执行。单个操作 是原子性的。多个操作也支持事务,即原子性,通过 MULTI 和 EXEC 指令包起来。
- 数据持久化:可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用
- Redis 提供的API支持:C、C++、C#、Clojure、Java、JavaScript、Lua、PHP、Python、Ruby、 Go、Scala、Perl等多种语言。
- 其他特性:Redis 还支持 publish/subscribe 通知,key 过期等特性。
六、Redis部署
RMP包安装
1)获取安装包
[root@master ~]# wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
2)安装
[root@master ~]# yum install redis
3)启动redis服务器
[root@master ~]# systemctl start redis
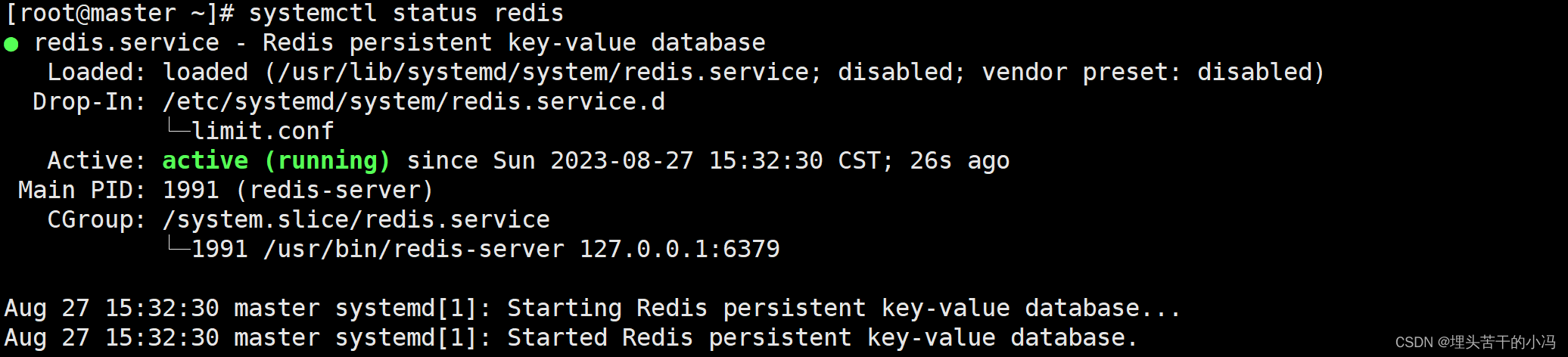
4)查看redis服务器状态
[root@master ~]# systemctl status redis
5)查看端口
注:redis的默认端口为6379
#方法一
[root@master ~]# netstat -lnupt | grep :6379
tcp 0 0 127.0.0.1:6379 0.0.0.0:* LISTEN 1991/redis-server 1
#方法二
[root@master ~]# ss -lnupt | grep :6379
tcp LISTEN 0 128 127.0.0.1:6379 *:* users:(("redis-server",pid=1991,fd=4))
#方法三
[root@master ~]# yum install lsof #需要先安装lsof
[root@master ~]# lsof -i tcp:6379
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
redis-ser 1991 redis 4u IPv4 22990 0t0 TCP localhost:6379 (LISTEN)
6)连接
[root@master ~]# redis-cli -p 6379
127.0.0.1:6379> ping #验证 出现PONG说明连接成功了
PONG
7)退出
127.0.0.1:6379> quit #或者exit
8)关闭服务
root@master ~]# redis-cli shutdown
[root@master ~]# ps -ef | grep redis #进行查看是否关闭
也可以在服务器里面关闭
127.0.0.1:6379> shutdown




![[uniapp] scroll-view 简单实现 u-tabbar效果](https://img-blog.csdnimg.cn/db1a990f5a4f4e8ebfd214b385f17c3b.png)