自然语言往往充满歧义和模糊性,模型在学习时可能会产生误解或错误理解一些概念,导致生成不准确的信息。为了尽量减少这些问题,研究人员和工程师会使用更大规模、更多样化和更准确的训练数据,调整模型架构,以及使用更先进的训练技术。但是自然语言本身就是复杂且充满挑战的,完全消除这些问题可能是非常困难的。所以,在使用大语言模型时,我们会发现它有时候会编造一些胡说八道的信息。


上述两个模型的回复信息都完全是虚假的,但模型会一本正经地给出回复,甚至介绍了实现原理。可见“胡说八道”是大语言模型的通病。甚至曾经有人在法庭文书中采用模型编造的虚假案例,造成了不良影响,当然这种状态正在持续改善。
为避免大语言模型回复虚假的信息,在与大语言模型交互时,如果你不确定某项事实或相关信息,可以要求模型先确认你所描述的是否是真实的,如果模型的知识中没有相关内容,它也不会继续编造回复。

我们看到这一次模型没有编造,然而,训练大语言模型的语料通常是有限的,而且这些语料从时效性来说,一般只包含数月前甚至一两年前的信息,同时模型一般也不会实时去收集互联网上的信息。所以模型不知道的事情,也未必就一定是不存在的,这件事情也许刚刚真实地发生了,只是模型还不知道。所以,当我们面临这种情况时,要小心谨慎地处理。你也可以在提示中明确要求模型在它不知道这件事情时坦诚地承认它不知道,然而在现阶段,不幸的是这似乎还有一定的难度,大多数模型会很好地否认相关信息,却不会轻易承认自己不知道,正如我们人类一样;同时幸运的是,已经有大语言模型坦率地承认自己认知有限。


总结一下,在与大语言模型交互时,如果不是在进行虚构写作,一旦涉及事实,特别是在我们对模型作出错误引导的情况下,我们特别需要小心求证,否则模型可能给我们的工作带来一场灾难。
大语言模型提示技巧(八)-防止胡说八道
更多文章访问https://gtyan.com
本文来自博客园,作者:光头颜,转载请注明原文链接:https://www.cnblogs.com/gtyan/p/18661092
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/866444.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
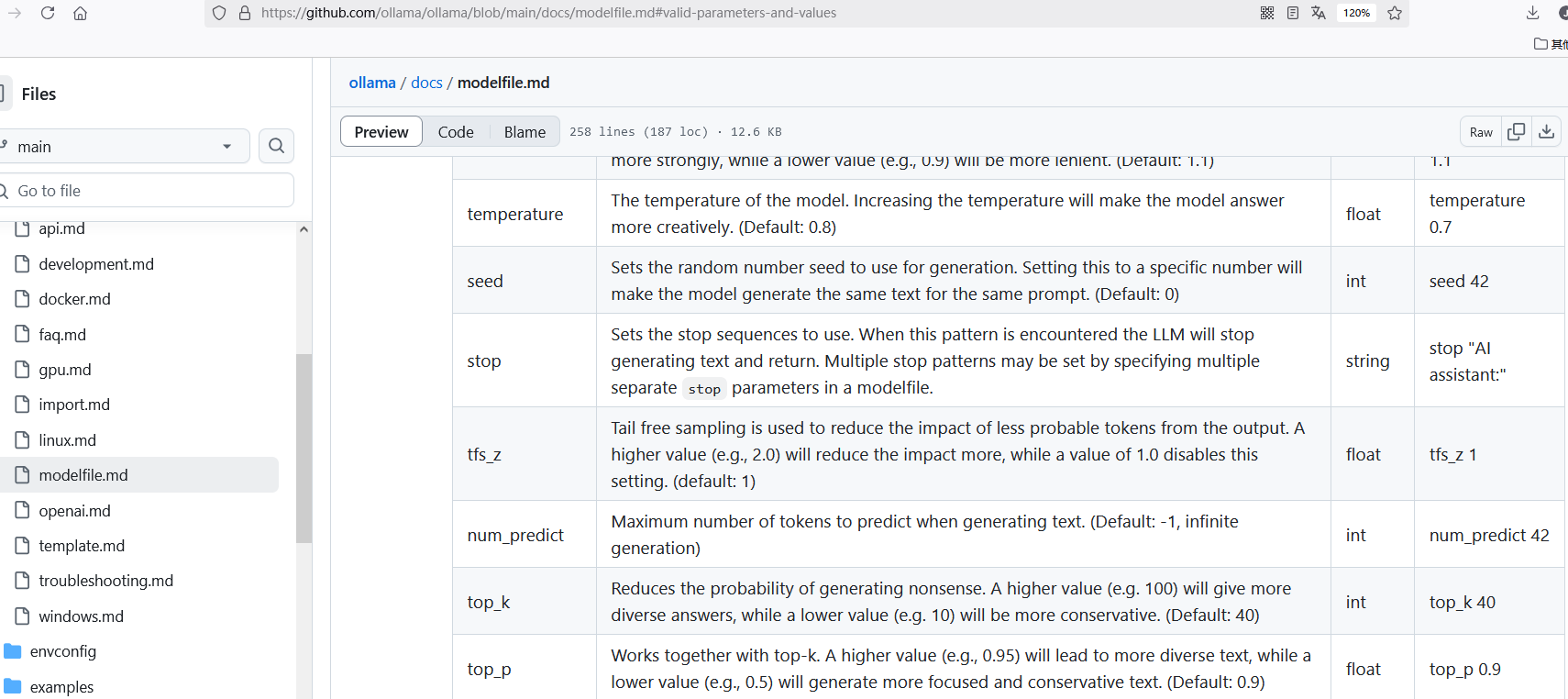
使用API方式远程调用ollama模型
在有GPU的环境启动一个ollama大模型,非常简单:注意,ollama启动时默认监听在127.0.0.1:11434上,可以通过配置OLLAMA_HOST环境变量修改
`export OLLAMA_HOST="0.0.0.0:11434"
ollama serve&
ollama run qwen2.5:7b-instruct`然后就可以在远端访问:
`curl http…

JMeter——压力测试工具的安装
JMetere 简介
jmeter 是 apache 公司基于 java 开发的一款开源压力测试工具,体积小,功能全,使用方便,是一个比较轻量级的测试工具,使用起来非常简 单。 jmeter 是免安装的,拿到安装包之后直接解压就可以使用,同时它在 linux/windows/macos 上都可以使用。
前提
已安装和…

微软开源!Office 文档轻松转 Markdown!
MarkItDown —— 微软开源的 Python 工具,能够将多种常见的文件格式(如 PDF、PowerPoint、Word、Excel、图像、音频和 HTML 等)转换为 Markdown 格式。大家好,我是 Java陈序员。
今天,给大家介绍一款微软开源的文档转 Markdown 工具。关注微信公众号:【Java陈序员】,获取…
人工智能(AI)在医学领域的应用 -九五小庞
人工智能(AI)在医学领域的应用是当前科技发展的重要方向之一,它通过提高医疗效率、准确性和个性化治疗水平,极大地改善了医疗服务的质量和患者的体验。以下是一些AI在医学领域的主要应用:辅助诊断医学影像分析:AI可以通过深度学习算法快速准确地分析CT、MRI、X光等医学影…

Ftrans汽车制造供应链管理方案,如何实现协同共赢?
汽车制造供应链管理是指对从供应商到客户的汽车产品、信息及资金流动进行集成管理的过程,旨在最大化供应链价值。在汽车制造供应链管理中,信息流扮演着至关重要的角色。它不仅是供应链各环节之间沟通协作的桥梁,也是确保供应链高效运作、降低库存成本、提升客户满意度的重要…

升级后手机版网站无法访问,可能的原因及解决方案
!在进行服务器或应用程序升级后,如果发现手机版网站无法访问,这通常是由于升级过程中某些配置发生了变化,导致移动端设备无法正确解析或加载网页内容。为了帮助您更好地理解和解决这个问题,以下是几个可能的原因及相应的解决方案:检查域名解析设置升级后,域名解析设置可…
如何解决批量主机升级未成功的问题?
如果您尝试对多个主机进行批量升级,但部分主机未能成功升级,可能是由多种原因引起的。以下是详细的排查步骤和解决方案:检查财务记录:首先,确保所有主机的升级订单已经成功支付。您可以登录到云服务提供商的控制面板,查看财务记录,确认每个主机的升级订单状态。如果存在…
游戏网站模板修改软件推荐
游戏网站通常需要独特的设计和功能来吸引玩家。有哪些推荐的模板修改软件可以帮助用户高效地修改游戏网站模板?
解决方案:选择合适的CMS平台:根据游戏网站的需求选择合适的CMS平台。常用的平台包括WordPress、DedeCMS等。这些平台提供了丰富的模板资源,方便用户快速搭建网站…
在宝塔面板上如何高效管理和修改网站配置以保障稳定运行
宝塔面板因其简洁直观的操作界面深受广大开发者喜爱,但对于初次接触的人来说,仍然可能存在一些困惑,特别是在涉及网站配置修改时。掌握正确的操作流程不仅可以提高工作效率,还能确保网站的安全性和稳定性。
解决方案安装必要组件:根据所使用的编程语言和技术栈,在宝塔面板…
使用PowerShell脚本获取并发连接数
PowerShell是微软提供的任务自动化框架,它提供了更高级的功能和更好的灵活性。利用PowerShell,我们可以轻松地获取并分析服务器的并发连接数。打开PowerShell:按下 Win + X 键,选择“Windows PowerShell (管理员)”选项启动具有管理员权限的PowerShell窗口。运行PowerShell…
服务器使用固态硬盘还是机械硬盘更合适?
在选择服务器硬盘时,固态硬盘(SSD)和机械硬盘(HDD)各有优缺点。为了帮助您做出最佳选择,我们将从容量大小、使用寿命和数据恢复三个方面进行详细分析。
一、容量大小硬盘类型
容量
价格固态硬盘 (SSD)
通常较小,常见容量为256GB、512GB、1TB等
较高,但价格逐渐下降机械…