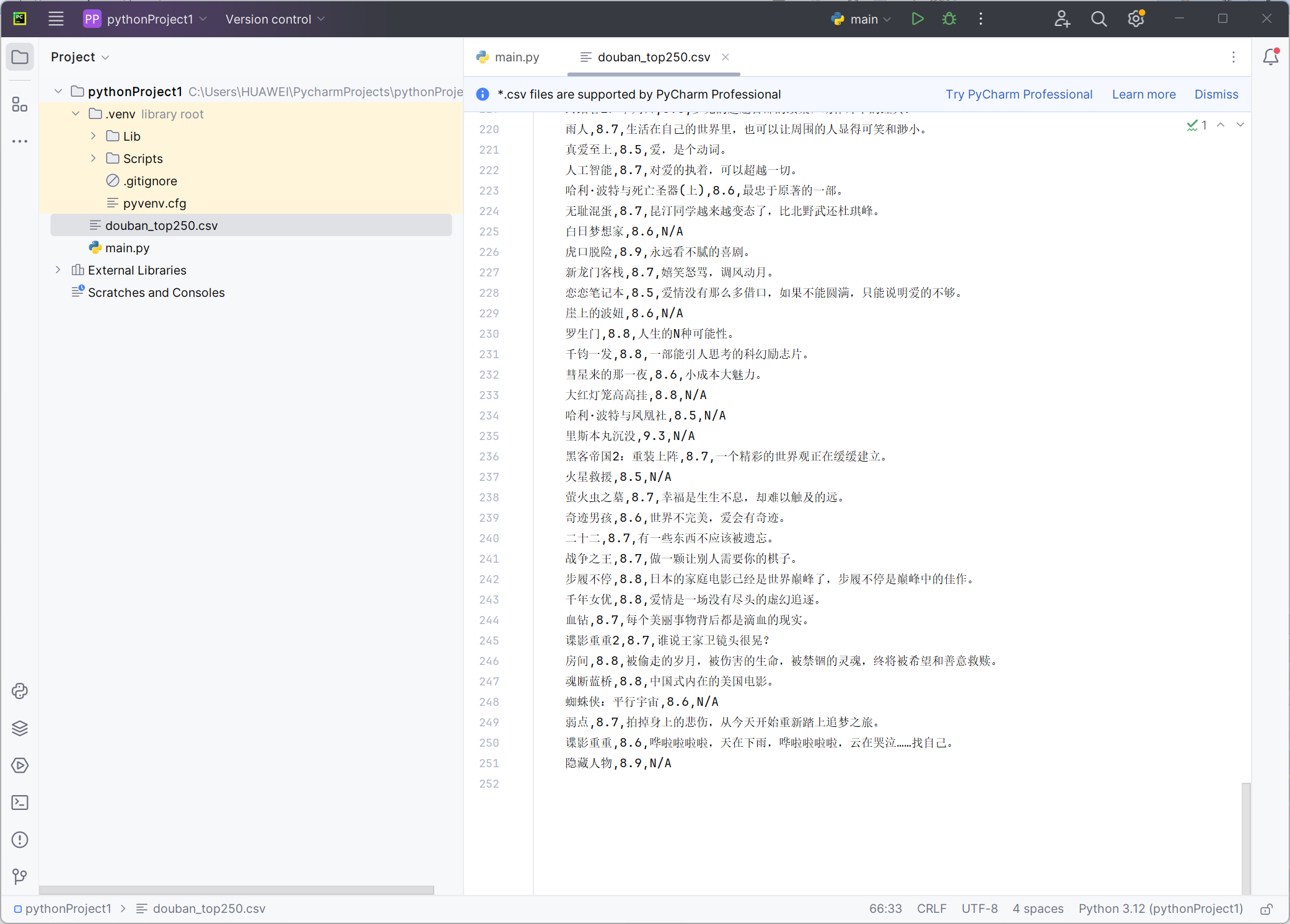
今天开始简单了解了python爬虫,并安装了相关依赖
import requests
from bs4 import BeautifulSoup
import pandas as pd
# 爬取一个页面的数据
def scrape_page(url):
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/96.0.4664.45 Safari/537.36"}
response = requests.get(url, headers=headers)
soup = BeautifulSoup(response.text, "html.parser")
movies = []
for item in soup.find_all("div", class_="item"):
title = item.find("span", class_="title").text
rating = item.find("span", class_="rating_num").text
quote = item.find("span", class_="inq").text if item.find("span", class_="inq") else "N/A"
movies.append({"Title": title, "Rating": rating, "Quote": quote})
return movies
# 主程序:爬取多页
def main():
base_url = "https://movie.douban.com/top250?start={}"
all_movies = []
for i in range(0, 250, 25): # 每页 25 部电影
url = base_url.format(i)
print(f"Scraping: {url}")
movies = scrape_page(url)
all_movies.extend(movies)
# 保存为 CSV 文件
df = pd.DataFrame(all_movies)
df.to_csv("douban_top250.csv", index=False)
print("Scraping complete! Data saved to douban_top250.csv")
if __name__ == "__main__":
main()
结果展示: