1、HBase是什么
HBase是基于HDFS的数据存储,它建立在HDFS文件系统上面,利用了HDFS的容错能力,内部还有哈希表并利用索引,可以快速对HDFS上的数据进行随时读写功能。

Hadoop在已经有一个Hive+MapReduce结构的数据读写功能,为什么还要HBase呢?我们在使用Hive的过程中也发现,MapReduce的过程很慢,不适合实时的读写访问,更多的时候是进行线下的访问。但在实际应用过程中,我们需要对大数据进行实时的读写,这时候HBase就派上用场。
HBase使用场景:
HBase适合在瞬间写入量大,大量数据需要长期保存,并且数量会持续增长的场景。但在多级索引和关系复杂的数据模型,还有跨行事务场景也不适合HBase。
2、HBase怎么工作
HBase基础架构

Client
- 与Zookeeper进行通信,获取数据入口地址;
- 与HMaster通信进行管理类操作;
- 与HRegionServer进行数据读写操作。
Zookeeper
- 避免单点问题,一直只有running master;
- 存储所有Region的地址,包括HMaster地址;
- 监控HRegionServer的状态,并告知HMaster;
- 存储Table名和Column Family
HMaster
- 有多个HMaster,通过Zookeeper保证有一个在运行;
- 为HRegionServer分类Region;
- 有HRegionServer失效,重新分配;
- 对HDFS的垃圾文件进行回收;
- 处理用户对表的增删改查操作;
HRegionServer
- HBase核心部分,负责I/O请求,并先HDFS读写数据;
- 维持HMaster分配的Region,并处理Region的I/O请求;
- 切分在运行过程中变大的Region;
- HRegionServer中有一系列HRegion对象,每个HRegion对应Table中的一个Region,每个HRegion由多个Store组成,每个HStore对应Table中的Column Family。
Column Family是HBase的存储单元,所以相同特性的Column放在一个Column Family更高效。
HStore
- HBase存储的核心,由MemStore和StoreFile组成;
HRegion
- 一个Table最开始的时候是一个Region;
- 一个Region可以有多个Store,每个Store用来存储一个Column Family;
- Region随着数据的越来越多,会进行拆分,由HRegionServer进行拆分,默认大小为10G。
HLog
- 备份和日志,在系统出错和宕机时,MemStore的数据会丢失,而HLog可以防止该情况。
HBase写数据流程

HBase数据模型
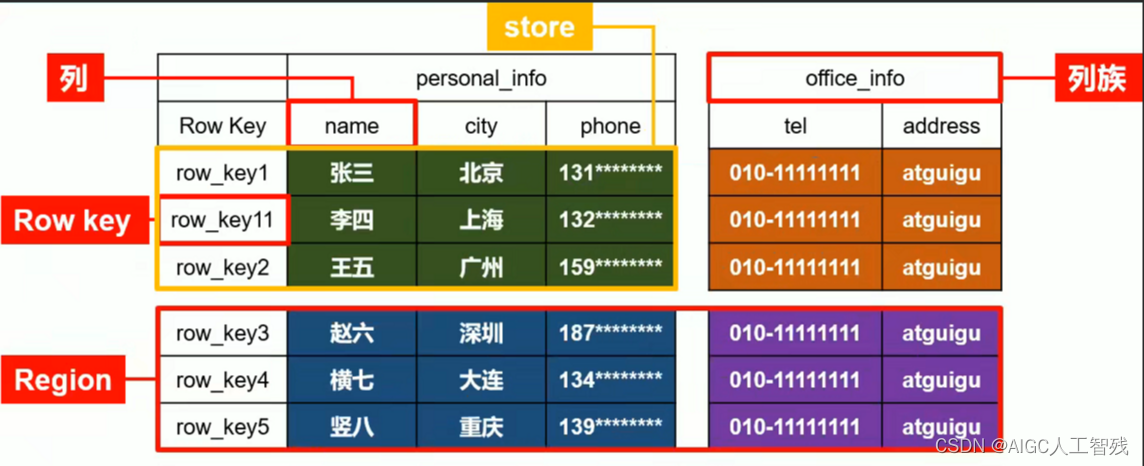
- NameSpace:数据库的库名;
- Table表:HBase的表,由于对于值为空的列不占空间,因此表可以比较稀疏;
- Row行:每一行都有一个RowKey来进行识别;
- RowKey行键:类似于MySQL中的主键,用来进行检索数据;
- Column列:由Column family和Column qualifier组成,两者用;进行间隔;
- ColumnFamily列族:列的集合,每个表的列族都以一个文件存储,一个表可以有多个列族;
- ColumnQualifier列标识:类似于键值对,key是RowKey,那么ColumnQualifier就是Value;
- TimeStamp时间戳:是具有时间属性的列,每个数据都有一个时间戳属性,也就是说数据具有版本特性;
- Region区域:HBase可以自动把表划分为多个区域,随着数据的增多区域也变多。
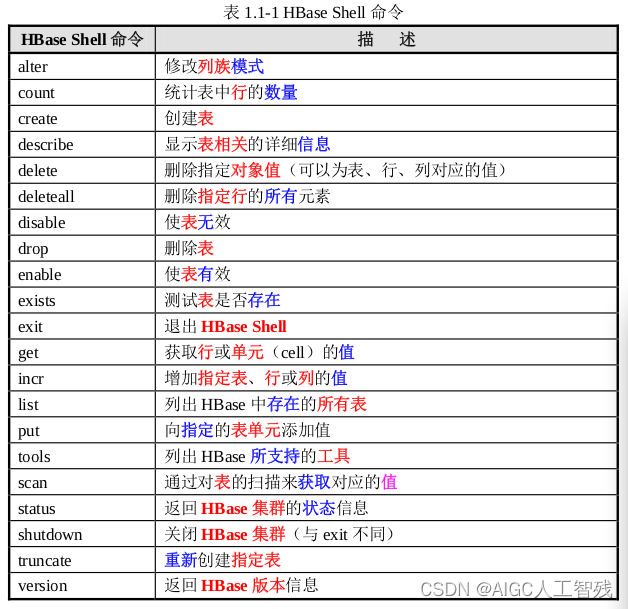
3、HBase的Shell操作
- HBase启动
找到zkServer.sh启动Zookeeper
zkServer.sh start
启动HBase
start-hbase.sh
- HBase常见Shell操作
连接集群
hbase shell
创建表
create 'user','base_info'# 第一个为表名,第二个为列族
删除表
disable 'user'
drop 'user'
创建数据库
create_namespace 'test' #test为数据库名
展示所有数据库
list_namespace
显示表
list
插入数据
put ‘表名’,‘rowkey的值’,’列族:列标识符‘,’值‘
put 'user','rowkey_10','base_info:username','Tom'
查询表中所有数据
scan 'user' # 很少使⽤全表查询 scan会加上⼀些条件限制
Scan查询中添加限制条件
scan '名称空间:表名', {COLUMNS => ['列族名1', '列族名2'], LIMIT => 10, STARTROW =>'起始的rowkey'}
scan查询添加过滤器
ROWPREFIXFILTER rowkey 前缀过滤器
scan 'user', {ROWPREFIXFILTER=>'rowkey_22'}
查询某个rowkey的数据
get 'user','rowkey_16'
删除表中的数据
delete 'user', 'rowkey_16', 'base_info:username'
清空数据
truncate 'user'
指定显示多个版本
get 'user','rowkey_10',{COLUMN=>'base_info:username',VERSIONS=>2}
修改可以显示的版本数量
alter 'user',NAME=>'base_info',VERSIONS=>10
通过TIMERANGE 指定时间范围
scan 'user',{COLUMNS => 'base_info', TIMERANGE => [1558323139732,1558323139866]}
get 'user','rowkey_10',{COLUMN=>'base_info:username',VERSIONS=>2,TIMERANGE=> [1558323904130, 1558323918954]}
通过时间戳过滤器 指定具体时间戳的值
scan 'user',{FILTER => 'TimestampsFilter (1558323139732, 1558323139866)'}
get 'user','rowkey_10',{COLUMN=>'base_info:username',VERSIONS=>2,FILTER =>'TimestampsFilter (1558323904130, 1558323918954)'}
获取最近多个版本的数据
get 'user','rowkey_10',{COLUMN=>'base_info:username',VERSIONS=>10}
通过指定时间戳获取不同版本的数据
get 'user','rowkey_10',
{COLUMN=>'base_info:username',TIMESTAMP=>1558323904133}
命令表