大家好,我是土哥。
2024 届校招已然落下帷幕,互联网大厂为将优秀人才招致麾下,纷纷使出浑身解数。在薪资待遇方面,更是各有千秋 。
这里给大家分享一位2024届求职的小伙伴,PDD 非技术岗拿到 50w 的 SSP offer~
我盆友圈的一个粉丝,之前和土哥交流,说她投递的PDD 上海岗位,从面试完到开奖,中间过了快2个月,本以为都挂了,结果开出了50w,真是高兴了很久。
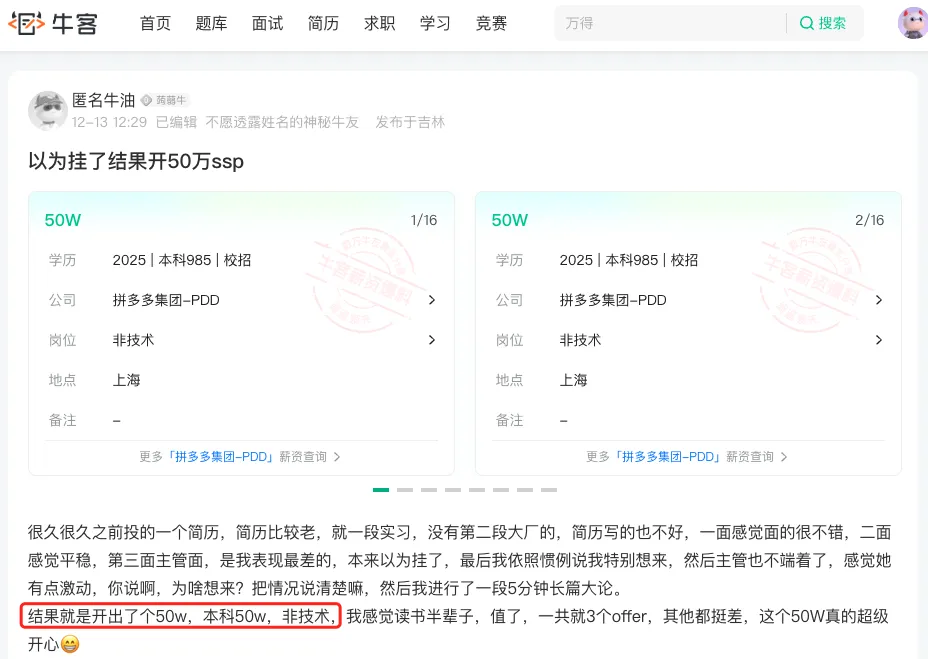

土哥听到这个消息,替她感到非常高兴,校招生,一入职就已经赢到了起跑线,又有多少同学能拿到这个水平呢?
想起当年土哥的校招薪资,那也比她低好多呀。说多了都是泪。
当然,羡慕别人的同时,我们还是要先学习起来,不管是实习、校招、还是社招,打铁还需自身硬,下面给大家分享一些大数据的面试题,更好的帮助大家,找到一份更好的工作。
Zookeeper 功能
1 你了解 zookeeper 的选举机制吗?
首先,ZooKeeper 是一个分布式协调服务,广泛应用于分布式系统中,用于维护配置信息、命名服务、提供分布式同步以及组服务等。为了保证高可用性,ZooKeeper 通常以集群模式部署。在 ZooKeeper 集群中,通常为 Leader 选举机制。
1 背景
-
Leader:负责处理所有写请求,并向 Followers 发送更新。
-
Follower:接收客户端的读请求;参与投票过程;从 Leader 接收更新。
-
Observer(可选):类似于 Follower,但不参与选举过程。主要用于增加系统的读取吞吐量而不影响写性能。
2 选举触发条件
-
初始启动时没有指定 Leader。
-
当前 Leader 失效或与大多数节点失去联系。
-
系统重启后需要重新选举新的 Leader。
3 选举算法
ZooKeeper 使用一种基于 Fast Leader Election (FLE) 的改进版本来选择其 Leader。这个过程可以分为几个阶段:
a. 投票初始化
每个服务器都开始一个新的选举周期,并给自己投票。每张选票包含三个关键信息:
1、myid:该服务器自己的标识符。
2、zxid:事务ID,反映了该服务器最后处理的一个事务编号。
3、epoch:逻辑时钟值,用来避免旧的信息干扰当前选举。
b. 交换选票
服务器之间通过心跳检测等方式互相发送选票信息。如果发现有比自己更合适的候选者(即具有更大的 zxid 或者相同 zxid 下更大的 myid),则会更改自己的投票给那个候选者,并继续广播这一决定。
c. 收集选票
当某个服务器获得了超过半数的支持票后,它就被认为是新任的 Leader。此时,它将转换状态并通知其他服务器结束选举过程。
d. 宣布结果
一旦确定了 Leader,所有其他服务器都将转变为 Follower 角色,并准备好接受来自新 Leader 的命令。
4 特殊情况处理
-
如果网络分区导致部分节点无法通信,则只有能够相互通讯的大部分节点才能成功完成选举过程。
-
在某些情况下,可能因为没有足够的有效投票而导致选举失败,这时整个集群可能会暂时不可用,直到恢复到足够数量的健康节点为止。
Spark lazy
2 spark 的 lazy 体现在哪里?
在 Apache Spark 中,操作分为两种类型:Transformations 和 Actions。
Transformations:这些操作是懒操作,不会立即执行。它们只是记录下要执行的操作,并返回一个新的 RDD(弹性分布式数据集)或 DataFrame/Dataset。常见的 Transformation 操作包括 map, flatMap, filter, reduceByKey 等。
Actions:这些操作会触发实际的计算。当一个 Action 操作被调用时,Spark 会根据之前记录的所有 Transformation 操作来构建一个执行计划,并执行该计划。常见的 Action 操作包括 collect, count, save, foreach 等。
懒加载的意义
1、避免无意义的计算:
-
减少中间结果:由于 Transformations 是懒操作,只有在需要的时候才会真正执行,因此可以避免生成大量的中间结果。这不仅节省了内存资源,还减少了磁盘 I/O 和网络传输。
-
优化执行计划:Spark 可以在执行前看到整个操作链,从而进行全局优化。例如,它可以合并多个 Map 操作,或者重新排列操作顺序以提高效率。
2、执行优化:
-
DAG 优化:Spark 使用有向无环图(DAG)来表示计算任务。通过懒加载,Spark 可以在执行前分析整个 DAG,并进行一系列优化,如合并操作、广播变量、分区优化等。
-
数据局部性:Spark 可以利用数据局部性原则,将计算任务调度到数据所在的节点上,从而减少数据传输开销。
3、容错和重试:
-
容错机制:懒加载使得 Spark 可以更好地处理故障。如果某个任务失败,Spark 只需要重新计算相关的部分,而不是整个作业。
-
细粒度重试:由于每个 Transformation 都是独立的,Spark 可以在细粒度级别上进行重试,从而提高系统的可靠性和稳定性。
4、资源管理:
-
资源利用率:懒加载使得 Spark 可以更灵活地管理资源。它可以根据当前集群的负载情况动态调整任务的执行,从而提高资源利用率。
-
延迟加载:对于大数据集,懒加载可以避免一次性加载所有数据,而是按需加载,从而减少内存压力。
给个实例:
val data = sc.textFile("input.txt")
val words = data.flatMap(line => line.split(" "))
val wordCounts = words.map(word => (word, 1)).reduceByKey(_ + _)
wordCounts.collect() // 这是一个 Action 操作,会触发前面所有的 Transformation 操作
在这个示例中,flatMap, map, 和 reduceByKey 都是 Transformation 操作,不会立即执行。只有当 collect 被调用时,才会触发实际的计算。
Paimon 功能
3、paimon 组件你了解吗?有什么功能,解决什么问题?
Paimon 是一个由阿里云开源的流式数据湖存储系统,它为流处理和批处理提供了一种高效的数据存储方案。Paimon 设计的主要目的是解决传统数据湖在实时性、性能以及易用性方面存在的问题。
1 paimon 支持实时更新
-
主键表支持大规模更新的写入,具有非常高的更新性能,通常通过Flink 流入实时导入
-
支持多种Merge Engine,可以根据需要更新记录
去重保留最后一行(deduplicate)、部分更新(partial-update)、聚合记录(aggregate)、去重保留第一行(first-row)
- 支持定义 changelog-producer,在 Merge engine 的更新中生成正确和完整的变更日志,用于支持下游进一步流式增量计算。
2 支持超大非主键表处理能力
-
支持非主键表的批处理和流式处理能力,自动小文件合并能力
-
支持使用order, z-order排序进行数据压缩以优化文件布局,基于minmax等索引提供快速查询和data skipping 的能力
3 支持湖格式能力
- 可扩展的元数据,支持存储PB级大规模数据集和大量分区的存储
- 支持ACID事务,Time travel 和 Schema evolution
以上就是本次分享的几道面试题~
增值服务
增值服务:简历修改|面试辅导|Flink资料|模拟面试
你好,我是土哥,计算机硕士毕业,现某大厂资深大数据开发工程师。出生在一个 18 线开外的小村庄,通过自己努力毕业一年在新一线城市买房,在社招、校招斩获 28 家中大厂 offer。
土哥社招参加 28 场面试,100% 通过率,拿到全部 offer!
土哥这半年的悲惨人生,经历过被鸽 offer,最终触底反弹~
25 年新的一年,很多公司已经开启了节前面试-年后入职的流程。如果你想跳槽,但苦于一个人孤军奋战、无人指导、复习无从下手,或者不擅长写简历,手上只有拿不出手的毫无难点亮点的项目经历...
那么我的建议是多和身边的大佬沟通,哪怕是付费咨询,只要你能从他身上学到经验,那就是值得的。如果身边没有这样的人,那么我就毛遂自荐一下吧,毕竟,茫茫网络你能看到这篇文章何尝不是一种命运安排。
如果这篇文章对您有所帮助,或者有所启发的话求一键三连:点赞、转发、在看。



![P3586 [POI2015] Logistyka](https://cdn.luogu.com.cn/upload/image_hosting/5o4u7lct.png)