在CES上,英伟达展示了一些有趣的新产品,其中最亮眼的是黄仁勋的新皮夹克。我的意思是,看看那件夹克:这是技术发布会还是时尚秀?
你不觉得惊艳吗?
说实话,我有点惊讶为什么更多人没有提到这个。这是黄仁勋迄今为止最棒的皮夹克。
当然,还有其他东西,比如全新的RTX 50系列。令人惊讶的是,大多数相关报道对它们的评价都很正面。我特别喜欢在Linus Tech Tips视频中的这条评论:
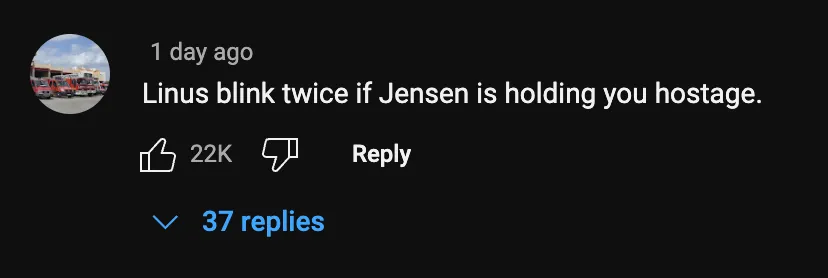
“因为就像有人指出的那样,50系列相较于40系列确实性价比更高,但如果跟30系列比就不行了。我觉得英伟达清楚新GPU的需求正在下降。”
在发布会上,他们展示了《赛博朋克》以240帧/秒的速度在8K分辨率下运行。说真的?8K?有人真的在8K分辨率下玩游戏吗?况且《赛博朋克》是2020年发布的,难道就没有更好的游戏来展示50系列的性能吗?
我不觉得会有很多人愿意购买这些新显卡,老款显卡已经足够用了,因此价格可能会下降。而且许多改进都体现在软件上,尤其是DLSS技术,而他们故意将其限制在新的50系列上。
但我看了评论,有一个值得注意的批评:显存最高仅16GB。哦,除了5090,如果你愿意花两千美元买一张显卡。但对于普通人来说,显存上限就是16GB。有人指出,这并不算多。
特别是在采用统一内存(GPU和CPU共享内存)的机器上,这种系统效率更高,因为内存浪费更少。在这样的系统中,我的M1 Air和Steam Deck都只有16GB统一内存。Steam Deck的内存规格和一张售价一千美元却没有电脑的GPU一样。这真是让人难过。
为什么在内存上这么小气?嗯,部分原因是英伟达的定价过高。AMD的显卡在相同价格下有24GB显存,我真不明白为什么大家这么喜欢英伟达。我一直避开它们,因为我总是遇到Nvidia驱动的问题。
但我觉得英伟达削弱显存还有另一个原因:不让你用它运行大型LLM(大语言模型)。大型语言模型是最新AI模型的基础,需要消耗大量显存。英伟达宁愿你买两个产品,也不愿让一张显卡搞定所有事情。虽然我通常会抱怨,但他们专用的LLM机器确实令人印象深刻。让我们来看看Project Digits。
Project Digits是一台紧凑的Linux机器,预装了所有炫酷的英伟达AI软件。可以把它想象成加强版的Mac mini。他们甚至展示了这台机器的图片。
有趣的是,如果你放大图片,可以发现这是AI生成的。全球最有价值的公司用AI取代了某人的工作。这种想法也只有黄仁勋能爱。要在某人桌上放一台机器并拍张照片有多难?前几天我看到有人谈论他们的桌面配置,却发了一张随机AI生成的图片。你在干什么?如果你谈桌面配置,我期望看到桌面的真实照片,而不是一些AI胡搞的东西。唯一可能的原因是,你对自己的桌面配置不自信。那么我为什么要看你的文章?
言归正传,Project Digits配备了4TB NVMe存储、128GB统一内存和最新的Blackwell架构,售价3000美元。比GTX 5090贵不了多少。这也让人更加意识到5090性价比有多差。
另外,随便说说,如果你配置一台Mac mini,选择M4 Pro芯片、64GB内存和4TB存储,价格甚至比Project Digits还贵。
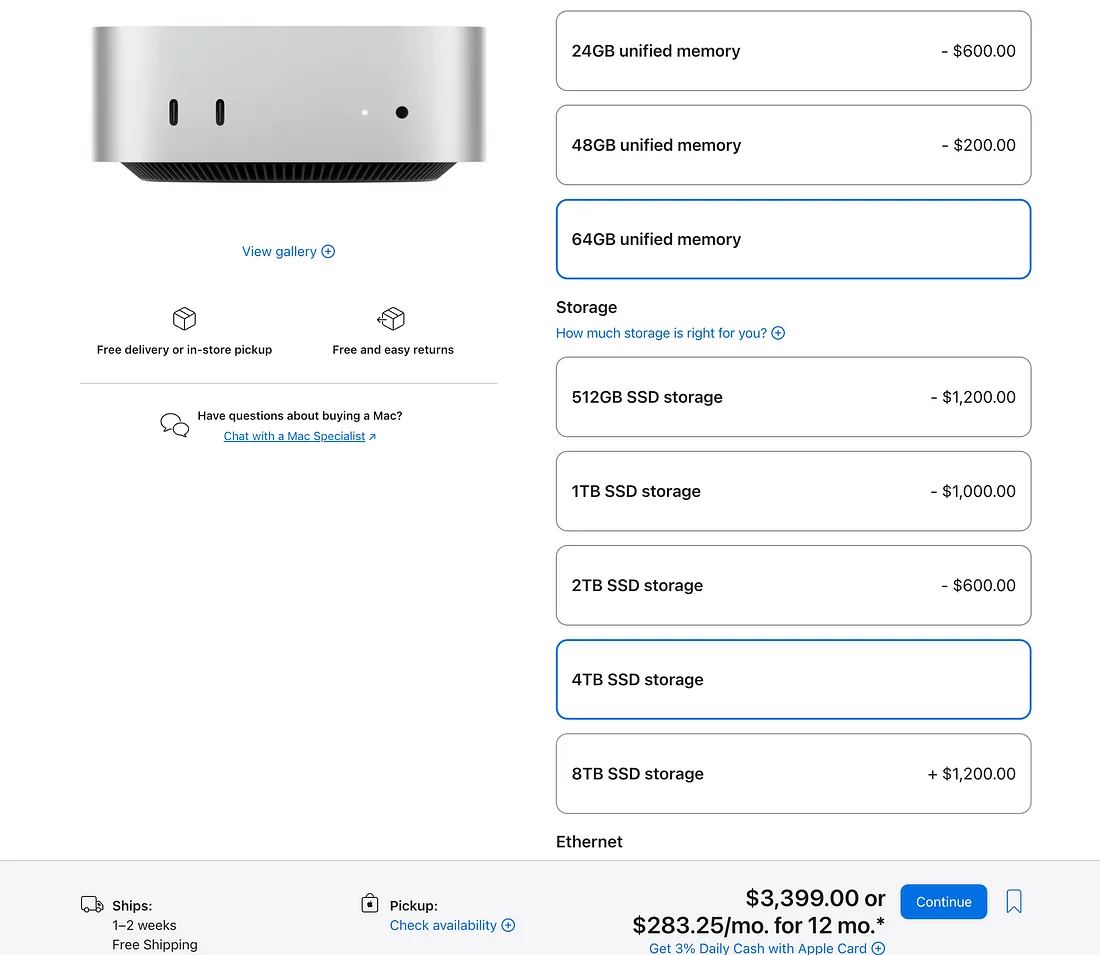
升级价格真是相当吓人,对吧?
英伟达声称Project Digits可以运行2000亿参数的模型,如果你连接两台设备,可以运行4050亿参数的模型。4050亿,这是个非常精确的数字。为什么用这个数字?因为这是最大Llama模型的参数规模。英伟达基本在说:“现在你可以在家里运行最新的Llama模型,而不需要为服务器支付高额费用。”
之前的成本是多少?这全是保密信息,但我们知道AWS的P5实例每小时收费98美元,相当于每天2354美元。而两台Project Digits的成本是6000美元。如果你买两台,3天就可以收回成本。
你可能认为P5是过度配置。不过我查了一些帖子:
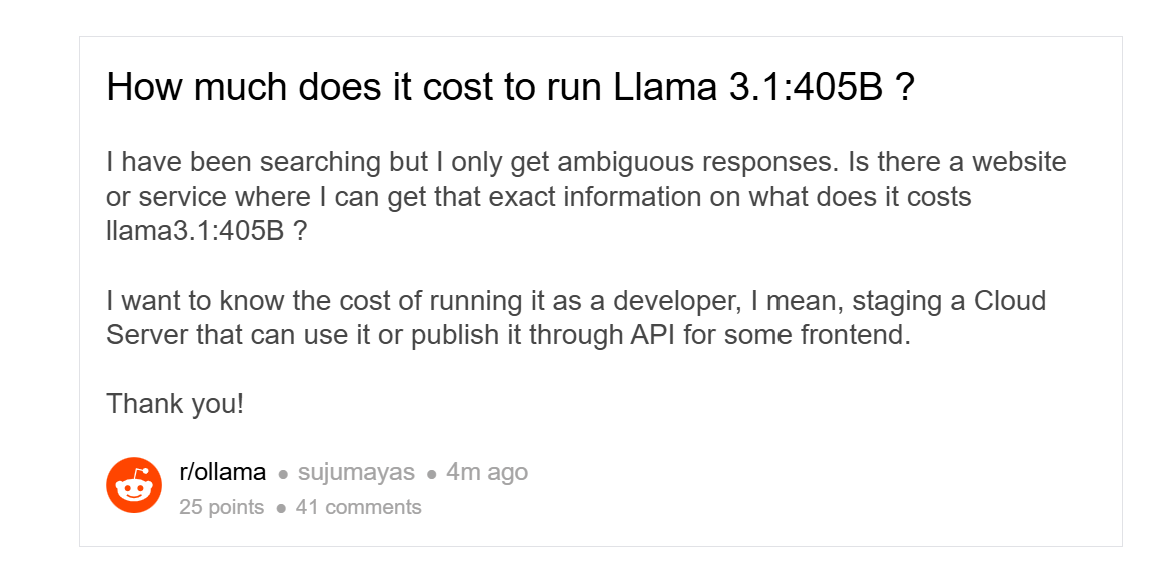
也许不是。人们经常引用的价格显然比两台Project Digits更高。
可以肯定地说,Project Digits将彻底改变AI定价游戏。我预计公司会开始成批购买这些设备,显著降低运行AI模型的成本,尤其是像Llama这样的开源模型,因为任何人都可以下载并运行它。目前很多公司已经在使用它。
最初我对Llama的定价相当失望,因为它的价格并不比Anthropic、OpenAI和Google的模型更具竞争力。但这一情况可能会改变。
当Llama的价格下降时,我能看到整个行业跟随降价的可能性。一些模型的规模尚不明确,除了Gemini Flash 8B。我几乎可以肯定它只有80亿参数,意味着它可以在消费级GPU上运行。老实说,我有点失望Flash 8B的价格只是完整版Gemini Flash的一半。如果他们愿意,我相信价格还可以更低。没必要,因为Gemini Flash已经是最便宜的了。当然,我觉得AWS可能有个模型技术上更便宜,但那是AWS,它烂得像其他AWS垃圾一样。
我正在开发一个电子邮件应用,叫Project Tejido,它会用LLM扫描每封电子邮件。我做了一些粗略计算,觉得这会是个非常好的主意,因为运行成本非常低。然而,现在实际开发过程中,我发现自己对每封邮件所需的tokens估计错了……错了两个数量级。所以成本比预期高了许多。虽然这个项目仍然可行,但远没有我最初估计的那么划算。我期待LLM的价格能再降一点,希望能降低两个数量级。
不过,我不确定LLM的成本是否会再降两个数量级,因为这已经接近电力成本了。但降一个数量级?有可能。要大幅降低LLM的成本需要什么?竞争。最近我们还没有看到太多竞争。当然,有GPT-4o Mini和Claude 3.5 Haiku,但GPT-4o Mini已经很老了,Claude 3.5 Haiku实际上比Claude 3.0 Haiku更贵。他们声称这是因为性能更好。
问题就在这:低端模型竞争激烈,但高端‘前沿’模型却没有。我们需要前沿模型降价。而唯一的办法就是让算力变得极其便宜。英伟达的Project Digits正是这样做的,所以它将大幅压缩AI模型的价格。
更新:许多人提到内存速度问题。英伟达没有公布设备的内存带宽,但估算值在273GB/s到1TB/s之间。我不认为它能超过那些价格是它5倍的显卡,但我猜测它仍然足够快,可以运行像Llama 405b这样的LLM,而这正是黄仁勋提到的。因此,与目前类似规格的硬件相比,它仍将显著更便宜。






![[2025.1.13 JavaSE学习]集合-7(Hashtable Properties)](https://img2024.cnblogs.com/blog/3574171/202501/3574171-20250114033027596-1768811498.png)