定义: 将人类语言与数字建立联系的强大方法
嵌入技术的演变:
Wod2Vec
- CBOW(Continuous Bag of Words):根据上下文词汇预测目标词汇(情感分析、文本分类、词相似性)
- Skip-Gram:根据目标单词预测周围单词
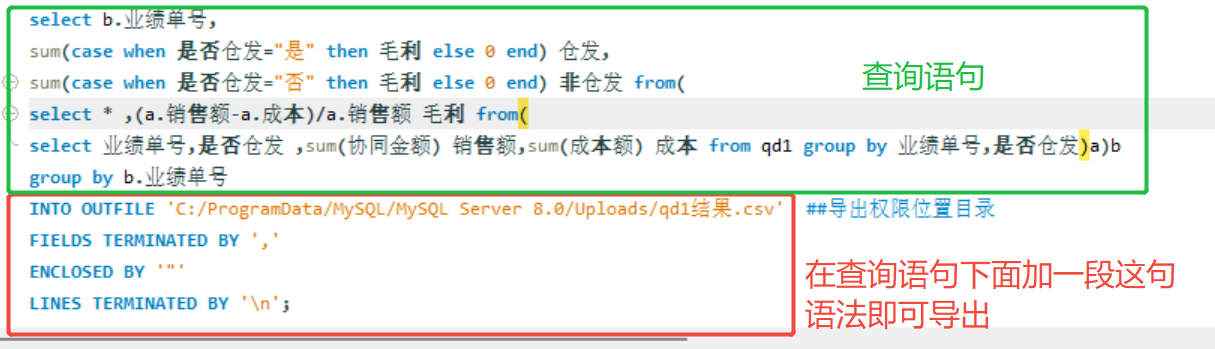
在训练Word2Vec模型时,包含词典和词向量模型的训练
词典的构建是训练过程的一部分。具体步骤如下:
- 分词:首先,输入的文本数据会被分词,每个句子被拆分成单词列表。
- 构建词汇表:在分词的基础上,模型会遍历所有句子,统计每个单词的出现频率,并构建一个词汇表。这个词汇表记录了所有唯一单词及其出现次数。
- 过滤低频词:根据 min_count 参数,模型会过滤掉出现次数少于 min_count 的单词。这些单词不会被包含在最终的词汇表中,也不会有对应的词向量。
- 索引映射:对于每个保留下来的单词,模型会分配一个唯一的索引。这个索引用于在词向量矩阵中快速查找对应的词向量。
- 词向量的训练
在词典构建完成后,模型会开始训练词向量。具体步骤如下: - 初始化词向量:模型会为词汇表中的每个单词初始化一个随机的词向量。这些词向量的维度由 vector_size 参数决定。
- 训练过程:模型通过遍历所有句子,使用上下文窗口(由 window 参数决定)来预测目标单词或使用目标单词来预测上下文单词(取决于使用的架构是CBOW还是Skip-Gram)。
- 反向传播:在每次预测过程中,模型会计算预测值和实际值之间的误差,并通过反向传播算法调整词向量,使得模型能够更好地预测上下文单词或目标单词。
- 优化:通过多次迭代,模型会逐渐优化词向量,使得词向量能够捕捉单词的语义和语法信息。

2、GloVe (2014):引入全局上下文
GloVe(Global Vectors for Word Representation)通过统计单词在数据集中同时出现的频率,进一步提升了嵌入技术的表达能力。例如,它能推导出“国王-男人+女人=女王”这样的关系。
3、Transformers (2018):上下文敏感的嵌入
BERT 和 GPT 等基于 Transformer 的模型,将嵌入提升到新的高度。与早期的静态嵌入不同,Transformer 能够根据句子中的具体语境动态调整单词的含义。例如,“Bank”在“河岸”和“金融机构”中的表示是不同的。
模型怎么学习,计算机会注意到以下模式:
• 相似上下文中的单词具有相似含义,如“猫”和“狗”都出现在“宠物”、“睡觉”等上下文中。
• 频繁一起出现的单词关系密切,如“西安”和“汉唐盛世”。
• 替换不会改变语义的词是同义词,如“美丽”和“华丽”。
嵌入的多层次应用(这里指的是在不同的应用场景,需要进行嵌入应用的最小粒度)
1、单词嵌入(Word Embeddings) 专注于捕捉单词的语义信息,广泛应用于同义词查找、词义消歧等任务。
2、句子嵌入(Sentence Embeddings) 用于提取句子的整体含义,适合构建问答系统、语义相似度计算等场景。
3、文档嵌入(Document Embeddings) 通过捕捉长文本的主题和结构信息,为文章分类、摘要生成等任务提供支持。
长文本如何嵌入?
处理长文本时,需要针对文本的长度和任务需求选择合适的嵌入方法:
1、平均词嵌入 (Averaging Word Embeddings) 将文本中所有词向量取平均以生成嵌入向量。这种方法简单且计算效率高,但无法捕捉词序和上下文的复杂关系。
2、循环神经网络 (Recurrent Neural Networks, RNNs) 按顺序处理文本,能够捕捉单词之间的时间依赖关系。适合中等长度文本,但对超长文本的表现受限。
3、Transformer 模型 Transformer 一次性分析整段文本,通过自注意力机制同时捕获局部和全局关系,是长文本嵌入的主流选择。
4、池化技术 (Pooling Techniques) 如最大池化或平均池化,用于提取文本中最具代表性的特征向量,常与 Transformer 模型结合使用,以提升长文本的处理效率。
实际应用场景,不同长度的文本嵌入方法各有其独特优势:
• 短查询或句子:使用单词或句子嵌入进行语义搜索,如关键词匹配或搜索引擎优化。
• 长文档:采用段落或文档嵌入进行主题分类、情感分析或摘要生成。
• RAG 系统(Retrieval-Augmented Generation):将文档分块(每块 100-300 个单词)进行嵌入,以实现高效的检索和生成,兼顾上下文细节和计算效率。
refer
https://mp.weixin.qq.com/s/ODJ-tIcxoKYABylUBnfNJg