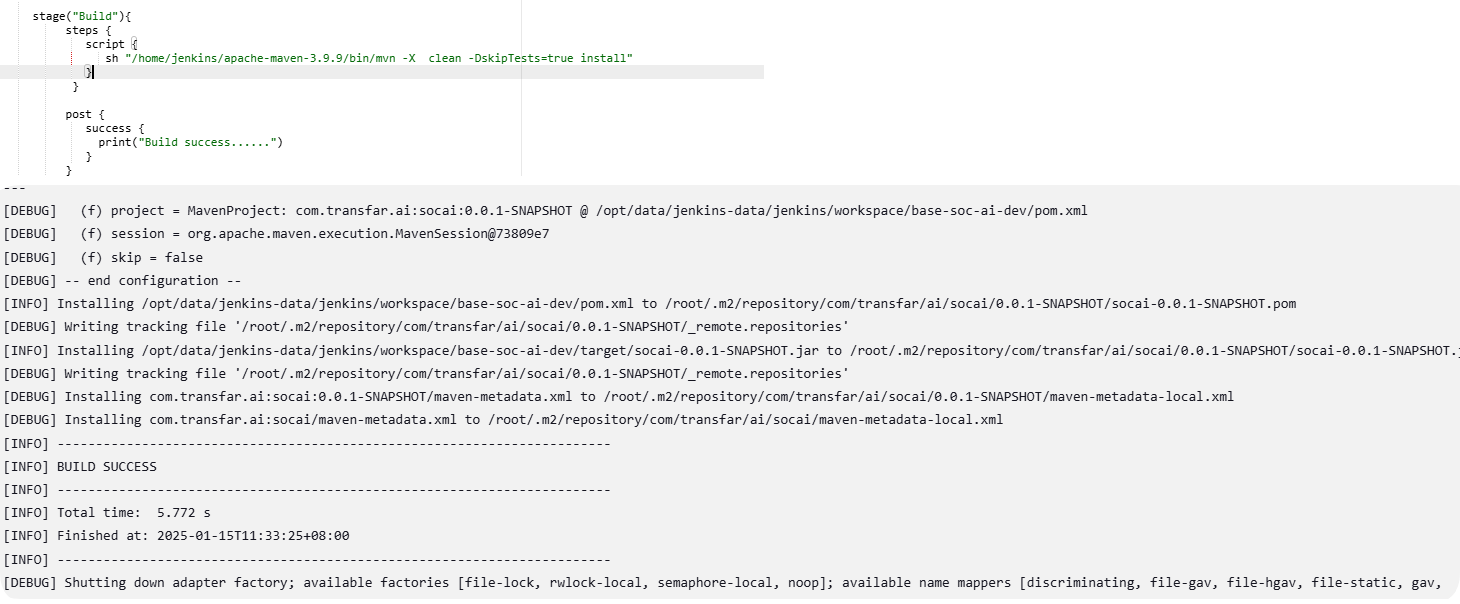
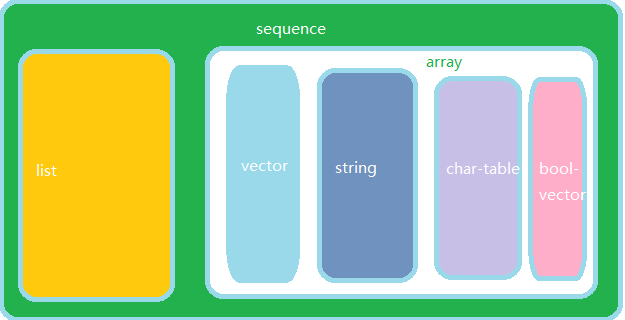
elisp 中序列是数组和列表的统称,序列的共性是内部数据有一个先后的顺序,它与C/C++ 中有序列表类似。
elisp 中的数组包括向量、字符串、char-table 和布尔向量,它们的关系如下:
在之前一章中已经介绍了序列中的一种类型——列表,本篇将介绍序列中的另外一种数据类型——数组
数组简介
与C/C++ 中的数组类似,elisp中的数组有如下特征
- 在创建之初给定长度之后不允许后期修改长度
- 数组中的每个元素都可以通过索引来获取,并且获取的算法时间复杂度为O(1)
- 数组是自求值的
- 数组中的的元素可以通过 aref 来获得,并且通过aset 来设置值
根据上图,向量是数组中的一种。字符串也是特殊的数组,它是内部全部都是字符的数组(虽然elisp中没有字符这种数据类型)。教程中没有介绍 char-table 和 bool-vector,所以这里我也不打算介绍,后面要是真遇到了再看。
测试函数
测试函数是用同名带p的函数来进行测试,例如 sequencep 来测试是否是一个序列,stringp 测试是否是一个字符串, vectorp 测试是否是一个向量,arrayp 测试是否是一个数组。char-table-p 和 bool-vector-p 分别测试对象是否是 char-table、bool-vector
(arrayp [1 2 3]) ;; ==> t
(vectorp [1 2 3]) ;; ==> t
(stringp [?A ?B ?C]) ;; ==> nil
(stringp "ABC") ;; ==>t
(vectorp "ABC") ;; ==> nil
(arrayp "ABC") ;; ==> t
通过上面的测试发现字符串和向量是不同的类型,但是字符串也是一种数组
上述代码创建了一个向量,然后判断向量是否是一个数组。在elisp中向量也是数组的一种,所以这里返回t
序列的通用函数
在字符串中提到过,可以使用 length 来获取字符串的长度。其实它是一个序列的函数,它可以获取序列的长度。
对于列表来说,它只能获取真列表的长度,对于点列表它会报错,而对于循环列表则会陷入死循环。它的算法应该是跟C/C++ 中获取链表的长度的算法一样,根据最后一个节点的next指针域是否为空来进行判断。
对于点列表和循环列表,可以使用 safe-length 来获取,从名称上看,它是一个安全的获取长度的函数。
(length [1 2 3 4]) ;; ==> 4
(safe-length '(1 2 3 4)) ;; ==> 4
(safe-length '(1 2 3 . 4)) ;; ==>3
这里不要疑惑为什么第二个参数表达式返回的结果会是3,表达式中列表真正的表达形式应该是
'(1 (2 (3 . 4)))
虽然写法上使用 (1 2 3 . 4) 比较清爽干净也容易理解,但是要时刻记住它真正的形式应该是多个cons cell组成。
插一个题外话,不知道各位读者还记不记得当初在学数据结构时,学到的如何判断环形链表的算法。那个算法被叫做两个指针跑步法,脱胎于小学时学的一道数学题;“在一个环形跑道,小明以每秒1米的速度匀速跑,小华以每秒2米的速度匀速跑,多久之后小明落后小华一圈”。这个算法也是这样的,一个慢指针每次往后移动一个节点,一个快指针一次移动两个节点,下一次两个指针能相遇,那么它就是一个环形列表。根据这个算法我们也可以提供一个lisp版本的判断环形列表的代码
(defun circle-list-p (list)(and (consp list)(circle-list-p-1 (cdr list) (cdr (cdr list)))))(defun circle-list-p-1 (slow fast)(if (or (null slow) (null fast))nil(if (not (consp slow))nil(if (eq (car fast) (car slow))t(circle-list-p-1 (cdr slow) (cdr (cdr fast)))))))(circle-list-p '(1 2 3 4)) ;; ==> nil
(circle-list-p '#1=(1 2 . #1#)) ;; ==> t
获取序列的第n个元素可以使用 elt,但是对于已知数据类型最好使用对应的函数,例如针对列表应该使用 nth,数组使用 aref。一来该对象是何种数据类型更加直观,二来省去了 elt 内部类型判断的操作。copy-sequence 在前面已经提到了。不过同样 copy-sequence 不能用于点列表和环形列表。对于点列表可以用 copy-tree 函数。环形列表就没有办法复制了。 好在这样的数据结构很少用到。
数组操作
创建向量可以使用 vector 函数,或者使用[], 来包裹一组数据,后者是向量的读入语法
(vector 1 2 3) ;; ==> [1 2 3]
(setq foo '(a b))
[foo] ;; ==> [foo]
(vector 'foo) ;; ==> [foo]
(vector foo 1 2 3) ;; ==> [(a b) 1 2 3]
上述代码中我们使用两个方式分别构造一个向量。采用vector的时候会对其中的每个符号进行求值。而使用[]来构造时则没有进行求值,等效于使用 quote
使用 make-vector 可以生成元素相同的向量
(make-vector 9 "foo") ;; ==> ["foo" "foo" "foo" "foo" "foo" "foo" "foo" "foo" "foo"]
fillarray 可以将数组的每个元素使用对应值进行填充
(fillarray [1 2 3 4] 'foo) ;; ==> [foo foo foo foo]
aref 和 aset 可以访问和设置数组中对应索引的元素。但是需要注意数组的长度,如果传入索引超过数组长度则会报错。
可以使用 vconcat 可以将多个序列合并成一个向量,这里可以传入非向量,例如传入列表。针对列表仅限真列表。
(vconcat [1 2 3] [3 4 5]) ;; ==> [1 2 3 3 4 5]
(vconcat [1 2 3] '(3 4 5)) ;; ==> [1 2 3 3 4 5]
(vconcat [1 2 3] '(4 . 5)) ;; ==> error
将向量转化成列表可以使用 append函数
(append [a b]) ;; ==> [a b]
(append [a b] nil) ;; ==> (a b)
(append [a b] '(c)) ;; ==> (a b c)
(append [a b] "cd") ;; ==> (a b . "cd")
(append [a b] "cd" nil) ;; ==> (a b "cd")
在列表那一章中,append是将列表的最后一个节点的cdr替换为对应参数。在这里它可以将序列的元素转化为列表,但是需要注意,转换时同样需要两个参数。它会将第一个参数转化为列表,然后执行列表中添加元素的操作