 本文通过一个爬取二手房的案例,来分享另外一种解析数据的方式:解析神器python第三方库parsel库。之所以叫他解析神奇,是因为它支持三种解析方式。
可以通过Xpath,CSS选择器和正则表达式来提取HTML或XML文档中的数据。
本文通过一个爬取二手房的案例,来分享另外一种解析数据的方式:解析神器python第三方库parsel库。之所以叫他解析神奇,是因为它支持三种解析方式。
可以通过Xpath,CSS选择器和正则表达式来提取HTML或XML文档中的数据。@
目录
- 前言
- 导航
- parsel的使用
- 安装parsel
- 创建Selector对象
- 解析数据
- CSS选择器
- Xpath
- 正则表达式
- parsel的使用
- 爬取安居客二手房实例
- 运行截图
- 共勉
- 博客
前言
本文通过一个爬取二手房的案例,来分享另外一种解析数据的方式:解析神器python第三方库parsel库。之所以叫他解析神奇,是因为它支持三种解析方式。
可以通过Xpath,CSS选择器和正则表达式来提取HTML或XML文档中的数据。
导航
- 爬取小说案例-BeautifulSoup教学篇
- 爬取二手房案例--parsel教学篇(CSS选择器)
- 爬取美国公司案例-parsel库教学篇(Xpath的详细使用)
- 爬取东方财富网-parsel教学篇(正则表达式的详细使用+实例)
- 爬取QQ音乐的评论-JSON库的详细使用
parsel的使用
安装parsel
因为它是第三方库,所以需要在终端使用pip install parsel 来安装
pip install parsel
创建Selector对象
url="xxx.com"
resp=requests.get(url)
selector=parsel.Selector(resp.text)解析数据
解析数据有CSS选择器,Xpath和正则表达式,下面通过一个例子来分别介绍这三种解析方式
<html>
<head><title>Example</title>
</head>
<body><div class="wrap"><div id="container"><ul class="list"><li class="item-0">first item</li><li class="item-1"><a href="link2.html">second item</a></li><li class="item-0 active"><a href="link3.html"><span id="bold">third item</span><span id="test">test</span></a></li><li class="item-1 active"><a href="link4.html">fourth item</a></li><li class="item-0"><a href="link5.html">fifth item</a></li></ul></div></div>
</html>
CSS选择器
# get()和get_all()区别
## get():用于从通过选择器定位到的元素中提取第一个匹配项的文本内容或属性值,返回的是字符串。
## get_all():用于通过选择器定位到的元素中提取所有匹配项的文本内容或属性值,返回的是列表# 标签选择器
res = selector.css(tagName)
# 例如:提取所有li标签中的文字
li_data = selector.css("li::text").getall()# class选择器
res = selector.css(tagName.className)
# 例如 提取class为item-1的li标签的内容
li_data = selector.css("li.item-1::text").get()# id选择器
res = selector.css(tagName#idName)
# 例如:提取id为container的div标签的内容
li_data = selector.css("div#container::text").get()# 属性提取器
res = selector.css(tagName::attr(attrName))
# 例如:提取class为item-1的li标签中的href属性
res = selector.css("li.item-1::attr(href)").get()# 后代选择器(如div p)
# 例如:选择id为container的div标签下的所有span标签的内容
res = selector.css("div#container span::text").get()# 子选择器(如div > p)
# 例如:选择id为container的div标签下的所有span标签的内容(和上面不同的是这个标签必须在div的直接子代)
res = selector.css("div#container>span::text").get()# 嵌套选择器
# 例如:提取 class为item-0 li标签内的id为bold的span标签的内容
res = selector.css("li.item-0 span#bold::text").get()# 伪类选择器
# 例如:选择父级元素ul下的第二个li标签直接子代的内容
res = selector.css('ul>li:nth-child(2)::text').get()Xpath
敬请下篇
正则表达式
敬请下篇
下面通过一个爬取二手房安居客的实例来更深入的了解css选择器的用法吧
爬取安居客二手房实例
import requests # 数据请求模块
import parsel # 数据解析库
import csv # 存储到表格中
import os # 文件管理模块with open("house.csv", 'wb') as f:f = open('house.csv', mode='a', encoding='utf-8', newline='')csv_writer = csv.DictWriter(f, fieldnames=["小区名", "小区区域", "小区户型", "小区面积", "均价"])
csv_writer.writeheader()# 目标网站:安居客二手房网站
url="https://wuhan.anjuke.com/sale/hongshana/"
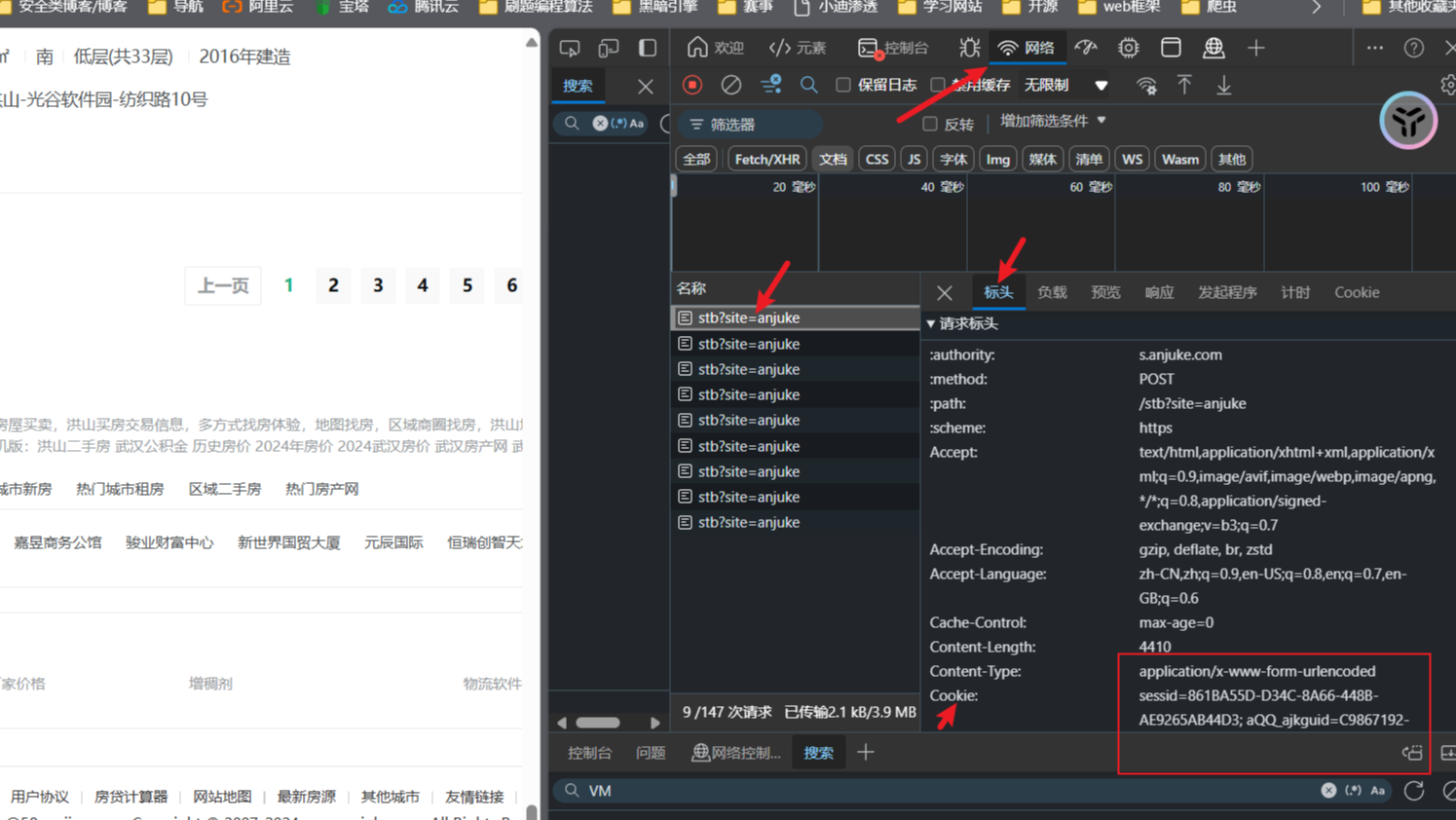
headers={"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.0.0 Safari/537.36 Edg/126.0.0.0","Cookie":"xxx"
}
# Cookie可以通过F12键 查看网络数据包,请求标头中。 如下面
response = requests.get(url=url, headers=headers)
# 实例化对象
selector = parsel.Selector(response.text)
# 爬取十页
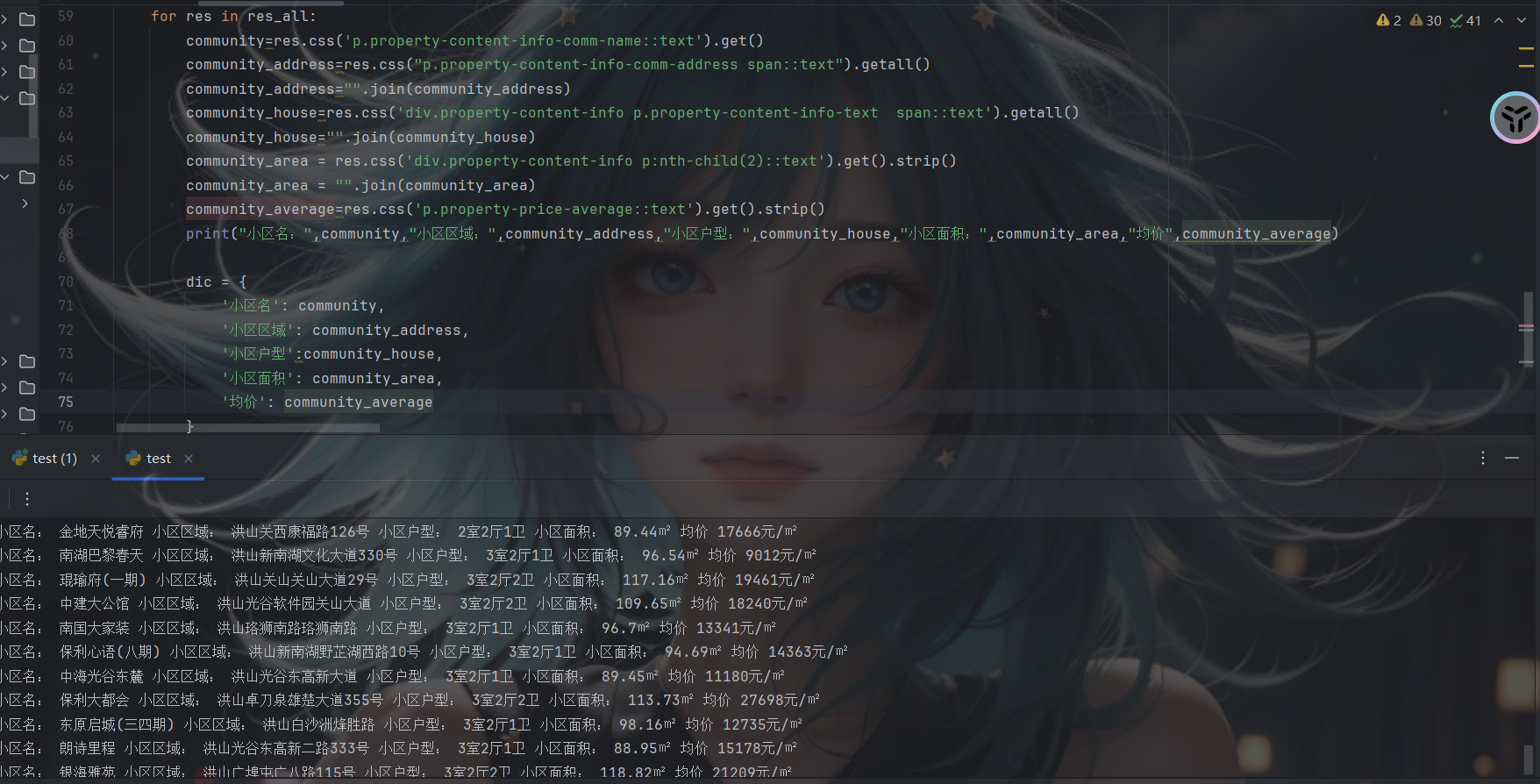
for num in range(1,11):url=f'https://wuhan.anjuke.com/sale/hongshana/p2/https://wuhan.anjuke.com/sale/hongshana/p{num}/'print(f"正在抓取:第{num}页")# class选择器res_all=selector.css('div .property')for res in res_all:community=res.css('p.property-content-info-comm-name::text').get()community_address=res.css("p.property-content-info-comm-address span::text").getall()community_address="".join(community_address)community_house=res.css('div.property-content-info p.property-content-info-text span::text').getall()community_house="".join(community_house)community_area = res.css('div.property-content-info p:nth-child(2)::text').get().strip()community_area = "".join(community_area)community_average=res.css('p.property-price-average::text').get().strip()print("小区名:",community,"小区区域:",community_address,"小区户型:",community_house,"小区面积:",community_area,"均价",community_average)dic = {'小区名': community,'小区区域': community_address,'小区户型':community_house,'小区面积': community_area,'均价': community_average}# 写入表格csv_writer.writerow(dic)这里找Cookie

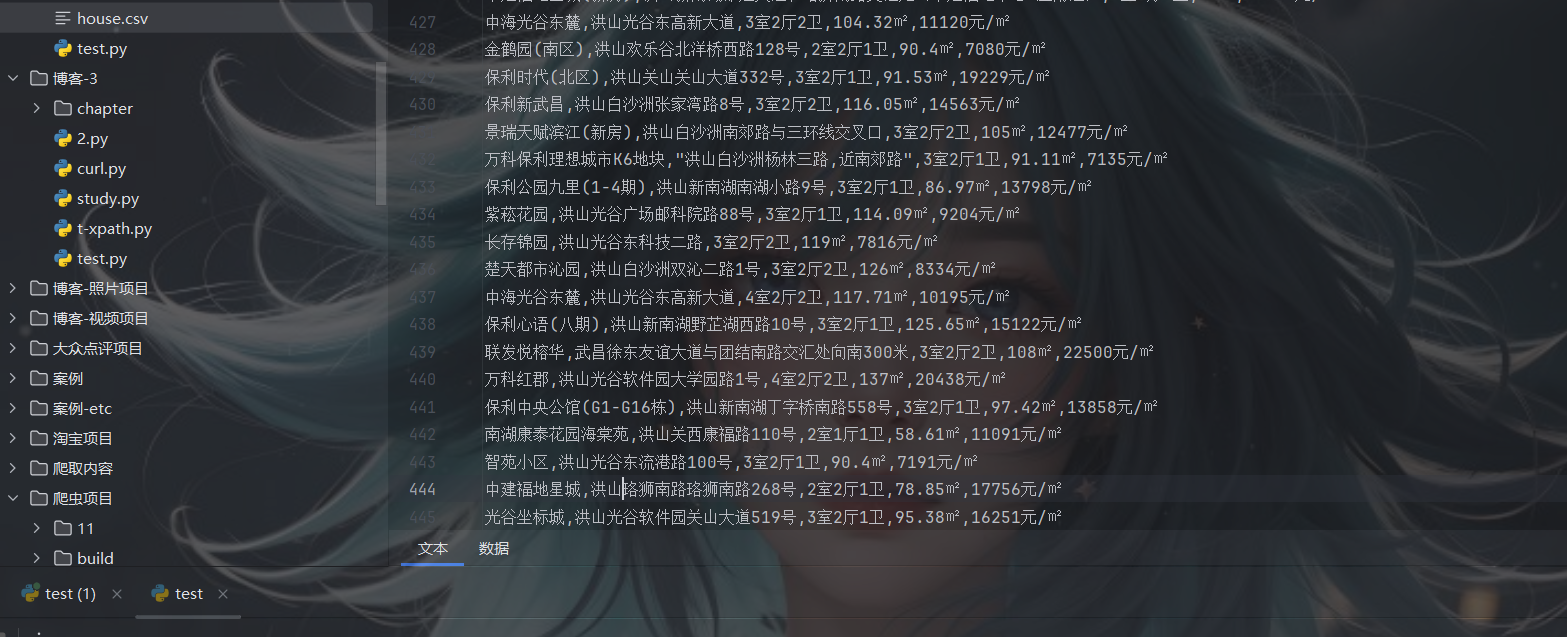
运行截图
共勉
财富是对认知的补偿,不是对勤奋的奖赏。
博客
- 本人是一个渗透爱好者,不时会在微信公众号(laity的渗透测试之路)更新一些实战渗透的实战案例,感兴趣的同学可以关注一下,大家一起进步。
- 之前在公众号发布了一个kali破解WiFi的文章,感兴趣的同学可以去看一下,在b站(up主:laity1717)也发布了相应的教学视频。