0. 前言
目前legged robot包括locomotion(怎么走)、navigation(往哪走)、人形机器人的whole body control以及基于机械臂的manipulation的任务。
本文章特此记录
一方面便于日后自己的温故学习,另一方面也便于大家的学习和交流。
如有不对之处,欢迎评论区指出错误,你我共同进步学习!
警告⚠:这篇文章没有一句水话
1. 先验
1.1 四足机器人的机械结构:
- 液压驱动(液压系统的基本原理是利用密封管道内的液体,在不同压力的作用下产生力和运动)
- 电机驱动 (电机驱动的运动是通过调节电机的速度和扭矩来操纵关节的运动,操作时通常需要电池或其他形式的电源)
- 气体驱动 (气动驱动的四足机器人利用压缩空气或气体来驱动执行器,如气缸或气动肌肉,通过调节气体的压力实现运动)
1.2 步态设计
这里写下四足机器人的运动控制步态:
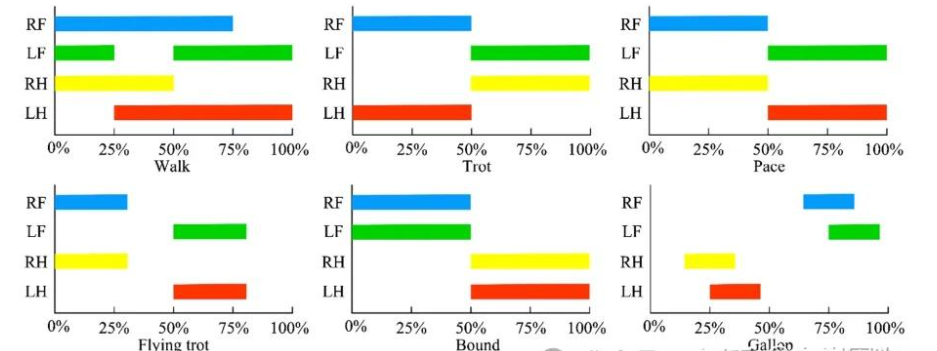
1.3 传统运动控制方法
这些都是不基于深度学习等方法的,都是基于传统运动控制的方法。
这里MPC是最耳熟能详的方法了,其他的就是了解。
下图包括基于模型和不基于模型的:
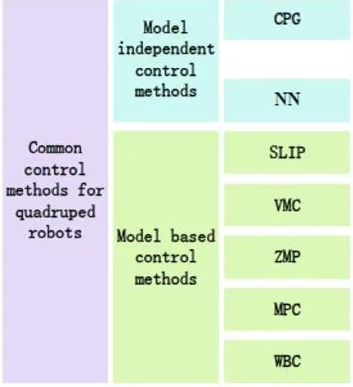
2. 正文
笔者记录一些论文的核心关键点,也就是主要框架,其他讲故事和实验的方面我就不再提及,因为这个地方主要看你的文笔好不好了,和技术没啥关系。
笔者这里就不贴出每个论文的跳转链接了,大家可以根据标题的名字自行搜索!
笔者速刷ArXiv,凝练一些关键词,细节部分可以自行品尝原文!!!
顺序不分先后。
2.1 Learning Quadrupedal Locomotion over Challenging Terrain
Science Robotics 2020
2020.Oct
Robotic Systems Lab, ETH Zurich, Zurich, Switzerland
这篇工作的主要特点是仅利用了四足机器人的本体信息(proprioceptive feedback),使用强化学习进行仿真环境训练和 zero-shot 的 sim-to-real 真实环境迁移,得到了能够在许多 challenging terrain 上成功的行走策略。
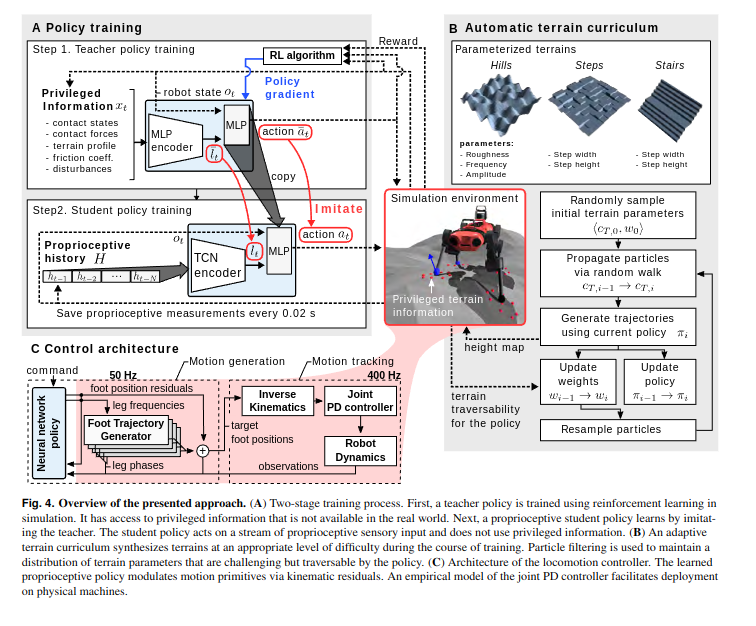
这篇工作提出privileged观测,也就是特权观测,这个观测值比如:接触力度、地形轮廓、摩擦系数等,这些参数不是很好能在现实中获得,因为如果要获得就得加上很多的传感器,很冗余。这些观测输入给教师网络进行第一次训练。随后学生进行第二次训练。两阶段的学习任务。
还有环境自适应的课程算法。能够逐渐调整地形难度
这基本就是之后locomotion任务的基础框架了
2.2 Learning Robust Perceptive Locomotion for Quadrupedal Robots in the Wild
Science Robotics, 19 Jan 2022, Vol 7, Issue 62
https://arxiv.org/abs/2201.08117
2022.1.20
这篇工作和上一篇工作的主要区别在于使用了感知信息(视觉、雷达)使四足能够获得更加完备的信息。
2.3 Extreme Parkour with Legged Robots 【】
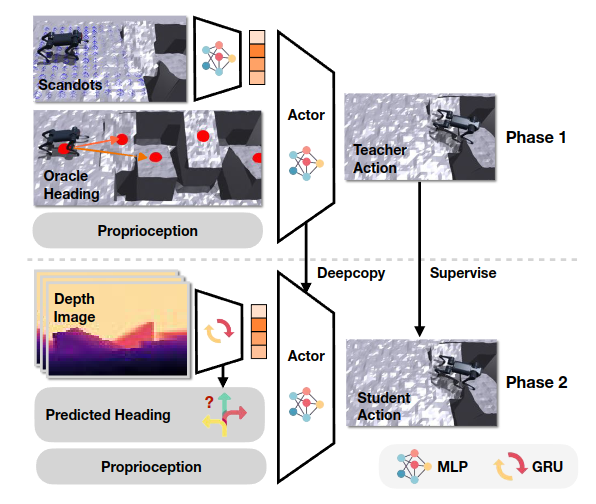

特权观测:scandots、环境参数、通过waypoints引导的waypoints
2.4 Legged Locomotion in Challenging Terrains using Egocentric Vision
Egocentric:自我的、以自己为中心的
Conference on Robot Learning (CoRL), 2023.
scandots的首先提出

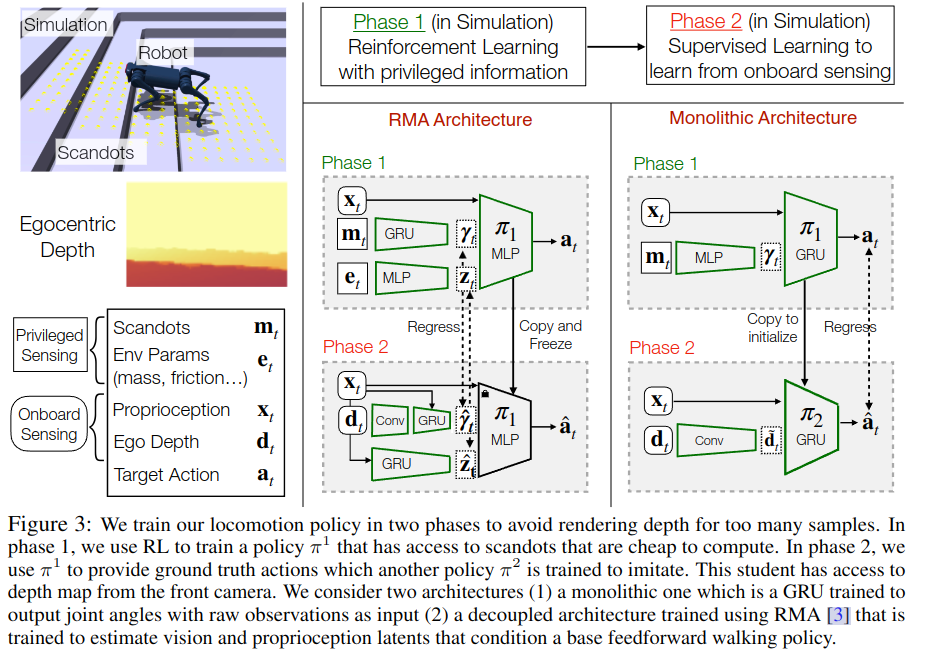
分两个阶段训练我们的运动策略,以避免太多样本的渲染深度。在第 1 阶段,我们使用 RL 训练策略 π1,该策略可以访问计算成本低的扫描点。在第 2 阶段,我们使用 π1 来提供另一个策略 π2 被训练来模仿的基本事实动作。这个学生可以访问来自前置摄像头的深度图。我们考虑两种架构 (1) 一个整体架构,它是一个 GRU,经过训练,可以输出与原始观察关节角度作为输入 (2) 使用 RMA [3] 训练的解耦架构,该架构经过训练以估计以基本前馈步行策略为条件的视觉和本体感觉潜伏期。
monolithic整体的
Mono结构
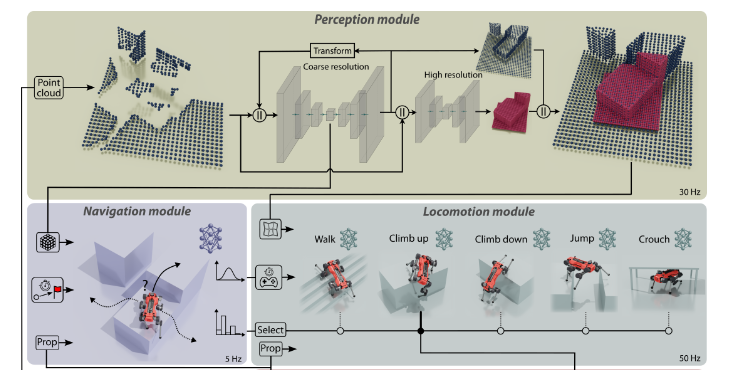
2.5 ANYmal Parkour: Learning Agile Navigation for Quadrupedal Robots【】
2023.6.26

2.6 RMA: Rapid Motor Adaptation for Legged Robots 【】
2021.1.8
RMA: Rapid Motor Adaptation for Legged Robots
提出了RMA模型,可以根据以往的历史信息来学习
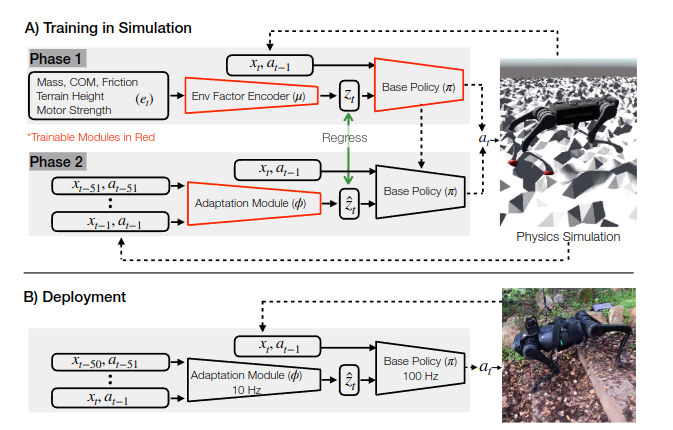
两阶段训练,base policy:100HZ和adaptive policy:10HZ
2.7 Learning to walk in minutes using massively parallel deep reinforcement learning【】
CoRL 2022
机器人并行训练,github的legged-gym被世人传唱。
train框架
sim2sim
sim2real
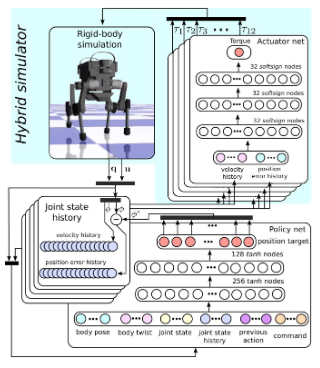
*2.8 Learning Agile and Dynamic Motor Skills for Legged Robots 【】
2019年的,太早了
2.9 Robot Parkour Learning
庄子文大佬的文章,之前有幸线上听过他的讲座。
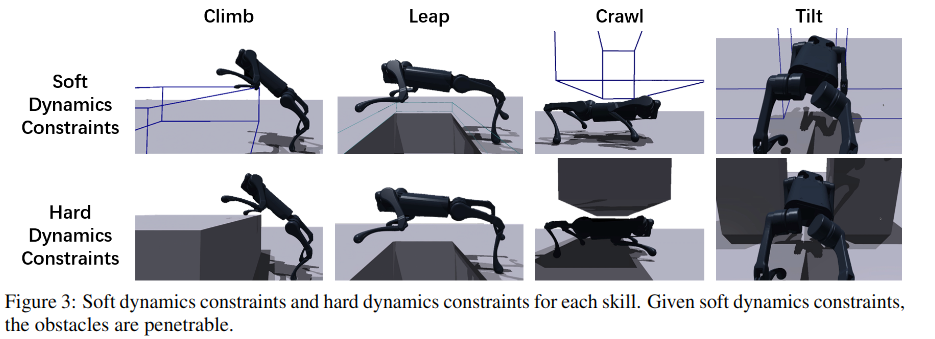
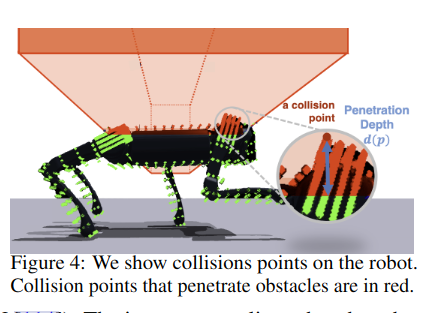
2.10 DreamWaQ: Learning Robust Quadrupedal Locomotion With Implicit Terrain Imagination via Deep Reinforcement Learning
2023.3.3

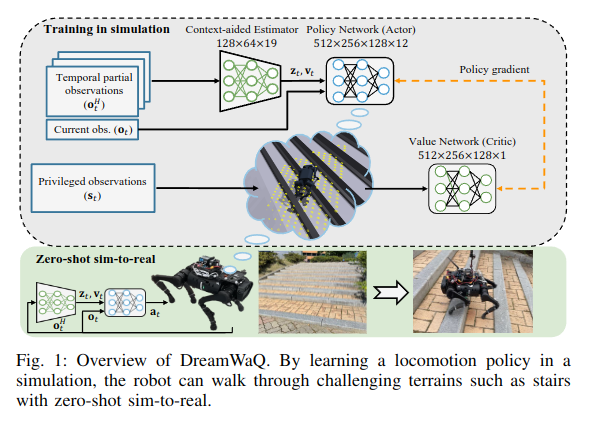
DreamWaQ训练运动策略隐式地推断地形属性,如高度图、摩擦、恢复和障碍物。
1、非对称的AC
2、latent(上下文辅助器)
我才看懂论文里这个w/o是啥意思,是without的意思。。。。w/是with的意思。。。。。
2.11 Concurrent Training of a Control Policy and a State Estimator for Dynamic and Robust Legged Locomotion
2022.3
IEEE Robotics And Automation Letters
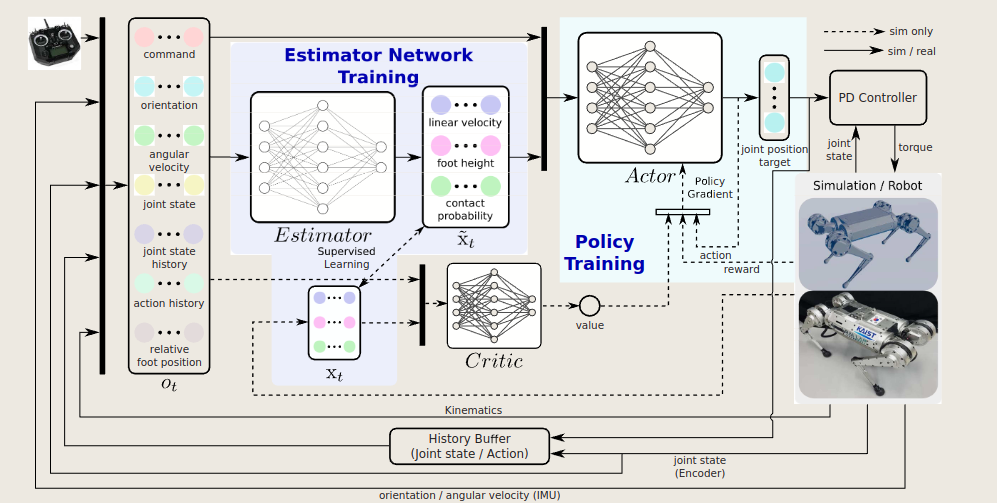
2.11 CTS: Concurrent Teacher-Student Reinforcement Learning for Legged Locomotion
2024.9.1
IEEE ROBOTICS AND AUTOMATION LETTERS
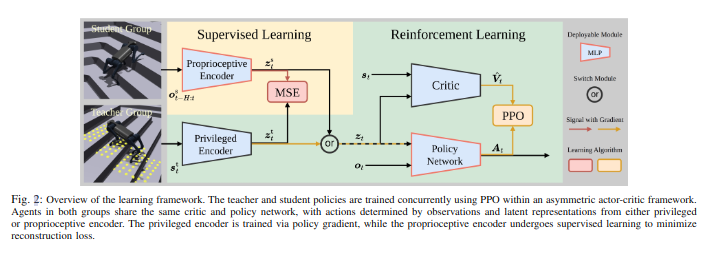
教师和学生并行训练,将两阶段合并为一个阶段。我们直接来看结构:
为了学习最优策略,机器人需要从可用的观测ot中推断出其当前状态st。由于环境的部分可观察性,通常不可能从单个观察中推断出实际状态。因此,推理问题 p(st|ot, ot−1, · · · , ot−n) 需要观察的历史序列。
文章通过将并行代理分为两组,称为教师组和学生组,同时训练教师和学生策略,然后使用上图所示的非对称演员-评论家框架,其中教师策略包括特权编码器和Policy Network,学生策略包括本体感知编码器和Policy Network。
两组中的代理都使用近端策略优化 (PPO) 进行训练,而它们共享相同的策略网络 πθ 和评论家网络 Vφ。
最近的工作利用变分自动编码器 (VAE) 或师生学习来隐式推断状态或与任务相关的信息。文章整合了这两种方法的优点,并采用近端策略优化 (PPO) 进行训练。
然后再来关注一下二者的损失函数:
PPO损失函数:(这些就是PPO算法里面的公式,不属于本片作者的工作范畴,他就是引用了下,略过)
1、actor的
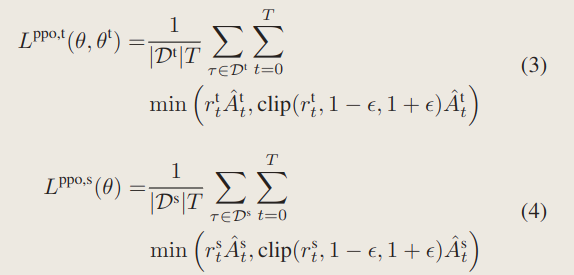
2、critic的
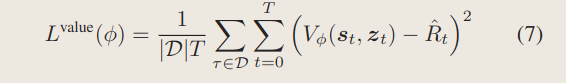
3、PPO算法

关于PPO算法还不懂得可以看我之前写的博客
4、TS网络的损失函数:
直接把隐变量作MSE:
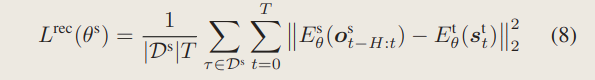
他这个网络结构也比较清晰哈哈:

*2.13 A Walk in the Park: Learning to Walk in 20 Minutes With Model-Free Reinforcement Learning
由于样本效率低下,深度强化学习应用主要集中在模拟环境上

不建议newer看原文,找不到要点,这篇不建议看,扫一下目录就行
2.14 Learning Robust and Agile Legged Locomotion Using Adversarial Motion Priors
2023.8
看了b站视频,效果很惊艳!跑的很快
这些工作只显示了在具有挑战性的地形上低速或中等速度的运动,而没有测试自然地形上的高速运动,所以文章提点来进行实操。
legged movements in the experiments of the papers employing RL methods are unnatural and jerky:现有文章的效果腿部不自然
AMP是动画领域,使用GAN来模仿生成逼真动作的一个方法。
2.15 A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning
这个不属于策略,这是一种方法,我看前面的论文总是提到这种方法,因此我就记录在这里了
DAgger (Dataset Aggregation)
这是一个基于在线学习 (Online Learning)的算法,其把行为克隆得到的策略与环境不断的交互,来产生新的数据。在 这些新产生的数据上,DAgger 会向专家策略申请示例;然后在增广后的数据集上,DAgger 会重新使用行为克隆 进行训练,然后再与环境交互;这个过程会不断重复进行。由于数据增广和环境交互,DAgger 算法会大大减 小未访问的状态的个数,从而减小误差。

2.16 Walk These Ways: Tuning Robot Control for Generalization with Multiplicity of Behavior
2022.12.6
https://github.com/Improbable-AI/walk-these-ways
2022.dec.6
Conference on Robot Learning (CoRL)
多步态
Abstract
学习一个单一的策略,该策略编码一个结构化的运动策略家族,以不同的方式解决训练任务,从而产生行为多样性(MoB)
不同的策略有不同的概括方式,可以在新的任务或环境中实时选择,而无需耗时的再培训
发布了一个快速,强大的开源MoB运动控制器----Walk These Ways,可以执行不同的步态与可变的脚摆,姿势和速度,解锁不同的下游任务:蹲伏、跳跃、高速跑步、楼梯穿越、支撑对推搡、有节奏的舞蹈等
2.12 Hybrid Internal Model: Learning Agile Legged Locomotion with Simulated Robot Response
这篇工作故事讲的比较好,对前人的工作总结的比较到位。
2024.1.2
HIM模型
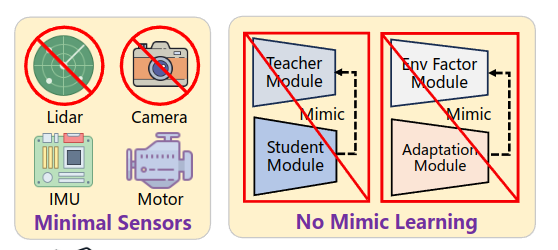
two-phase training paradigm 两阶段的学习范式
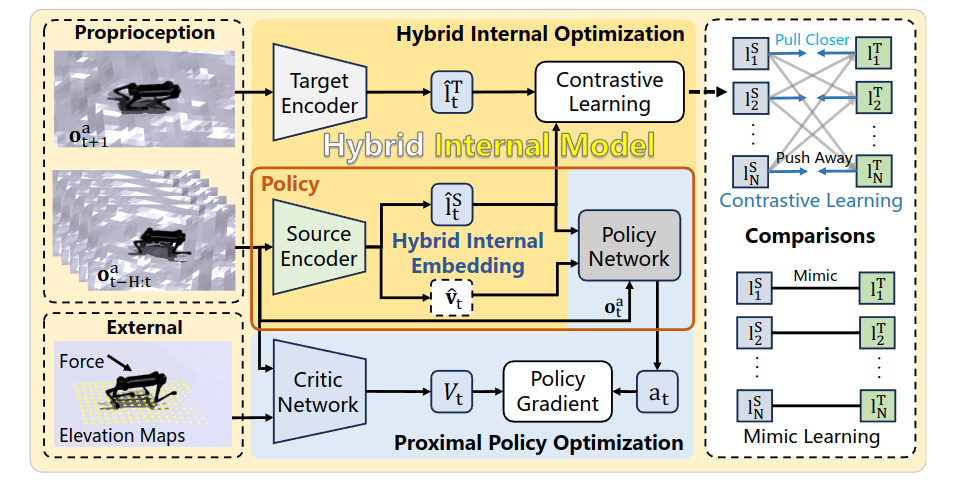
故事讲的不错,将高程图和地面摩擦等作为系统扰动,受到经典IMC的启发,Internal Model Control (PID)的启发。
论文里小小的总结了一下前人的这些方法,同时基于模仿学习的训练方法可以被分为两个类别The mimic learning methods can be categorized into two main frameworks: adaptation and teacher-student.:
1、Teacher-Student refers to (Miki et al., 2022a) 基于T-S的方法
2、MONO means (Agarwal et al., 2023)
3、AMP means Adversarial Motion Priors (Wu et al., 2022; Escontrela et al., 2022)
4、RMA means Rapid Motor Adaptation (Kumar et al., 2021) 基于Adaption的方法
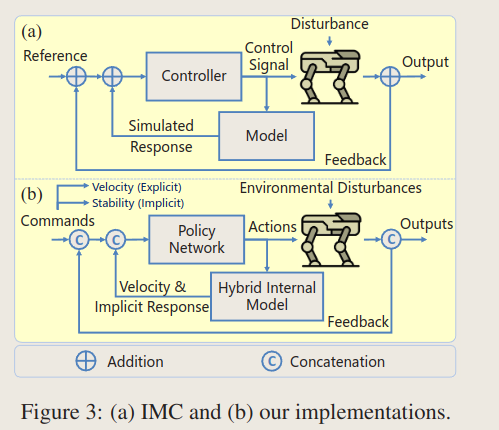
其中Ot包含:
采用对比学习:

2.13 DayDreamer: World Models for Physical Robot Learning
CoRL 2022
这是model-based的方法
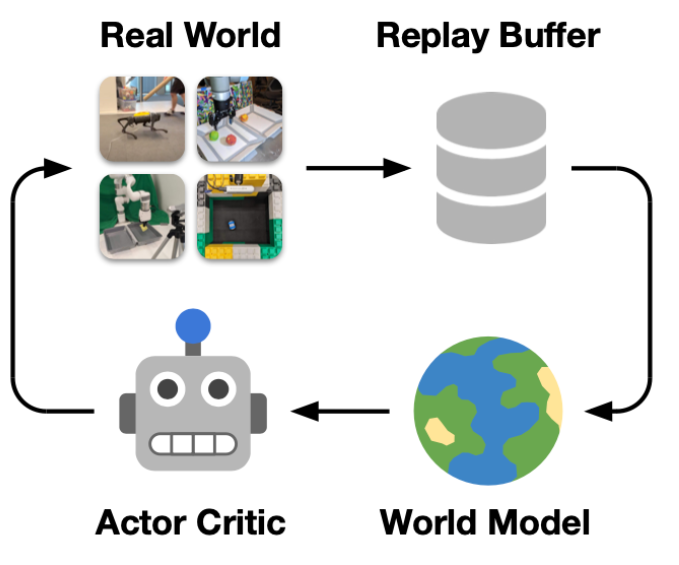
agent和环境进行交互,得到的数据先学一个World Model,给定state和action预测next state
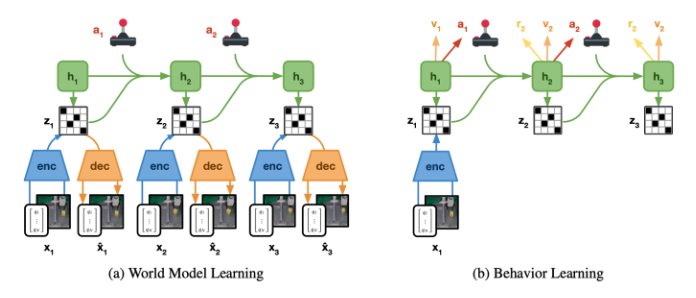
agent和环境进行交互,得到的数据先学一个World Model,给定state和action预测next state,当然都是在latent space里的,所以上图a有一个encoder和decoder去训练这个embedding state。
而你会发现这里还有个h,h是rnn的state,然后这个state是个概率状态,所以z是从h里sample出来的。
实际训练的时候就用右边图b这种方式在latent space里训练policy。
然后根据Plan2explore,实际在训练时会训练两个policy,一个policy用于给world model收集数据,另一个policy用于完成某种任务。因此在world model里面会有两种reward function,一种是Intrinsic reward,用于探索world以提供更高质量的数据给world model,一种是task reward用于训练完成任务的policy。
但作者在文章里似乎就用了DreamerV2,没有Intrinsic reward
在实验部分作者准备了四种不同的机器人:

选这四个机器人是因为可以包括连续和离散的动作空间,参数和视觉观测空间,绸密和稀疏的奖励函数
2.14 Coupling Vision and Proprioception for Navigation of Legged Robots
CVPR 2022
2.15 Learning vision-guided quadrupedal locomotion end-to-end with cross-modal transformers
ICLR 2022
2.16 Learning a Unified Policy for Whole-Body Control of Manipulation and Locomotion
本文的目标是将四足机器人本身的运动和机械臂的操作作为一个整体来进行控制,控制器可以同时输出四足的运动策略和机械臂的操作策略
2.22 Rapid Locomotion via Reinforcement Learning
mit 2022.5.5 arxiv

狗子的快速移动
used RL to train Mini Cheetah to learn high-speed movements over natural terrains.
3. 后记
这篇博客暂时记录到这里,日后我会继续补充。