介绍
本来想写一个自动化发布微信公众号的小绿书的脚本。但是微信公众号官网没有小绿书的接口。
想着算了吧,写都写了,那就写一个微信普通文章的脚本吧。
写完了 就想着把脚本分享出来,给大家一起交流下。
水平有限,大佬轻喷。
思路
1,获取百度热搜列表
2,给热搜图片加上文字标题
3,上传图片到微信公众号素材库
4,新建微信公众号草稿
5,发布草稿
前期准备
1,注册微信公众号,获取AppID和AppSecret
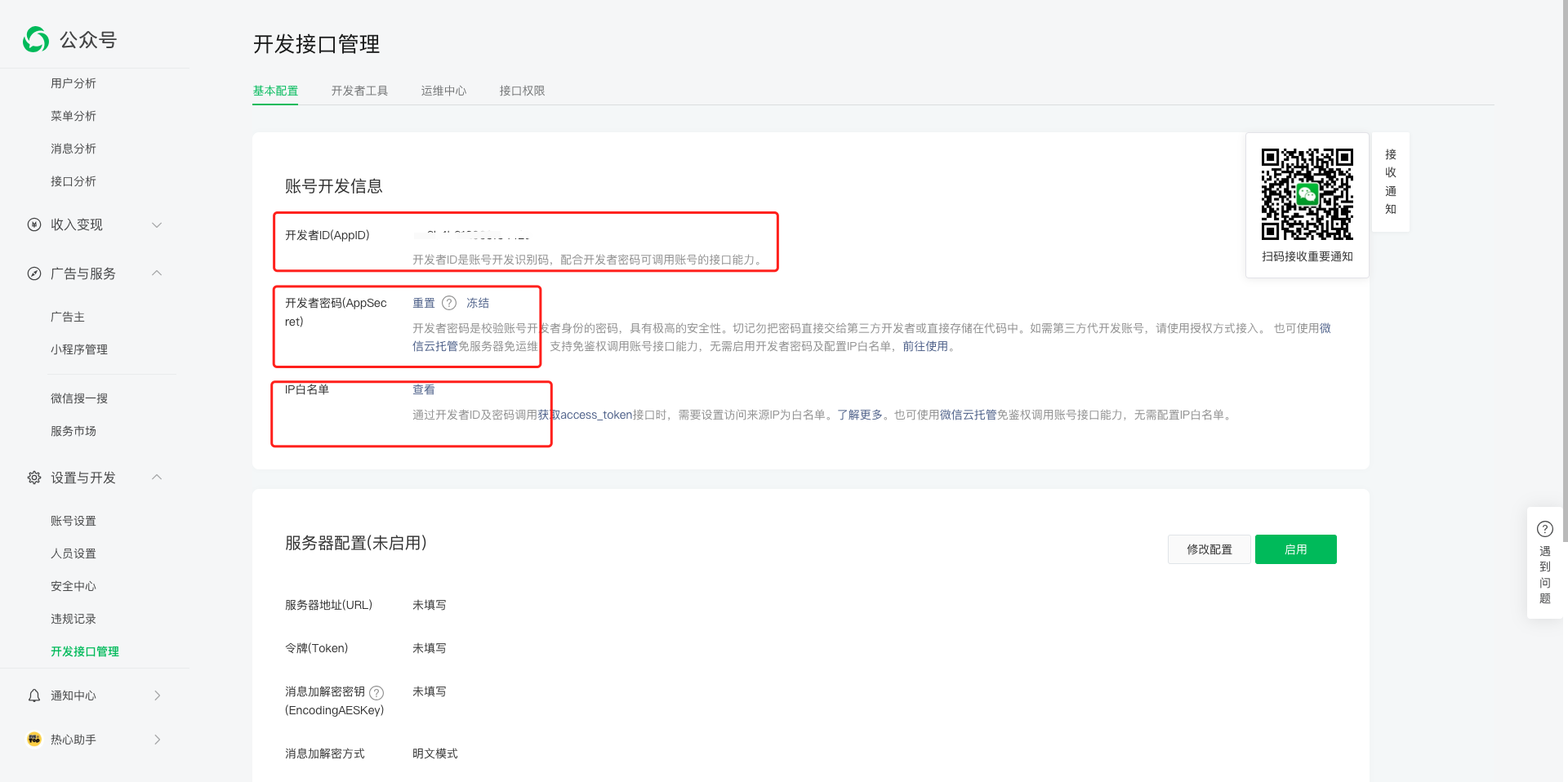
2,微信公众号接口文档( 文档链接),参照文档进行接口调用
3,微信公众号设置IP白名单
在服务器上面获取出口外网ip
curl -s https://ipinfo.io/ip
环境要求
1,我使用的是python12
2,依赖就需要安装PIL库,其他库都是默认安装的
(py12-ai-django5) [root@gtp-test01-cyt wxmp]# python -V
Python 3.12.4
#
图片已保存到 hotimg/orgimg/2.png
图片已保存到 hotimg/orgimg/3.png
图片已保存到 hotimg/orgimg/4.png
图片已保存到 hotimg/orgimg/5.png
图片已保存到 hotimg/orgimg/6.jpg
图片已保存到 hotimg/orgimg/7.jpg
图片已保存到 hotimg/orgimg/8.png
图片已保存到 hotimg/orgimg/9.png
图片已保存到 hotimg/orgimg/10.jpg
图片已保存到 hotimg/orgimg/11.png
图片已加文字 hotimg/nowimg/2.png
图片已加文字 hotimg/nowimg/3.png
图片已加文字 hotimg/nowimg/4.png
图片已加文字 hotimg/nowimg/5.png
图片已加文字 hotimg/nowimg/6.jpg
图片已加文字 hotimg/nowimg/7.jpg
图片已加文字 hotimg/nowimg/8.png
图片已加文字 hotimg/nowimg/9.png
图片已加文字 hotimg/nowimg/10.jpg
图片已加文字 hotimg/nowimg/11.png
新建草稿成功--{'media_id': 'V4QdIouS1e-m5FaD0_0keQQMcEMKo0-3YjLoF_JqJohqywWC3Byyr81SXUi1TheO', 'item': []}
{'errcode': 0, 'errmsg': 'ok', 'publish_id': 2247483801, 'msg_data_id': 2247483801}
获取接口token
1,由于access_token的有效期只有2小时,故需要定时刷新。
2,这里使用app_token.yaml来保存获取到的token以及时间;token在时效内返回保存的token,超过时效会获取新的token
def get_token(app_id='', # 微信公众号AppIDapp_secret='' # 微信公众号AppSecret ):"""获取token:return:"""url = f'https://api.weixin.qq.com/cgi-bin/token?grant_type=client_credential&appid={app_id}&secret={app_secret}'res = requests.get(url=url)result = res.json()if result.get('access_token'):token = result['access_token']print(f"获取token成功:{token[:14]}****")return tokenelse:print(f"获取token失败--{result}")def refresh_token():"""token刷新机制:return:"""app_token_path = os.path.dirname(os.path.abspath(__file__)) + os.sep + 'app_token.yaml'try:# 读取时间和tokenif not os.path.exists(app_token_path):with open(app_token_path, 'w+') as f:f.write('')cfg_token = yaml_read(app_token_path)t = cfg_token['time']record_token = cfg_token['token']cur_time = time.time()# token时间在7200s之内,返回tokenif 0 < cur_time - t < 7200:# print(f"token时效内")return record_token# token过期,刷新时间和tokenelse:# print('token已过期')token = get_token()if token:data = {'time': time.time(), 'token': token}yaml_clear(app_token_path)yaml_write(data, app_token_path)return tokenexcept TypeError:# 获取初始时间和tokenprint('获取初始token')token = get_token()data = {'time': time.time(), 'token': token}yaml_write(data, app_token_path)return tokendef yaml_read(file):"""yaml文件读取:param file::return:"""with open(file=file, mode="r", encoding="utf-8") as f:data = yaml.safe_load(f.read())return datadef yaml_write(data, file):"""yaml文件写入:param data::param file::return:"""with open(file, 'a', encoding='utf-8') as f:yaml.dump(data,stream=f,allow_unicode=True, # 避免unicode编码问题sort_keys=False # 不自动排序 )def yaml_clear(file):"""yaml文件清空:param file::return:"""with open(file, 'w', encoding='utf-8') as f:f.truncate()
获取热搜
这里我是找的网上别人写好的接口。简单快速方便
https://dabenshi.cn/other/api/hot.php?type=douyinhot // 抖音热点 https://dabenshi.cn/other/api/hot.php?type=toutiaoHot // 头条热榜 https://dabenshi.cn/other/api/hot.php?type=baidu // 百度热搜
我这里使用的是百度热搜。
获取热搜数据
# 获取热搜数据 def get_hotdata():'''获取百度热搜的数据url网上找的: https://dabenshi.cn/other/api/hot.php?type=baidu'''url = f"https://dabenshi.cn/other/api/hot.php?type=baidu"hotdata = [] # 存储所有的热搜数据 res = requests.get(url=url)result = res.json()hotdata = result['data'][1:11] # 这里我只拿了10条数据
# 数据就是一个打列表,里面有字典
hotdata =[
{"index": 2,"title": "外交部回应是否邀请特朗普访华","desc": "1月21日,外交部就“中方是否邀请特朗普访华”一事做出回应:愿同美国新政府保持沟通,加强合作。","pic": "https:\/\/fyb-2.cdn.bcebos.com\/hotboard_image\/4d0700b48e6c791e29f1e231e24af061","url": "https:\/\/www.baidu.com\/s?wd=%E5%A4%96%E4%BA%A4%E9%83%A8%E5%9B%9E%E5%BA%94%E6%98%AF%E5%90%A6%E9%82%80%E8%AF%B7%E7%89%B9%E6%9C%97%E6%99%AE%E8%AE%BF%E5%8D%8E&sa=fyb_news&rsv_dl=fyb_news","hot": "797.6万","mobilUrl": "https:\/\/www.baidu.com\/s?wd=%E5%A4%96%E4%BA%A4%E9%83%A8%E5%9B%9E%E5%BA%94%E6%98%AF%E5%90%A6%E9%82%80%E8%AF%B7%E7%89%B9%E6%9C%97%E6%99%AE%E8%AE%BF%E5%8D%8E&sa=fyb_news&rsv_dl=fyb_news"}
]
下载热搜图片
其实就是把热搜数据里面的pic图片保存到了本地
这样一会就好给图片加上标题文字了
def get_hotimg(hotdataall):"""下载热搜图片hotdata: 所有数据"""if hotdataall:for hotdata in hotdataall:try:# 发送HTTP GET请求获取图片数据response = requests.get(hotdata['pic'], timeout=10)# 检查请求是否成功if response.status_code == 200:# 获取Content-Type头信息content_type = response.headers.get('Content-Type')# 根据Content-Type判断图片类型image_extension = Noneif content_type == 'image/jpeg':image_extension = '.jpg'elif content_type == 'image/png':image_extension = '.png'elif content_type == 'image/gif':image_extension = '.gif'else:raise Exception(f"Unsupported image type: {content_type}")# 以二进制写模式打开文件,并将图片数据写入文件img_name = "hotimg/orgimg/" + str(hotdata['index']) + image_extensionimg_name_new = "hotimg/nowimg/" + str(hotdata['index']) + image_extensionwith open(img_name, 'wb') as file:file.write(response.content)print(f'图片已保存到 {img_name}')hotdata['image_path'] = img_namehotdata['image_path_new'] = img_name_newelse:print(f'下载图片失败,状态码: {response.status_code}')except requests.RequestException as e:print(f'请求出现异常: {e}')
给图片加上标题文字
# 给图片加上文字if hotdata:for hotdata_in in hotdata:image_path = hotdata_in['image_path']image_path_new = hotdata_in['image_path_new']text = hotdata_in['title']max_width = 500add_text_to_image(image_path, image_path_new, text=text, max_width=max_width)
def add_text_to_image(image_path, image_path_new, text='', max_width=500):'''给图片添加文字'''image = Image.open(image_path)draw = ImageDraw.Draw(image)width, height = image.sizefont_size = max(30, int(width * 0.03))font = ImageFont.truetype("ttf/feihuasongti.ttf", font_size)text_color = (255, 255, 255) # 黑色字体shadow_color = (0, 0, 0) # 黑色阴影# text_width, text_height = draw.textsize(text, font=font)# 获取文本尺寸bbox = draw.textbbox((0, 0), text, font=font)text_width = bbox[2] - bbox[0]text_height = bbox[3] - bbox[1]while text_width > width - 30:font_size -= 1font = ImageFont.truetype("ttf/feihuasongti.ttf", font_size)# text_width, text_height = draw.textsize(text, font=font)# 获取文本尺寸bbox = draw.textbbox((0, 0), text, font=font)text_width = bbox[2] - bbox[0]text_height = bbox[3] - bbox[1]# 计算文本位置x = width - text_widthy = height - text_height - 30# 绘制文本阴影draw.text(((x/2) + 2, y + 2), text, font=font, fill=shadow_color)draw.text((x / 2, y), text, font=font, fill=text_color)image.save(image_path_new)print(f'图片已加文字 {image_path_new}')
类似这样,在图片底部加上文字

上传图片素材
这块会返回上传到素材url。这个url地址,可以在文章里面使用
def add_media(hotdataall):"""新增临时素材: https://api.weixin.qq.com/cgi-bin/media/upload?access_token=ACCESS_TOKEN&type=TYPE上传图文消息内的图片获取URL, 新增永久素材: https://api.weixin.qq.com/cgi-bin/media/uploadimg?access_token=ACCESS_TOKEN新增其他类型永久素材, 新增永久素材: https://api.weixin.qq.com/cgi-bin/material/add_material?access_token=ACCESS_TOKEN&type=TYPE"""# url = f"https://api.weixin.qq.com/cgi-bin/media/upload?access_token={refresh_token()}&type=image"url = f"https://api.weixin.qq.com/cgi-bin/media/uploadimg?access_token={refresh_token()}"if hotdataall:for hotdata in hotdataall:with open(hotdata['image_path_new'], 'rb') as fp:files = {'media': fp}res = requests.post(url, files=files)res = json.loads(str(res.content, 'utf8'))hotdata["wx_img_url"] = res['url']
新建草稿
这里会返回草稿的ID
def add_draft(hotdataall):'''新建草稿'''url = f'https://api.weixin.qq.com/cgi-bin/draft/add?access_token={refresh_token()}'# content = "<img src='https://mmbiz.qpic.cn/sz_mmbiz_jpg/hY63os7Ee2Ro6WVkfj9nvfDdpONqLwr48J2eQEYXygs3cWibLvQTHAveYWNnXOOWHO3jZldO3fr7quVj6V0X5uA/0?wx_fmt=jpeg'/>"# 读取文件html# 打开HTML文件并读取内容with open('content.html', 'r', encoding='utf-8') as file:html_content_template = file.read()# 动态生成草稿content内容全部,先定义一个变量html_content = ""# 动态生成草稿content内容片段for hotdata in hotdataall:# 判断热搜第一if hotdata['index'] == 2:title_color = "red"else:title_color = "black"# 定义变量hot_context = {'num': hotdata['index'] - 1,'url_img': hotdata['wx_img_url'],'title_color': title_color,'title_title': hotdata['title'],'describe': hotdata['desc'],}# 替换变量substitute_data = string.Template(html_content_template)result = substitute_data.safe_substitute(hot_context)html_content += resultdata = {"articles": [{"title":"标题","author":"作者","digest":"描述","content":html_content,"thumb_media_id":"封面素材ID","need_open_comment":1,"only_fans_can_comment":1}]}res = requests.post(url=url, data=json.dumps(data, ensure_ascii=False).encode('utf-8'))if res.status_code == 200:result = json.loads(res.content)if result.get('media_id'):print(f'新建草稿成功--{result}')return result['media_id']else:print(f'新建草稿失败--{result}')else:print(f'新建草稿失败--{res.text}')
发布草稿
def free_publish(media_id):'''发布草稿'''url = f'https://api.weixin.qq.com/cgi-bin/freepublish/submit?access_token={refresh_token()}'data = {"media_id": media_id}res = requests.post(url=url, json=data)res = json.loads(str(res.content, 'utf8'))print(res)
源码
gitee:https://gitee.com/ccsang/wxmp
关注我的公众号
这个公众号的文章就是这个脚本定时发送的。

希望这个脚本对你有用。欢迎交流
最近想弄些PRA,自动化弄下那些没有接口的应用的。有大佬指教吗。