介绍
2017年,谷歌发布了一篇具有革命性意义的论文,题为《Attention is All You Need》(注意力是你所需要的一切)。这篇论文引发了我们今天所经历的AI革命,并引入了Transformer模型。Transformer已经成为如今几乎所有顶级大型语言模型(LLM)的核心架构。
Transformer的优势与成本
Transformer的强大主要归功于其注意力机制。面对一个令牌序列时,Transformer能够一次性处理整个序列,利用注意力机制捕捉整个序列中的依赖关系,从而提供高质量的输出。然而,这种强大能力的代价是:输入序列长度的二次方复杂度。这一成本限制了Transformer在处理更长序列时的扩展能力。
循环模型
另一方面,循环模型(Recurrent Models)不存在这种二次方复杂度的问题。它们并非一次性处理整个序列,而是逐步进行,将序列中的数据压缩到一个被称为“隐藏状态”的压缩记忆中。这种线性复杂度提升了循环模型的可扩展性。然而,循环模型的性能并未能超越Transformer。
引入泰坦模型
本文我们将探讨谷歌研究团队的一篇新论文《Titans: Learning to Memorize at Test Time》(泰坦:在测试时学习记忆),它提出了一种新的模型架构——泰坦(Titans)。该模型在缓解Transformer二次方复杂度问题的同时,显示出了令人期待的性能。泰坦模型的设计灵感来源于人类大脑的记忆工作方式。论文中提到一句有趣的话:“记忆是一个基本的心理过程,也是人类学习不可分割的组成部分。没有一个正常运作的记忆系统,人类和动物将被限制在基础的反射和刻板行为中。”

深度神经长期记忆模块
泰坦论文的一项关键贡献是深度神经长期记忆模块。首先,我们来理解什么是长期记忆模块,然后探讨它如何整合到泰坦模型中。
与循环神经网络中将记忆编码为固定向量不同,神经长期记忆模块是一个神经网络模型,包含多层结构,将过去的抽象历史编码到模型参数中。训练这种模型的一种方法是让模型记住其训练数据。然而,记忆化(memorization)已知会限制模型的泛化能力,并可能导致性能下降。
记忆化但不过拟合
研究人员设计了一种独特的方法,创建了一个能够记忆但不会过拟合于训练数据的模型。该方法借鉴了人类记忆的类比。当我们遇到令人意外的事件时,我们更有可能记住这个事件。神经长期记忆模块的学习过程正是为了反映这一点。
建模“惊讶”
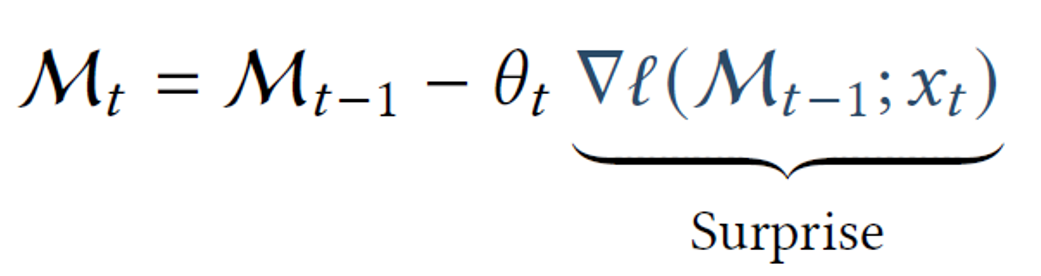
研究人员如何建模“惊讶”,可以通过下图定义进行理解。
MtM_tMt 表示在时间 ttt 的神经长期记忆模块。它通过前一时间步的参数和一个“惊讶”元素(建模为梯度)进行更新。如果梯度较大,说明模型对输入更“惊讶”,从而导致模型权重更显著的更新。然而,这种定义并不完美,因为模型可能会错过“惊讶”发生后紧接着的重要信息。
建模“过去的惊讶”
从人类的角度来看,一个令人惊讶的事件不会长期持续令人惊讶,但它仍然是难忘的。我们通常会适应令人惊讶的事件。然而,这个事件可能足够令人惊讶以吸引我们的注意力,贯穿更长的时间段,从而记住整个时间段。
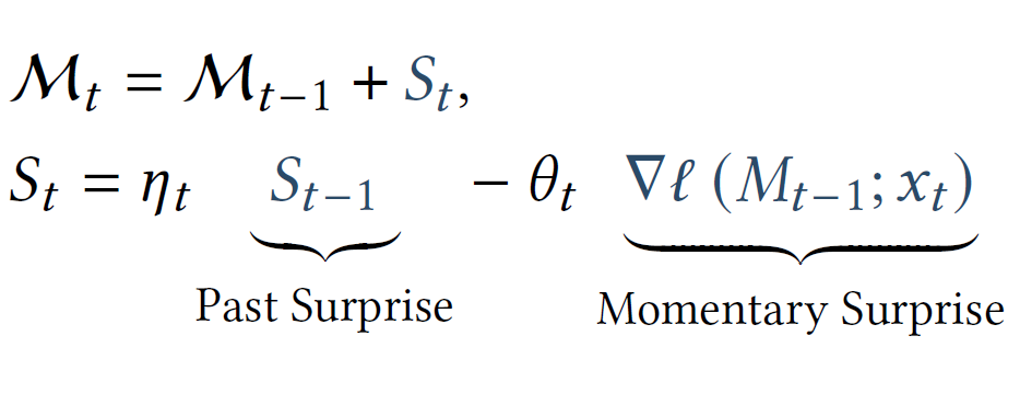
改进后的建模定义包括了“过去的惊讶”。现在,我们通过前一权重状态和一个惊讶组件(记作 StS_tSt)来更新神经长期记忆权重。惊讶组件现在是随着时间测量的,由前一惊讶(有衰减因子)和当前瞬间的惊讶组成。
建模“遗忘”
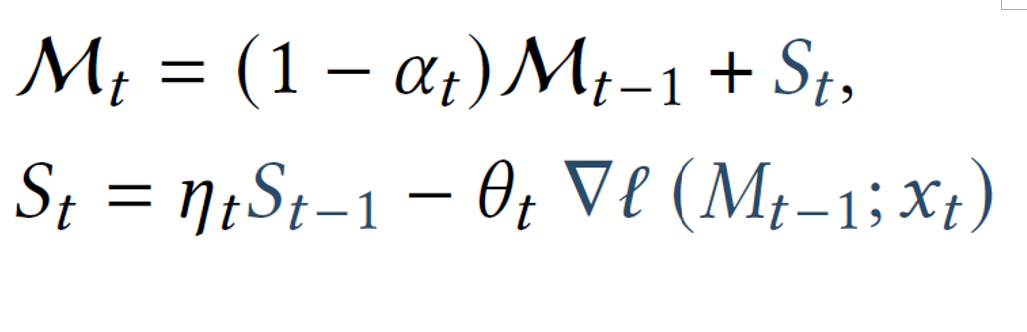
处理非常长的序列(例如,数百万个令牌)时,管理哪些过去信息应被遗忘是至关重要的。从下图的定义中可以看到最终的建模。这些定义与上一部分的定义相同,只是我们新增了一个自适应遗忘机制,记作 ααα,也称为“门控机制”。这允许记忆遗忘不再需要的信息。
损失函数
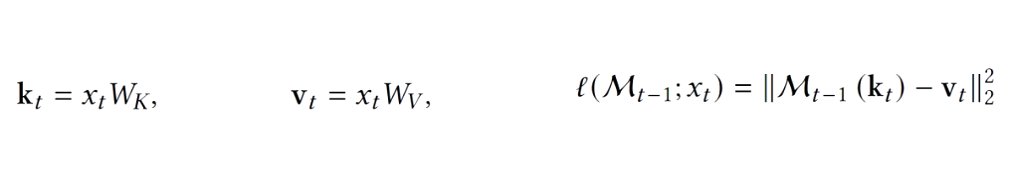
损失函数通过上述方程定义。损失的目标是建模关联记忆,通过将过去的数据存储为键值对,并教会模型在键和值之间建立映射。与Transformer类似,线性层将输入投射为键和值。然后,损失函数衡量记忆模块学习键值关联的效果。
需要澄清的是,模型不会一次性处理整个序列,而是逐步处理,在权重中累积记忆信息。
泰坦架构 #1 — 记忆作为上下文(MAC)
论文提出了几种不同的架构。第一种称为“记忆作为上下文”(MAC)。下图展示了该架构:
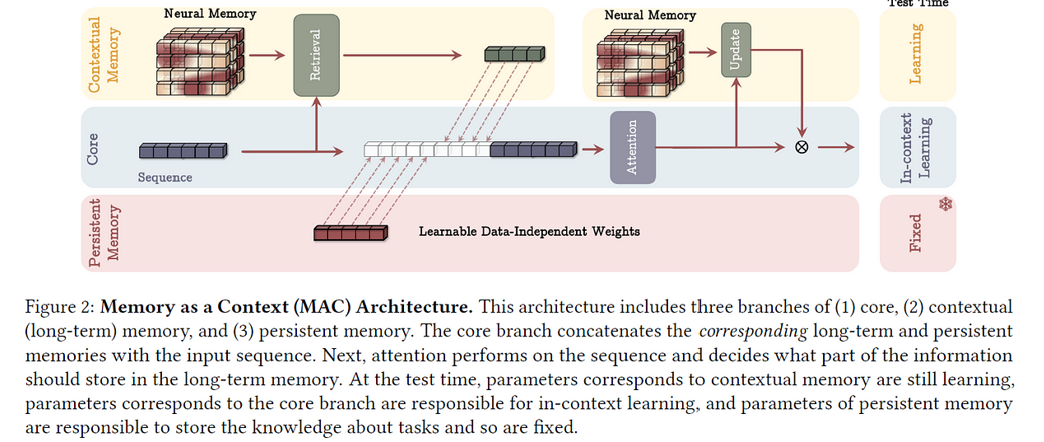
模型由三个组件组成:持久记忆、核心和上下文记忆。对于一个长输入序列,我们将其分割成较小的序列。图中的“核心”组件实际上是一个分块的序列。
持久记忆
我们通过向序列的开头添加可学习的与数据无关的权重来整合持久记忆。这实际上是可学习的令牌,存储全局信息,不受输入影响。
上下文记忆
上下文记忆依赖于上下文,由深度神经长期记忆模块组成。我们通过神经长期记忆模块的前向传播,将输入分块序列作为输入,检索记忆令牌。
核心组件
核心组件将所有内容结合在一起,利用一个注意力模块,输入包含持久记忆、上下文记忆和输入本身的信息扩展序列。