欢迎阅读我们的新栏目——“微前沿”!
“微前沿”汇聚了微软亚洲研究院最新的创新成果与科研动态。在这里,你可以快速浏览研究院的亮点资讯,保持对前沿领域的敏锐嗅觉,同时也能找到先进实用的开源工具。
本期内容速览
01. 强可控视频生成模型 DragNUWA
02. LLM Retriever:通过定制化样本检索器来提高大语言模型的上下文学习效果
03. 解码大脑信号重建视觉感知图像
04. PromptBench:首个大语言模型提示鲁棒性的评测基准
arXiv精选
强可控视频生成模型 DragNUWA

论文链接:https://arxiv.org/abs/2308.08089
项目主页:https://www.microsoft.com/en-us/research/project/dragnuwa/
在人工智能与计算机图形学领域不断取得突破的今天,视频生成技术已成为领域内的研究焦点。尽管传统的视频生成模型,如 NUWA、Phenaki 和 Gen-2,在一定程度上实现了基于文本的视频生成,但在细粒度控制方面仍有不足。而在电影制作和短视频创作领域,导演和创作者对精细的运镜以及复杂且可控的角色动作都有着极高的要求,可是这些需求目前却难以通过现有的视频生成模型实现。
为此,微软亚洲研究院的研究团队研发了强可控视频生成模型 DragNUWA,革新了当前的视觉体验。受到 DragGAN 采用拖拽方式编辑图像的启发,DragNUWA 允许用户直接在图像中拖拽物体或背景,然后模型会自动将拖拽操作转化为合理的运镜或物体的运动,并生成相应的视频。通过融合文本、图像和轨迹三个关键控制因素,DragNUWA 在语义、空间和时间三个层面均实现了卓越的可控视频生成能力。

图1:DragNUWA的两种轨迹控制方式。拖拽背景可以生成各种镜头效果(左图),拖拽物体可以生成人物复杂轨迹(右图)。
DragNUWA 支持三个关键控制输入:文本(p),图像(s)和轨迹(g)。为了解决当前仅有视频文本对数据的难题,DragNUWA 引入了轨迹采样器(Trajectory Sampler, TS)从开放领域视频的光流中提取轨迹。所提取的轨迹、初始帧图像和标注文本将通过多尺度融合器(Multiscale Fusion,MF)融入到 UNet 的每个 block。而为了解决轨迹稀疏的问题,DragNUWA 会通过自适应训练(Adaptive Training,AT)逐步从完整的光流切换到稀疏的轨迹,以确保视频生成的稳定性。
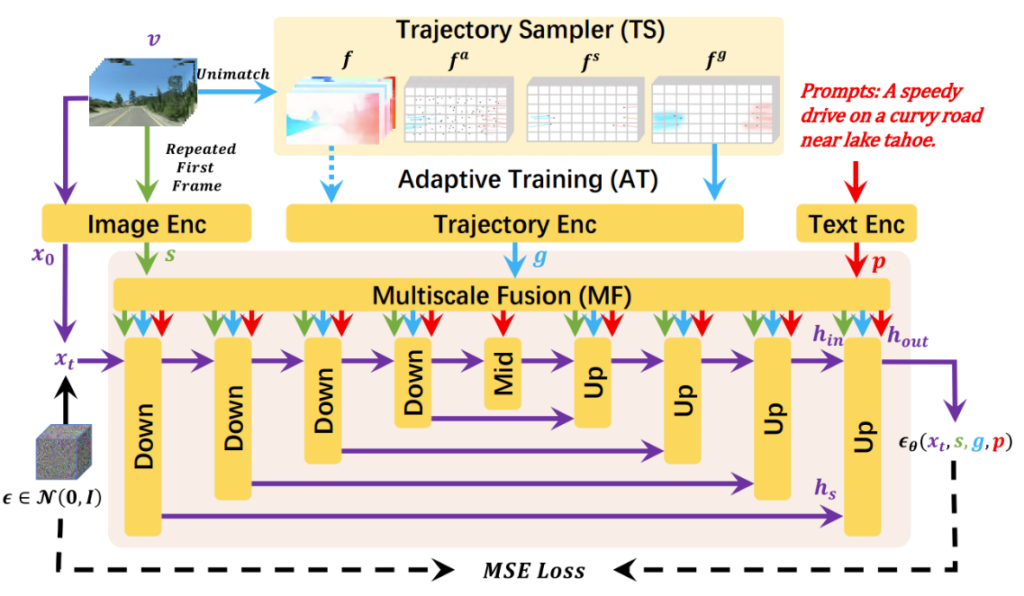
图2:DragNUWA 架构图
让我们想象一下,当你在欣赏一幅美丽的艺术作品时,通过 DragNUWA 的力量,它能够按照你的意愿展现出生动的画面;或者在拍摄一部动作片时,让主角在关键时刻“拥有”震撼人心的武艺。这些都将得益于 DragNUWA 强大的可控视频生成能力。DragNUWA 为包括导演、摄影师和视频创作者们在内的整个视觉作品领域打开了全新的可能性,可能在未来把视频生成技术带入一个全新的可控时代。

图3:DragNUWA 生成演示
LLM Retriever:通过定制化样本检索器来提高大语言模型的上下文学习效果

论文链接:https://arxiv.org/pdf/2307.07164
项目链接:https://github.com/microsoft/LMOps
如今的大语言模型展现出了惊人的上下文学习能力:不需要对语言模型的参数进行微调,只需要摆放几个上下文样本,语言模型就可以学会执行这个任务。但相关研究表明,语言模型上下文学习的效果对于样本的选择非常敏感。因此,如何自动从样本池选择合适的样本就成为了一个重要的研究问题。
微软亚洲研究院的研究员们在针对这一问题的研究过程中发现,语言模型本身的反馈信号可以作为上下文样本选择的可靠依据。不同的样本对于语言模型输出正确答案的影响并不相同,那些能提高正确答案概率的样本可以被视为高质量的上下文样本。基于这一观察,研究员们利用语言模型的反馈信号来训练定制化的样本检索器 LLM Retriever,以提高上下文学习的效果。
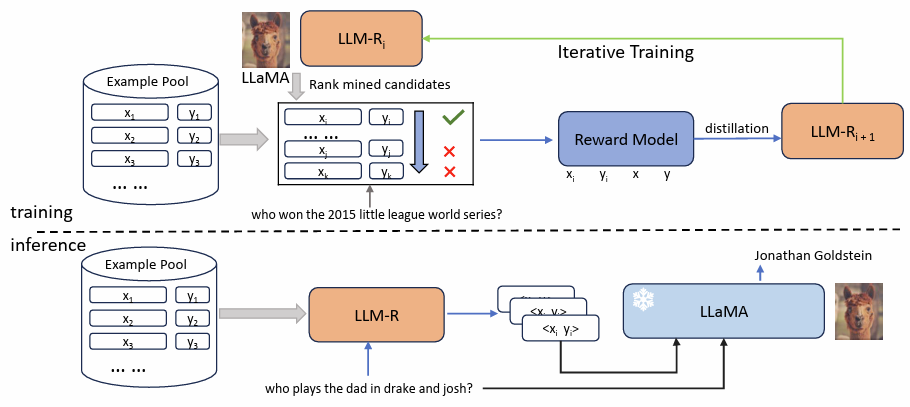
图4:LLM Retriever 模型训练和推理流程
具体来说,在训练阶段,首先用语言模型对每一个候选的上下文样本打分,能够使得正确答案概率最大的样本被视为正例,其它的被视为负例。然后利用这些自动标注的数据来训练一个奖励模型,以捕捉更加细粒度的监督信号,再对奖励模型进行知识蒸馏,得到一个高效的检索器 LLM Retriever。这一训练流程可以迭代进行,从而不断提高检索器的效果。
在推理阶段,根据训练得到的检索器,离线把样本池建成一个方便快速查找的索引。对于每条测试数据,在索引中查找最相似的若干个样本,然后送给大语言模型做上下文学习,输出最终的预测结果。在整个过程中,语言模型不进行任何参数微调。
实验结果表明,在包含30个数据集的评测基准上,LLM Retriever 能够检索出与测试数据具有相似模式的样本,从而显著提高各种任务的上下文学习效果,并且对于训练阶段没有见过的任务和语言模型也具备很好的泛化能力。LLM Retriever 是微软亚洲研究院自然语言计算组关于如何增强语言模型能力的研究的一部分,未来研究员们还将继续在这方面进行深入的探索。
“透视”大脑:解码大脑信号重建视觉感知图像

论文链接:https://arxiv.org/abs/2308.02510
是否有可能只根据非侵入式设备获取的大脑信号,就完全重建被试主体所看到的视觉内容?
近年来,得益于神经科学和人工智能的最新进展,科学家们已经能够记录视觉引发的大脑活动,并通过计算方法模拟人类的视觉认知能力。其中,有一种大脑活动电生理信号称为脑电(Electroencephalograph, EEG)信号。EEG 脑电信号是一种通过放置在人类头皮上的便携电极,可低成本记录大脑时间动态的电生理信号。这类脑电活动生理信号相比较磁共振成像等技术,具备低成本、采集方便的优点,但是,EEG 脑电信号采集会受到电极放置错误或身体运动的影响,进而导致数据中出现严重的伪迹,并且其信噪比较低,因此,使用脑电信号重建视觉感知仍然十分困难。
在这篇论文中,微软亚洲研究院的研究员提出了 NeuroImagen, 通过多级解码方式,可以从 EEG 信号中解码出不同粒度的样本语义信息和像素语义信息,最后通过输入已预训练的扩散模型可以重建视觉感知的图像。其中,样本级别的语义信息提供了观看图像中主要类别或者总体描述等粗粒度信息,这些信息可以比较准确地提取与解码;像素级别的语义信息则提供了观看图像的颜色、位置、形状等细粒度信息,这些信息较难以提取,但对重建图片的细节非常重要。
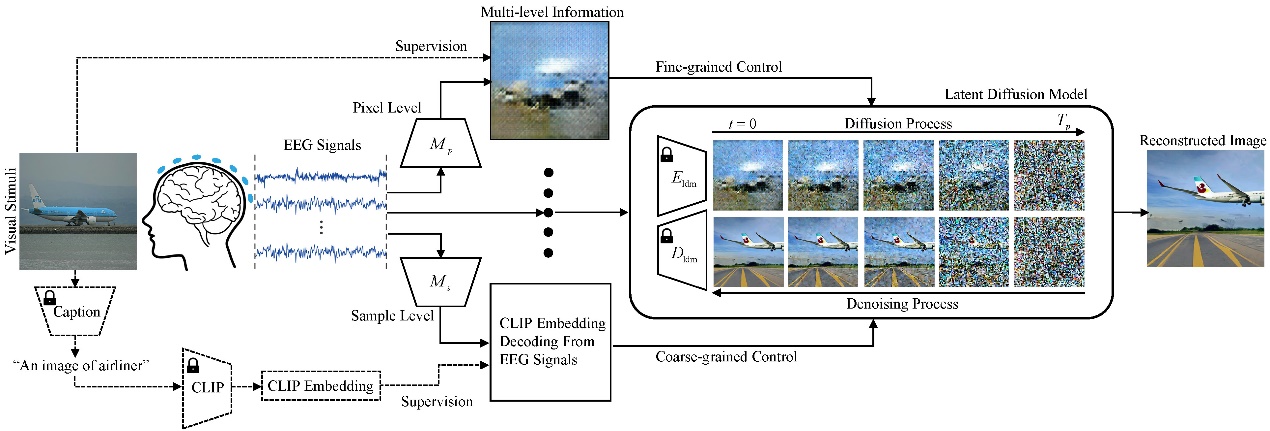
图5:NeuroImagen 多级解码大脑信号重建感知图像
实验结果表明,NeuroImagen 在根据 EEG 信号重建视觉图像的语义准确度、图片质量、结构准确性等方面上均优于其它前沿的重建方法。这项研究初步验证了将人类视觉认知与复杂的脑电信号联系起来的可行性,进而有可能帮助那些因为神经系统受损而失去视觉功能的人恢复部分视觉能力。研究员们预期这些发现将推动人工智能、认知科学和神经科学之间的合作,探索人类视觉认知过程之谜。
开源工具
PromptBench: 首个大语言模型提示鲁棒性的评测基准

文章链接:https://arxiv.org/abs/2306.04528
代码链接:https://github.com/microsoft/promptbench
所有大模型评测的研究汇总:llm-eval.github.io
作为连接人类与大模型的桥梁,大模型对 “Prompt (提示词)“究竟有多敏感?同样的 prompt,可能写错个单词、写法不一样,都会出现不一样的结果。到底应该如何写合适的提示词?
为了尝试回答这些问题,微软亚洲研究院的研究员们构建了首个大语言模型提示鲁棒性的评测基准 PromptBench,以深入探究大模型在处理对抗提示(adversarial prompts)的鲁棒性。研究还利用 Attention “可视化分析”了对抗提示的输入关注分布,并且对不同模型产生的对抗提示进行了“迁移性分析”,最后对鲁棒提示和敏感提示的词频进行了分析,以帮助终端用户更好地写出 prompt。
研究得到了几个关键的结果。首先,“不同种类的攻击的有效性差距很大“,其中 word-level 的攻击最强,导致所有数据集的平均性能下降33%。字符级别的攻击排名第二,导致大部分数据集的性能下降20%。UL2 的鲁棒性明显优于其他模型,其次是 T5 和 ChatGPT,Vicuna 的鲁棒性最差。UL2、T5 和 ChatGPT 的鲁棒性在各个数据集中都有所不同,UL2 和 T5 在情感分类(SST-2)、大部分 NLI 任务以及阅读理解(SQuAD V2)的攻击中表现出较好的鲁棒性。少样本提示的鲁棒性在所有数据集上都要优于零样本提示。此外,虽然 Task-oriented 的提示在总体鲁棒性上稍微优于 Role-oriented 提示,但两者在不同的数据集和任务中各有优势。
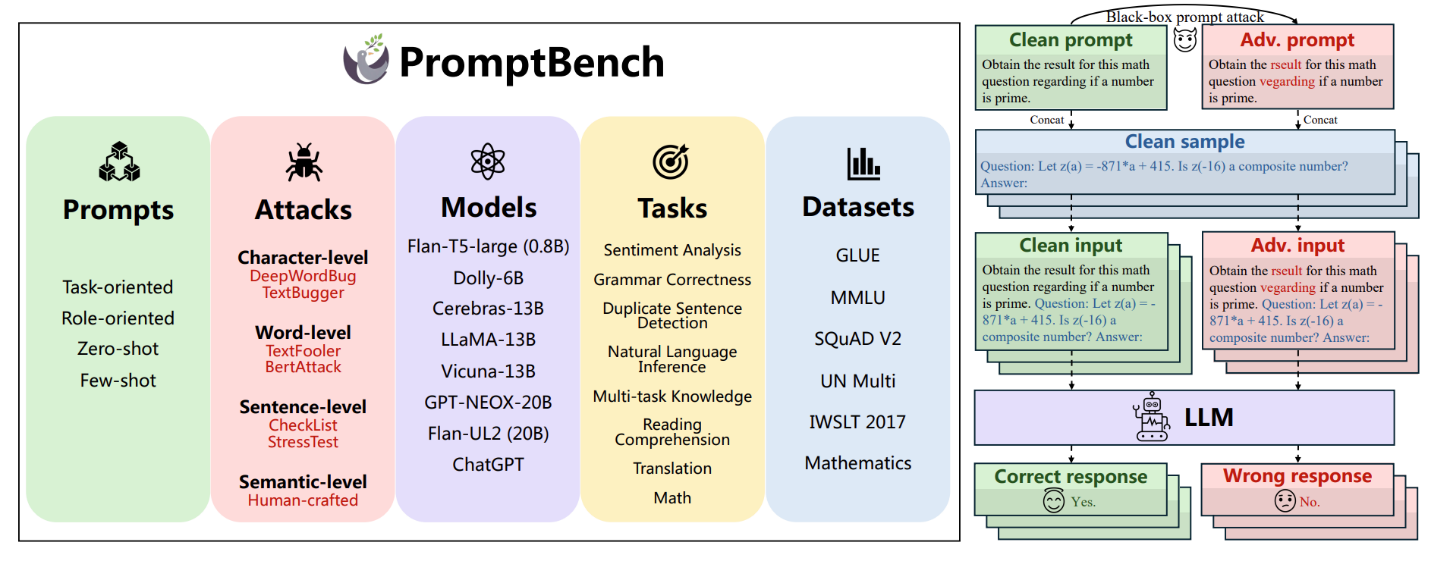
图6:PromptBench 概览(左图),prompt 攻击示意图(右图)
研究员们还进行了可迁移性分析、词频分析等,以全面了解大模型对提示的对抗鲁棒性。最后研究员也提出了一些可能的应对策略:
1. 输入预处理:直接检测和处理可能的对抗样本,如检测错别字、无关的序列,并提高提示的清晰度和简洁度。
2. 在预训练中包含低质量数据:低质量数据可以作为可能的对抗样本,在预训练中包含低质量数据可能会对多样化的输入有更好的理解。
3. 探索改进微调方法:研究更佳的微调技术可能会提高鲁棒性。正如研究之前展示的一些情况,比如 T5 和 UL2 模型比 ChatGPT 的鲁棒性更好,这暗示了大规模监督微调的潜在优势。

![[FPGA IP系列] BRAM IP参数配置与使用示例](https://img-blog.csdnimg.cn/img_convert/bb90386cec9df272311537322199e691.png)