一、引言
在工作日常里,数据转换总是让人头疼?别急,今天揭秘一个超级实用的Python技巧,帮你轻松搞定各种数据格式转换,提升工作效率不是梦!
场景1:你手头有一堆CSV格式的(逗号分隔符)数据,其他部门或公司需要你提供其中几列关键数据,同时希望你加工下几列数据怎么办,手工拼接转换数据,费时费力?
场景2:其他部门提供了一堆Excel表格的(制表符分隔符)数据,但是你只想要其中几列关键数据,同时希望转成sql语句怎么办,手工拼接转换数据,费时费力?
场景3:其他公司提供了一堆TXT格式的(空格或竖线分隔符)数据,但是你只想要其中几列关键数据,同时希望转成json格式怎么办,手工拼接转换数据,费时费力?
二、场景思考
首先,我们经常遇到各种分隔符数据,比如:CSV文档,(逗号分隔符)数据;Excel表格文档,(制表符分隔符)数据;TXT文档,(空格或竖线分隔符)数据等。
其次,如果你只想要其中几列数据,或者对某列数据,添加前缀数据,或后缀数据,拼接重组转换成新的数据格式,怎么办,手工拼接转换数据,费时费力?
思考,是否可以编写一个通用的分隔符数据格式转换程序?批量转换数据格式,提高办公效率,答案是可以。
三、技术分享
1,首先,需要有一个常用分隔符检测方法。
def detect_delimiter(text: str) -> str:'''@方法名称: 探测字符串中的分隔符@中文注释: 探测字符串中的分隔符@入参:@param text str 文本字符串@出参:@返回状态:@return 0 失败或异常@return 1 成功@返回错误码@返回错误信息@param delimiter str 分隔符@作 者: PandaCode辉@weixin公众号: PandaCode辉@创建时间: 2024-12-19@使用范例: detect_delimiter('name,age,city')''''''在正则表达式中,| 是一个特殊字符,表示“或”的逻辑。例如,a|b 表示匹配 a 或 b。但是,当你直接使用 | 作为正则表达式时,它会被解释为“空字符串或空字符串”,这会导致匹配到字符串中的每一个位置,包括字符之间和字符串的开头和结尾。'''# 定义常见的分隔符列表delimiters = [',', '|', ';', ':', '\t']# 首先检查最常见的分隔符(逗号、竖线、分号、冒号、制表符)for delimiter in delimiters:# 使用正则表达式查找分隔符,确保对特殊字符进行转义rst = re.findall(re.escape(delimiter), text)# 检查分隔符是否真正用于分隔数据,而不是偶然出现# 例如,分隔符应该出现在多个位置if len(rst) > 1:return delimiter# 如果没有找到常见的分隔符,检查是否只包含制表符作为分隔符if re.match(r'^[^t]*\t[^t]*$', text):return '\t'# 检查是否包含其他空白字符作为分隔符if re.findall(r'\s+', text):# 检查空白字符是否真正用于分隔数据if len(re.findall(r'\s+', text)) > 1:return ' '# 如果没有找到合适的分隔符,返回 Nonereturn None
2,然后,需要有一个输入数据模板检测方法。
def detect_input_template(input_text: str, delimiter: str = None) -> str:'''@方法名称: 检测文本输入模板@中文注释: 检测输入文本,将第一行数据列表,转成固定格式模板@入参:@param input_text str 文本字符串@出参:@返回状态:@return 0 失败或异常@return 1 成功@返回错误码@返回错误信息@param input_template str 输入模板@作 者: PandaCode辉@weixin公众号: PandaCode辉@创建时间: 2024-12-19@使用范例: detect_input_template('name,age,city')'''# If input_text is a string, convert it to a list of stringsif isinstance(input_text, str):input_text = input_text.strip().split('\n')# Detect delimiter if not provided# 检测分隔符if not delimiter:delimiter = detect_delimiter(input_text[0])# 如果还没分隔符,报错提示if not delimiter:return '没有检测到默认分隔符,也没有提供自定义分隔符,无法处理'print('delimiter:"' + delimiter + '"')# Split the first line to get the order of fieldsfields_order = input_text[0].strip().split(delimiter)# 将第一行数据列表,转成固定格式模板input_template = delimiter.join([f'x{i + 1}' for i, value in enumerate(fields_order)])return input_template
3,最后,需要根据输入和输出数据模板的转换数据格式方法。
def convert_data_format(input_text: Union[str, List[str]], delimiter: str = None, input_template: str = None,output_template: str = '', output_file: str = None) -> Union[List[str], str]:'''@方法名称: 根据输入和输出模板转换数据格式@中文注释: 根据输入和输出模板转换数据格式@入参:@param input_text Union[str, List[str]] 输入文本,可以是字符串、字符串列表或文件路径。@param delimiter str 用于分割数据的分隔符。如果为None,将自动检测。@param input_template str 输入数据格式的模板,例如 'x1,x2,x3'。@param output_template str 输出数据格式的模板,例如 'x2_prefix+x1_suffix'。@param output_file str 输出文件的路径。如果未指定,将根据输入文件路径生成。@出参:@返回状态:@return 0 失败或异常@return 1 成功@返回错误码@返回错误信息@return Union[List[str], str] 如果输入是字符串或列表,返回转换后的数据格式字符串列表;如果输入是文件路径,返回输出文件的路径。@作 者: PandaCode辉@weixin公众号: PandaCode辉@创建时间: 2024-12-19@使用范例: convert_data_format("name|age|city\nJohn|25|New York",None,"x1,x2,x3","x2_后缀+x1_后缀")'''# If output_file is not specified, generate it based on input_fileif output_file is None and isinstance(input_text, str) and os.path.isfile(input_text):input_file_dir, input_file_name = os.path.split(input_text)input_file_base, _ = os.path.splitext(input_file_name)output_file = os.path.join(input_file_dir, f"{input_file_base}_converted.txt")# Check if input_text is a file path and has .txt extensionif isinstance(input_text, str) and os.path.isfile(input_text):if input_text.lower().endswith('.txt'):with open(input_text, 'r') as file:input_text = file.readlines()input_text = [line.replace('\n', '') for line in input_text]elif input_text.lower().endswith('.csv'):df = pd.read_csv(input_text)# 将DataFrame转换为列表data_list = df.values.tolist()input_text = [','.join(map(str, line)) for line in data_list]elif input_text.lower().endswith('.xls'):# 使用pandas的read_excel函数,并指定openpyxl作为引擎df = pd.read_excel(input_text, engine='xlrd')# 将DataFrame转换为列表data_list = df.values.tolist()input_text = [' '.join(map(str, line)) for line in data_list]elif input_text.lower().endswith('.xlsx'):df = pd.read_excel(input_text, engine='openpyxl')# 将DataFrame转换为列表data_list = df.values.tolist()input_text = [' '.join(map(str, line)) for line in data_list]else:raise ValueError("不支持的文件格式,只限[txt,csv,xls,xlsx]文件.")# If input_text is a string, convert it to a list of stringsif isinstance(input_text, str):input_text = input_text.strip().split('\n')# Detect delimiter if not provided# 检测分隔符if not delimiter:delimiter = detect_delimiter(input_text[0])# 如果还没分隔符,报错提示if not delimiter:raise ValueError('没有检测到默认分隔符,也没有提供自定义分隔符,无法处理')print('delimiter:"' + delimiter + '"')# Split the first line to get the order of fieldsfields_order = input_text[0].strip().split(delimiter)# Create a dictionary to map template names to actual field valuestemplate_dict = {f'x{i + 1}': value for i, value in enumerate(fields_order)}# Function to replace template placeholders with actual valuesdef replace_template(template: str, data: List[str]) -> str:for key, value in template_dict.items():template = template.replace(key, value)return template# Convert each line based on the output templateconverted_lines = []for line in input_text:fields = line.strip().split(delimiter)for i, field in enumerate(fields):template_dict[f'x{i + 1}'] = fieldconverted_line = replace_template(output_template, fields)converted_lines.append(converted_line)# 如果输入是文件路径,将结果写入文件;如果输入是字符串或列表,直接返回结果列表if output_file:with open(output_file, 'w') as file:for line in converted_lines:file.write(line + '\n') # Add a newline character after each linereturn output_fileelse:return converted_lines
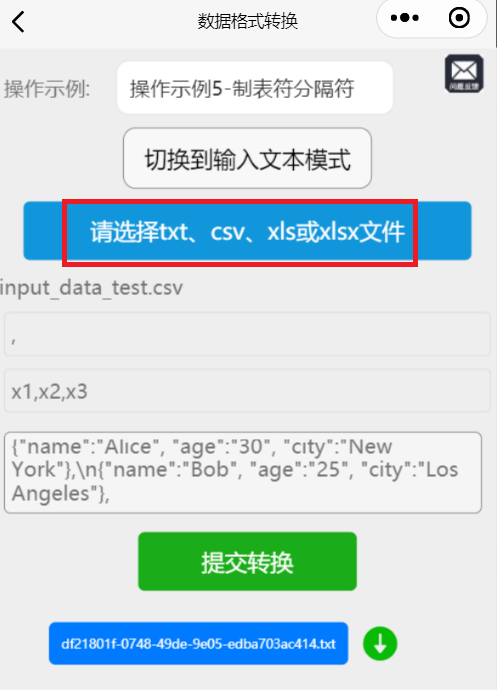
4,前端界面和测试效果。


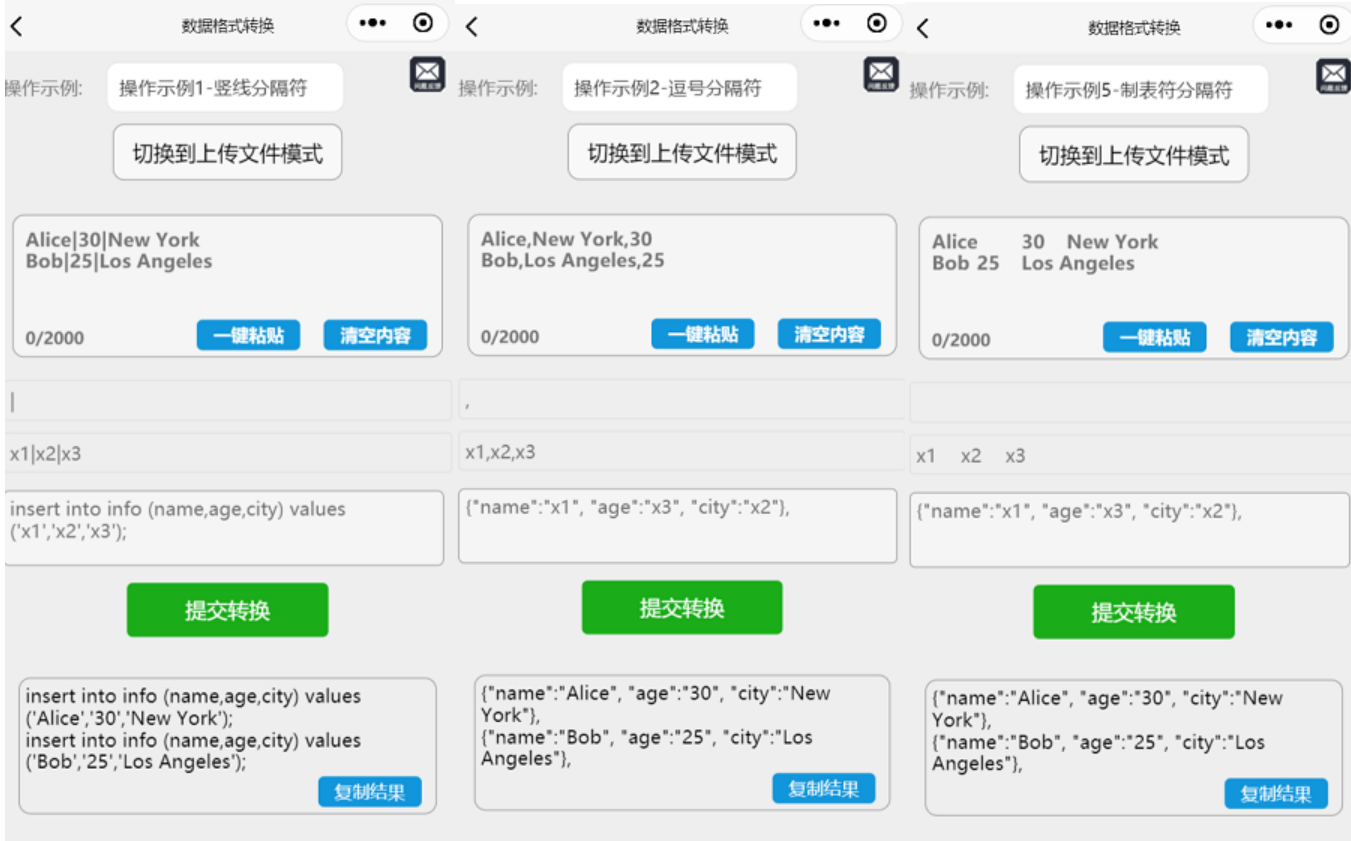
同时支持4种文件格式批量处理模式
四、结尾
快来试试这个小工具吧,用技术手段提升办公效率,拒绝重复枯燥的费时费力工作!
记得点赞+收藏哦,下次遇到数据转换难题,就能迅速找到这篇救星文章啦!
#Python办公技巧 #数据转换神器 #提升工作效率






![[日记]轻量回测框架 Backtesting.py 与 Streamlit集成](https://img2024.cnblogs.com/blog/18503/202501/18503-20250126142924758-1991124526.png)