目录
树模型与集成学习
LightGBM 的贡献
LightGBM 的贡献:单边梯度抽样算法
LightGBM 的贡献:直方图算法
LightGBM 的贡献:互斥特征捆绑算法
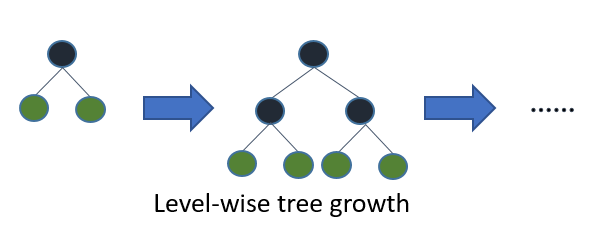
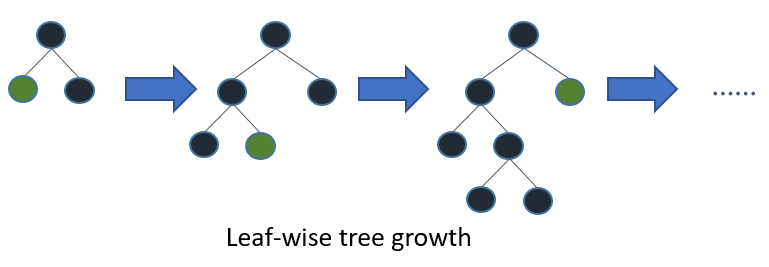
LightGBM 的贡献:深度限制的 Leaf-wise 算法
树模型与集成学习
树模型是非常好的基学习器(弱学习器)。
如何结合多颗树完成模型构建呢?
Random Forest: Bagging + Decision Tree
GBDT: Gradient Boost + Decision Tree
将树模型和集成学习进行结合的想法是可行的。
比如,如果我们将 Bagging 和 Decision Tree 思路进行结合,在进行训练的时候,我们训练多棵树,每棵树使用具体的不同的数据,那么这样就是随机森林的思路。如果我们将 Gradient Boost 和 Decision Tree 思路进行结合,那么就是 GBDT 的思路。
随机森林是基于 Bagging 的思路,对数据集进行有放回的采样,构建不同的数据集,然后从数据集里面训练得到不同的模型,最终完成投票,或者是加权求和。
在竞赛的过程中,我们一般情况下是不会去使用随机森林,我们现在会直接使用比较高阶的一些树模型,比如 XGBoost,LightGBM 或 CatBoost。
LightGBM 的贡献
LightGBM 的特点或贡献主要有如下几点。

单边梯度抽样算法;
直方图算法;
互斥特征捆绑算法;
深度限制的 Leaf-wise 算法;
类别特征最优分割;
特征并行和数据并行;
缓存优化。
LightGBM 的贡献:单边梯度抽样算法
对样本进行采样,选择部分梯度小的样本;
让模型关注梯度高的样本,减少计算量。
首先来看单边梯度抽样算法,我们在进行训练的过程中,可能会计算具体的逻辑 function,然后可以得到具体的梯度信息。我们在进行选择的过程中,会剔除梯度比较小的样本,也就是说,我们会让模型关注梯度比较高的一些样本,这样可以减少模型的计算量,加速训练。
如图是来自于原始论文中的 LightGBM 的伪代码,它的具体的特征是由梯度比较强的一部分样本和梯度比较弱的一部分样本这两部分组成的。

LightGBM 的贡献:直方图算法
将连续特征离散化,用直方图统计信息;
对内存、速度都友好。
第二个是直方图算法,它是 LightGBM 提出伊始的一种非常惊艳的算法。在使用树模型的时候,我们的类别特征需不需要做 onehot 呢?其实在 LightGBM 被提出来之前,一般情况还是建议做 onehot 的,也就是说,在使用 XGBoost 的时候,是建议做 onehot 然后再做训练的。但是现在 LightGBM 的原始论文中使用了直方图的算法来将连续特征做离散化。在 2017 年第一版本的 LightGBM 提出的时候,它的直方图的算法已经比 XGBoost 快很多了。
LightGBM 直方图算法的连续特征离散化特征,是将具体的连续特征用直方图去做一个相当于分箱的过程。分箱是把具体的连续分布划分成不同的单元格,然后从单元格的角度去进行节点的划分。如图是它的具体的伪代码。

它的伪代码对于每个特征去构建一个直方图,然后再去从直方图里面找到最优的分裂节点。
LightGBM 的贡献:互斥特征捆绑算法
使用互斥捆绑算法将特征绑定,降低复杂度;
将特征绑定视为图着色问题,计算特征之间的冲突值;
将特征增加增加偏移量,然后一起相加分桶。
LightGBM 也支持互斥捆绑的过程。我们在进行迭代的过程中,其实是可以将特征进行绑定,以此来降低模型的复杂度的。但是在绑定的过程中,其实是有一个搜索过程的,LightGBM 把搜索过程视为图着色问题,然后去计算特征之间的冲突值。LightGBM 将两个特征的直方图进行相加,组成为一个新的直方图,然后在新的直方图中找到分裂节点,它的核心的仍然是基于直方图的操作。

LightGBM 的贡献:深度限制的 Leaf-wise 算法
每次分裂增益最大的叶子节点,直到达到停止条件;
限制树模型深度,每次都需要计算增益最大的节点;
LightGBM 还有一个贡献就在于它是基于 Leaf-wise 的节点分裂。我们在进行节点分裂的过程中,会设置树模型的最大深度,这是我们在一些机器学习模型里面需要设置的超参数。LightGBM 在分裂的过程中,不是逐层进行具体的划分的,它是在进行节点分裂的过程中,选择分裂增益最大的叶子节点,然后再进行分裂,而且它限制了具体的树模型的深度,这样能够避免模型的过拟合。