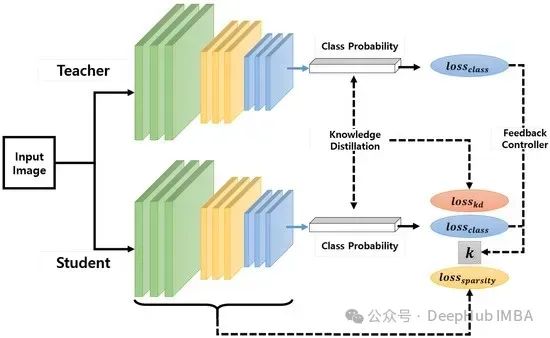
原文:A critique of ANSI SQL isolation levels
摘要:ANSI SQL-92[MS, ANSI]使用脏读、不可重复读以及幻读现象(phenomena)定义了隔离级,本论文展示了这些现象,以及ANSI SQL定义并无法合适的描述众多流行的隔离级别,包括(ANSI标准)所涵盖的级别的标准锁实现。我们还介绍了现象描述的模糊性,并且提供了更加正式的描述,另外,我们还介绍了能够更好描述隔离级别的新现象。最终,我们定义了一个被称作快照隔离的重要的多版本隔离类型。
1. 介绍
在不同的隔离级别上运行并发事务使得应用设计者可以在并发、吞吐量以及正确性之间进行权衡,更低的隔离级别提升了事务的并行性,但也会使事务处于可能观察到模糊或不正确的数据库状态的风险之中。出乎意料地,一些事务可以在最高的隔离级别(完美串行化)上执行,同时,并发执行的事务运行在一个更低的隔离级别上,且能够访问到尚未提交的或者是在其之前读取之后的数据库状态[GLPT]。当然,运行在更低隔离级别的事务会产出无效数据,应用设计者必须对稍后运行在更高隔离级别的事务提供保护,以避免它们访问到这些失效数据,并且传播这些错误。
ANSI/ISO SQL-92规范[MS, ANSI]定义了四种隔离级别:(1) 读未提交,(2) 读已提交,(3) 可重复读,(4) 可串行化。这些级别根据经典串行化定义以及三个被称作现象的不允许的操作序列而被定义:脏读、不可重复读以及幻读,而现象的概念在ANSI规范中并未被明确定义,只是表明现象是可能引发异常(anomalous,或许是非串行化)行为的操作序列。我们在下文中向ANSI现象中添加新的现象时,会引用到异常。如下文说明,异常和现象之间有技术区别,但这区别对于一般理解来说并不重要。
译者:现象和异常是ANSI SQL标准用来描述隔离级别的两个术语,即使它们在ANSI标准中定义并不明确。后文会经常引用这俩术语。
ANSI隔离级别与锁调度器的行为密切相关,一些锁调度器允许事务改变它们的锁请求的范围和持续时间,从而和纯两阶段锁背离。这个点子最初在[GLPT]中出现,它以三种方式定义一致性的度:锁、数据流图以及异常。使用现象(异常)定义隔离级别的意图是允许不基于锁的SQL标准的实现。
这篇论文展示了使用异常方式来定义隔离级别的一系列弱点,ANSI的三种现象是模糊的,甚至在它们最宽松的解释下都无法排除执行历史里可能出现的一些异常行为,这会导致一些反直接的结果。特别是,基于锁来实现的隔离级别与ANSI中等价的隔离级别具有不同特征,并且商业数据库通常使用锁实现,这让事情变得更加尴尬。另外,ANSI中的现象无法区分众多在商业系统中流行的隔离级别类型,在本篇论文中我们提出了能够描述这些隔离级别的额外现象。
第2章介绍了隔离级别的基本术语,它定义了ANSI SQL以及锁的隔离级别,第3章介绍了ANSI隔离级别的一些缺陷并且提出了新的现象,定义了其它流行的隔离级别。在ANSI SQL的隔离级别以及一致性度之间有多种定义映射,这在1977年的[GLPT]中被定义。它们还包含Chris Date对游标稳定性和可重复读[DAT]的定义,在通用框架下讨论隔离级别能够减少独立术语所带来的误解。
第4章介绍了多版本控制机制,被称作快照隔离,其避免了ANSI SQL幻象,但其并非可串行化的。快照隔离本身很有趣,因为它提供一个处于读已提交和可重复读之间的更低隔离级别(reduced isolation level)方式。一个新的formalism(在此参考文献的长版本中[OOBBGM])将多版本数据的这种reduced isolation levels和经典的单版本锁的串行化理论连接起来。
第5章探索了一些新的异常情况来区分在第3章和第4章中引入的隔离级别,本文提出的扩展ANSI SQL现象缺乏描述快照隔离和游标稳定性的能力。第6章是总结和结论。
2. 隔离定义
2.1. 串行化概念
事务和锁的概念在文献[BHG、PAP、PON和GR]中已经写的很全面了,下面的几段回顾了在本篇论文中用到的术语。
一个事务就是将数据库从一个一致状态转移到另一个一致状态的一组操作集合。一个历史将一系列事务的交错执行建模为它们操作的线性顺序,这些操作包括对特定的数据项的读和写(例如插入更新和删除)。在历史中的两个操作,如果它们是被不同的事务在相同数据项上执行的,并且其中至少一个是写入,就说这两个操作是冲突的。根据[EGLT],“数据项”的定义有着很宽松的解释:它可以是一个表行、页面空间、一整个表或者如队列消息这样的通信对象。与单个数据项一样,冲突操作也可能在一系列数据项上,通过一个谓词锁发生。
一个特定的历史能够产生一个依赖图,其定义了事务间的时间数据流。历史中已提交事务的操作被表示为一个图节点,如果在历史中事务T1的操作op1和事务T2之前的操作op2是冲突的,那么,<op1, op2>将构成依赖图中的一条边。如果两个历史具有相同的已提交事务以及相同的依赖图,就认为它们是等价的。一个历史若与串行历史等价,则说它是可串行化的——也就是说它与某种一次性执行一个事务的执行序列的历史具有相同的依赖图。
2.2. ANSI SQL隔离级别
ANSI SQL隔离的设计者寻求一个可以允许许多不同实现的定义,而不仅仅是锁实现,它们使用三种现象来定义隔离:
P1(脏读):事务T1修改了一个数据项,在T1执行提交或回滚之前,另一个事务T2随后读取这个数据项。如果T1随后执行了一个回滚,T2读到了一个永不会被提交的数据项,因此,它读到的是一个永远不会存在的数据项。
P2(不可重复读或模糊读):事务T1读取了一个数据项,另一个事务T2随后修改或删除这个数据项,并提交,如果T1随后尝试重新读取这个数据项,它将接收到一个被修改过的值,或发现这个数据项已经被删除了。
P3(幻读):事务T1读取满足某个<搜索条件>的数据项集,事务T2创建满足T1的<搜索条件>的数据项并提交,若T1随后使用相同的<搜索条件>它的读取,它将获取到和它第一次读取不同的数据集。
译者注:这里的P1、P2、P3作者直接引用了ANSI SQL 98文档中对其的定义,我把其翻译成了中文
所有这几个现象都不会在一个串行历史中发生,因此在串行化定理中,它们不可以在可串行化历史中出现[EGLT,BHG定理3.6,GR第7.5.8.2节,PON定理9.4.2]。
包含读、写提交和回滚的历史可以使用如下简短标记被书写:“w1[x]”代表事务1对数据项x的写,而“r2[x]”代表事务2对x的读。事务1读或写满足谓词P的记录集,可以分别表示为“r1[P]”和“w1[P]”。事务1的提交和回滚分别被写作“c1”和“a1”。
现象P1可以被重写成下面情景:
- (2.1) w1[x] ... r2[x] ... (a1和c2以任意顺序发生)
P1的英文语句定义是模糊的,它实际上并没有坚持要求T1回滚;它只是简单的表达如果这发生了,一些不好的事情可能会发生。一些人们也会将P1解释为这样:
- (2.2) w1[x] ... r2[x] ... ((c1或a1) 以及 (c2或a2)以任意顺序发生)
禁止P1的变体(2.2)即不允许任何T1修改了数据项x,随后T2在T1提交或回滚之前读取数据项的历史,它并不坚持T1回滚或T2提交。
P1的(2.2)定义相比(2.1)要宽松很多,因为它禁止了所有四种T1和T2提交——回滚的可能配对,而(2.1)只禁止了其中的两个。若将(2.2)作为P1的解释,只要一些异常有可能在未来发生,就会禁止这个执行序列。我们将(2.2)称作P1的宽松解释,(2.1)称作P1的严格解释。(2.1)解释定义了一个可能引发异常的现象,而(2.1)定义的是会实际发生异常的,我们分别记作P1和A1:
- P1: w1[x] ... r2[x] ... ((c1或a1) 以及 (c2或a2)以任意顺序发生)
- A1: w1[x] ... r2[x] ... (a1和c2以任意顺序发生)
类似地,英语的现象P2和P3也有严格和宽松的解释,我们将宽松解释记作P2和P3,将严格解释记作A2和A3:
- P2: r1[x] ... w2[x] ((c1/a1) 以及 (c2/a2)以任意顺序发生)
- A2: r1[x] ... w2[x] ... c2 ... r1[x] ... c1
- P3: r1[P] ... w2[y in P] ((c1/a1) 以及 (c2/a2)以任意顺序发生)
- A3: r1[P] ... w2[y in P] ... c2 ... r1[P] ... c1
第3章分析了建立更多概念化机制后的替代方案,并认为现象的这种宽松解释是必要的。注意,ANSI SQL P3的英语表达仅仅只禁止了向谓词中的插入,但是上面(我们定义的符号版)的P3则有意的禁止了在读取谓词后,影响满足谓词的元组的任何写(插入更新删除)。
本篇论文稍后会处理多值历史(MV-history —— 查看[BHG]第5章),现在我们不做详细说明。多版本系统中,一个数据在同一时间可能存在多个版本,任何读取必须显式的指明需要读取哪个版本。已经存在将ANSI隔离定义与多版本系统关联起来的尝试,就像(基于)标准锁调度器的更常见的单版本系统(SV-history)一样。即使如此,现象P1、P2、P3的英语描述也暗示了单版本历史,这是我们在下一章解释它们的方式。
ANSI SQL通过表格1中的矩阵定义了四个隔离级别,每一个隔离级别通过事务不允许出现的现象(宽松或严格解释)来描述,然而,ANSI SQL规范并未使用这些现象来定义可串行化隔离级别,[ANSI]的子条款4.28——“SQL事务”中提到可串行化隔离级别必须提供“通常被称为完全串行的执行”。与这一额外的条款相比,表格的突出导致了一种常见的误解,即不允许这三种现象出现就暗示着可串行化,而在表1中,不允许这三种现象出现的历史被称为异常可串行化(ANOMALY SERIALIZABLE)。

因为相比于严格解释,对现象的宽松解释会在更大的历史集合中发生,且隔离级别由不允许出现的现象来定义,所以事实上我们在第三章对宽松解释的论证意味着我们正在论证更具限制性的隔离级别(更多的历史将被禁止)。但是第三章展示了即使采取P1、P2、P3的宽松解释,禁止这些现象也不能够保证真正的可串行化,在[ANSI]中,扔掉P3,只使用子条款4.28来定义ANSI可串行化将会更简单。注意,表1并不是最终结果,它将会被表3取代。
2.3. 锁定
大多数SQL产品使用基于锁的隔离,由此,使用锁的术语来描述ANSI SQL隔离级别将更有用,尽管会有些具体的问题出现。
在锁调度器下执行的事务请求在它们要读或写的数据项或数据项集合上的Read(共享)和Write(排他)锁。两个在同一个数据项上的,不同事务的锁是冲突的,如果其中至少一个是写锁。
通过给定<搜索条件>确定的一组数据项上的读谓词锁(写也相同),实际上就是对所有满足<搜索条件>的数据项的锁定。这有可能是一个无限集,因为它包含了已经在数据库中的数据以及所有幻影数据项——即目前尚未在数据库中的,但是一旦被插入或更改后将会满足谓词的那些数据项。在SQL术语中,谓词锁包含所有满足为此的数据项以及任何会导致满足谓词的INSERT、UPDATE和DELETE语句。不同事务的两个谓词锁是冲突的,如果至少一个是写锁并且至少有一个(有可能是幻影的)数据项被两个锁都覆盖。一个项目锁(记录锁)可以堪称是一个谓词锁,它的谓词满足指定记录。
事务具有完好写(well-formed write),如果它在写入数据项或被某一谓词定义的数据项集之前,在每个数据项或谓词上获取了写锁(对于读也一样)。事务是完好的,如果它具有完好读和完好写。事务具有两阶段写(two-phase locking),如果它在释放一个写锁之后不再设置新的写锁(对于读也一样)。事务满足两阶段锁定,如果它在释放某些锁后不再请求任何新的锁。
被事务请求的锁是长时间(long duration)的,如果它们持有它直到事务提交或回滚,否则,称为短时间(short duration)的。在实践中,短时间锁通常在操作完成后立即释放。
如果事务持有锁,另一个事务请求一个冲突的锁,新的锁请求将不被授予,直到前一个事务的冲突锁被释放。
基本的可串行化定理是——完好的两阶段锁能够保证可串行化。在两阶段锁下发生的的每一个历史都等价于某个串行化历史,相反,如果一个事务不是完好的或两阶段的,除非在退化场景下,是有可能发生非可串行化执行历史的。
[GLPT]论文定义了四种一致性度,试图说明锁定、依赖和基于异常的特征描述之间的等价性。异常定义(查看定义1)非常模糊,作者持续的在定义方面受到批评(产看[GR]),只有更加数学化的对于历史和依赖图或锁定的定义才能够经受住时间的考验。
表2使用锁范围(scope)、模式(mode)以及他们的时长(duration)定义了一系列隔离级别,我们认为被称作锁读未提交、锁读已提交、锁可重复读和锁可串行化的隔离级别就是ANSI SQL隔离级别所预期的锁定定义——但是如下所示,它们和表1有很大不同,所以,将基于锁的隔离级别和ANSI SQL中基于现象的隔离级别区分开是很有必要的,为了进行这个区分,表2中使用了“Locking”前缀,对应表1中的“ANSI”前缀。
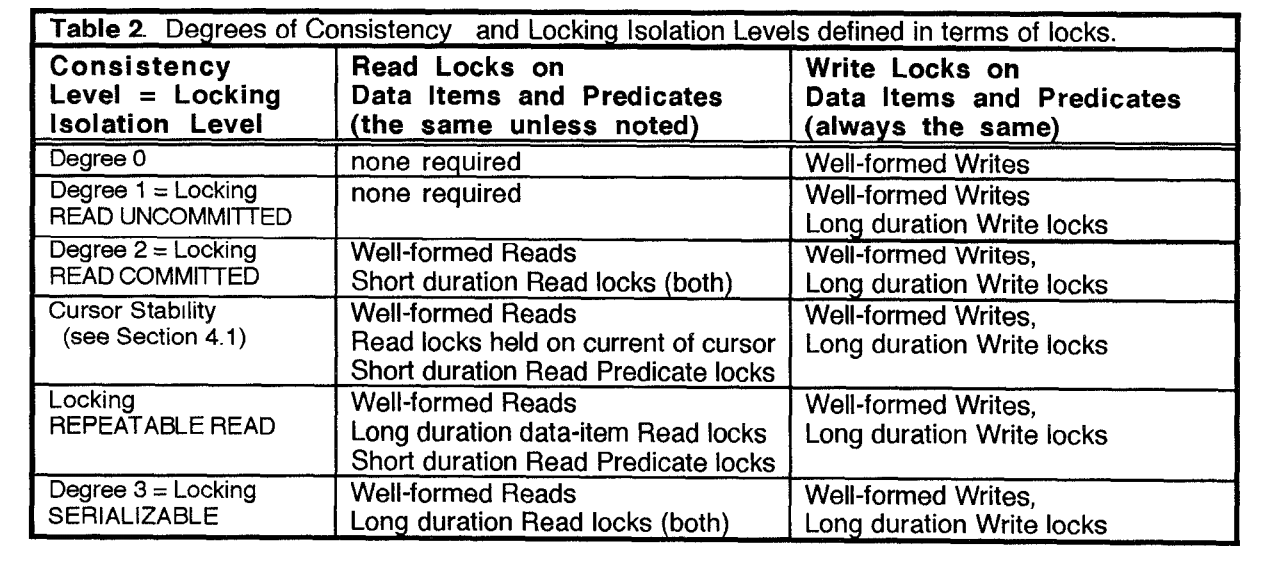
[GLPT]定义度0一致性,同时允许脏读和写:它只需要操作的原子性。度1、2和3分别对应锁度未提交、读已提交和可串行化,没有任何隔离度和锁定可重复读隔离级别对应。
Date和IBM最初使用“可重复读”[DAT,DB2]代表可串行化或锁定可串行化,这看起来是一个比[GLPT]术语“度3隔离”更加广泛的名称,即使它们是一回事。ANSI SQL中可重复读的含义和Date的原始定义不同,我们觉得这个术语是很不幸的,因为异常P3并未被ANSI SQL的可重复读隔离级别排除,因此从P3的定义中可以清楚地看出,读取是不可重复的。在表格2中,我们使用锁可重复读来重复了这个术语滥用,这是为了与ANSI定义平行。类似的,Date创造了“游标稳定性”这一术语,这是比“度2隔离”更加广泛的名称,并且增强了对丢失光标更新的保护,如下面的4.1章所属。
定义:如果所有遵循L2的非可串行化历史也满足L1,并且至少有一个可以在L1发生的非可串行化历史不能在L2发生,就说隔离级别L1比L2更弱(或者说L2比L1更强),记作 L1 << L2。当满足L1和L2的非可串行化历史集合是相同的时,就说两个隔离级别L1和L2是等价的,记作L1 == L2。如果L1 << L2或L1==L2,那么就说L1不比L2更强,记作L1 <<= L2。当两个隔离级别,每一个隔离级别都有一个允许的非可串行化历史,且该历史不被另一个隔离级别允许,就说两个隔离级别是无法比较的,记作 L1 >><< L2。
译者:这个更弱的定义没看懂,更强的级别应该排除更多的非可串行化历史,这里的前半句看起来像反过来了。原文如下:
if all non-serializable histories that obey the criteria of L2 also satisfy L1 and there is at least one non-serializable history that can occur at level L1 but not at level L2
在比较隔离级别时,我们只通过非可串行化历史是否可以在一个中发生,但不可以在另一个中发生来区分它们,两个隔离级别也可以在它们允许的可串行化历史方面有所不同,但是我们说锁可串行化==可串行化,尽管大家都知道锁调度器并不能允许所有可能的串行化历史。一个隔离级别有可能是不可实践的,由于它不允许太多的可串行化历史,但是我们这里不处理这种情况。
译者:这里作者想表达的就是,若两个隔离级别能排除相同的非可串行化历史集,就认为等价,尽管此时一个可能排除了更多的可串行化历史(思考真正串行执行实现1的隔离以及基于锁的冲突可串行化隔离,前者排除了很多可串行化历史,只严格保留串行执行的那些历史)

在下面的部分中,我们将聚焦在ANSI以及锁定义的比较上。
3. 分析ANSI SQL隔离级别
首先,锁定隔离级别符合ANSI SQL要求。
Remark 2:表2中的锁定协议定义了锁隔离级别,它们至少与表一中基于现象的对应隔离级别一样强,可以查看[OOBBGM]中的证明。
因此,锁定隔离级别至少具有ANSI中相同名称级别的隔离度,它们更强吗?答案是使得,即使在最低级别,锁读未提交提供长时间的写锁以避免我们称作“脏写”的现象,但是ANSI SQL在它的基于异常的定义中,在ANSI可串行化之下,并不会排除这一异常行为。
P0(Dirty Write):事务T1修改了一个数据项,另一个事务T2在T1提交或回滚前进一步修改这个数据项,如果T1或T2稍后执行一个回滚,此时正确的数据是什么是不清楚的。宽松解释为:
- P0:w1[x] ... w2[x] ... ((c1 or a1)和(c2 or a2)以任何顺序发生)
脏写是不好的一个原因是,它们可能违反数据库的一致性。假设在x和y之间有一个约束(比如,x=y),T1和T2在独自执行时都在维护这个约束的一致性,然而,如果两个事务以不同的顺序写x和y,在发生脏写的情况下,这个约束将被轻松的违反。比如,如果历史是:w1[x] w2[x] w2[y] c2 w1[y] c1,那么T1对y的修改以及T2对x的修改存活了下来,如果T1对x和y写入1,T2写入2,则结果是x=2,y=1,这违反了x=y。
正如[GLPT,BHG]以及其它地方讨论的,原子事务回滚是P0如此重要的一个迫切原因,如果没有P0保护,系统不能通过恢复之前的镜像来撤回更新。考虑这个历史:w1[x] w2[x] a1,你不希望通过恢复它x上的镜像来撤回w1[x],因为这会摧毁w2的更新,但是如果你不恢复它之前的镜像,并且事务2稍后也回滚了,你也不能通过恢复它的镜像撤回w2[x]!这也是为什么即使是最弱的所系统也持有长时间的写锁,否则,它们的恢复系统将失败。