最近DeepSeek开源了对openai-o1的第一代开源推理大模型:deepseek-r1,因其极低的成本和与openai-o1相当的性能引发了国内外的激烈讨论。DD在做独立产品的时候也一直都有用DeepSeek的API来实现一些功能,比如:TransDuck中的字幕翻译、视频翻译,效果也是非常不错的。但是,最近因为收到一些私有化的需求,所以对于API的调用就不可行了,不得不转向本地部署大模型,然后提供API的方式来实现。本文就针对这样的情况,尝试了一下使用 Ollama 在本地运行 DeepSeek-R1 并提供 API 服务,然用再使用Spring Boot + Spring AI 实现对 DeepSeek-R1 的调用,有类似需求或者感兴趣的小伙伴也可以根据下面的内容来实践。
使用 Ollama 运行 deepseek-r1
通过 Ollama 来运行 deepseek-r1 非常简单,在Linux服务器上的话,只需要两步:
- 安装 Ollama
curl -fsSL https://ollama.com/install.sh | sh
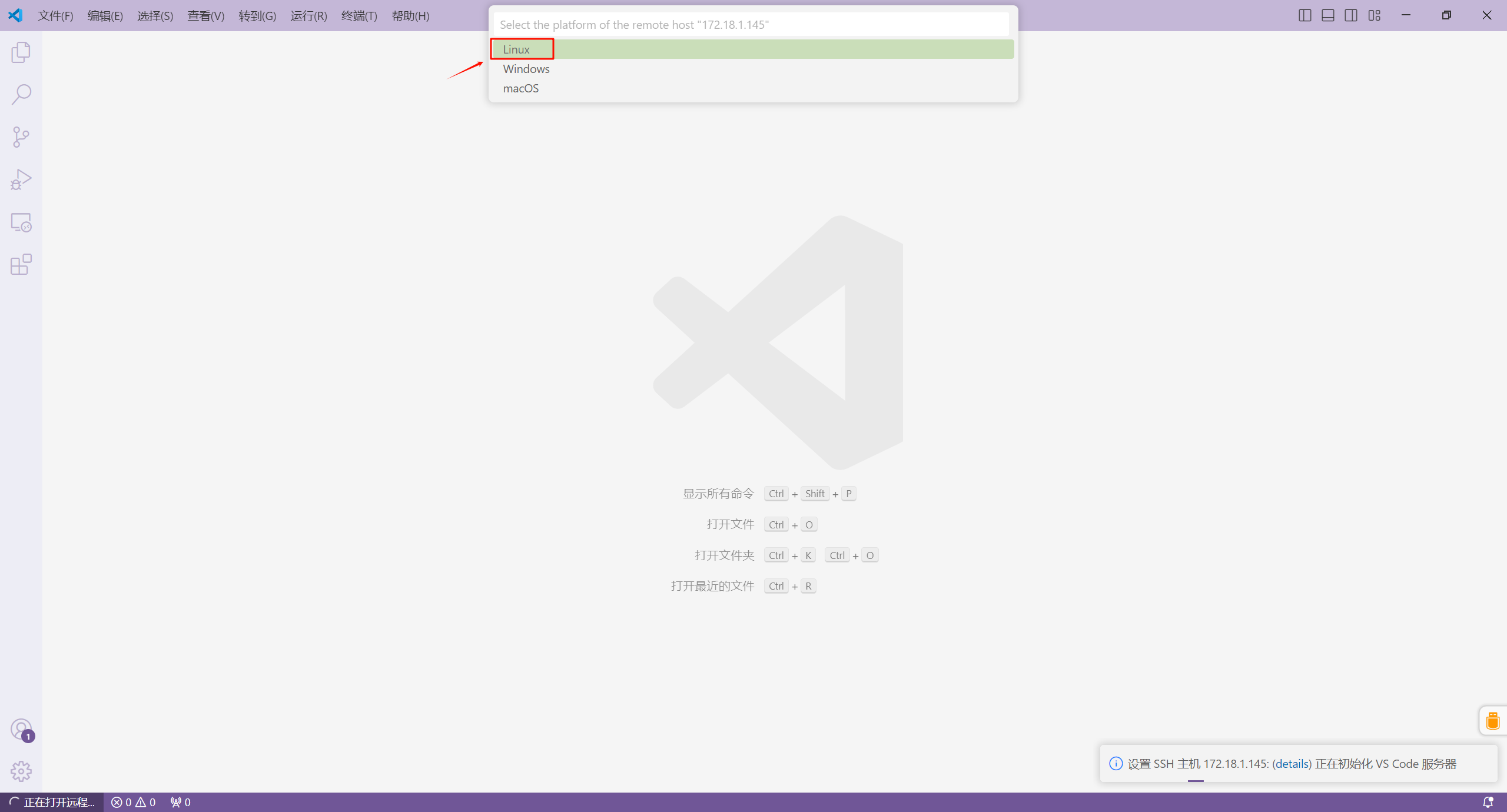
如果本地MacOS或者Windows开发环境使用的话,也可以从前往官网下载客户端版本:

- 运行 deepseek-r1
ollama run deepseek-r1:671b
如果你的环境没有足够的资源运行671b模型,那么也可以根据你的算力资源情况选择其他几个小参数版本,命令如下:
ollama run deepseek-r1:1.5b
ollama run deepseek-r1:7b
ollama run deepseek-r1:8b
ollama run deepseek-r1:14b
ollama run deepseek-r1:32b
ollama run deepseek-r1:70b
更多关于信息可查看:https://ollama.com/library/deepseek-r1
使用Spring Boot + Spring AI
在使用Ollama把deepseek-r1跑起来之后,我们就可以开始使用Spring Boot + Spring AI来调用了。
- 使用
https://start.spring.io/构建一个Spring Boot项目。点击ADD DEPENDENCIES,搜索Ollama添加依赖,这是Spring AI对Ollama的实现支持。

- 打开生成的项目,查看
pom.xml,可以看到核心依赖:
<dependency><groupId>org.springframework.ai</groupId><artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>
如果你要在现有项目中集成的话,就可以直接添加这个依赖即可。
- 配置Ollama的相关信息:
spring.ai.ollama.base-url=http://localhost:11434
spring.ai.ollama.chat.model=deepseek-r1:1.5b
spring.ai.ollama.base-url: Ollama的API服务地址,如果部署在非本机,就需要做对应的修改spring.ai.ollama.chat.model: 要调用的模型名称,对应上一节ollama run命令运行的模型名称
- 写个单元测试,尝试调用Ollama中的deepseek-r1模型,这里尝试实现一个翻译的功能。
@SpringBootTest(classes = DemoApplication.class)
public class TestOllama {@Autowiredprivate OllamaChatModel ollamaChatModel;@Testpublic void testChatModel() {String prompt = """你是一个精通中文和英文的翻译大师。如果我给你英文就翻译成中文,给你中文就翻译成英文。""";String message = """Ollama now supports tool calling with popular models such as Llama 3.1.This enables a model to answer a given prompt using tool(s) it knows about,making it possible for models to perform more complex tasks or interact with the outside world.""";String result = ollamaChatModel.call(prompt + ":" + message);System.out.println(result);}}
- 运行单元测试,结果如下:
<think>
好,我现在需要把用户提供的英文内容翻译成中文。首先,我仔细阅读原文:“Ollama now supports tool calling with popular models such as Llama 3.1.” 这句话的意思是说 Olla 现在支持模型使用常用模型如 Llama 3.1 进行工具调用。接下来的部分说明了这样做的好处:它允许模型通过工具来回答问题,从而实现更复杂的任务或与外界交互。现在我开始逐句翻译。第一句:“Ollama now supports tool calling with popular models such as Llama 3.1.” 直接翻译就是“ Olla 现在支持常用模型如 Llama 3.1 进行工具调用。”这里要注意“now”要保留,保持时态不变。第二句:“This enables a model to answer a given prompt using tool(s) it knows about, making it possible for models to perform more complex tasks or interact with the outside world.” 我理解为这句话的意思是说这个功能让模型可以使用它知道的工具来回答给定的提示,从而让模型完成更复杂的任务或与外界交互。翻译时要准确传达出技术上的优势和应用扩展。第三句:“Making it possible for models to perform more complex tasks or interact with the outside world.” 可以简单翻译为“使模型能够执行更复杂的任务或与外界交互。”这里要注意保持原意的同时,用较为流畅的中文表达。在翻译过程中,我还需要注意语境和语气的一致性。比如,将“popular models”翻译成“常用模型”,是否需要调整?在这里,“常用模型”本身已经是特定的词汇,直接使用就可以了。另外,句号和逗号的正确使用也很重要,确保句子结构清晰,读起来顺畅。比如,在第一句中用一个句号结束,第二句和第三句也分开处理,保持逻辑关系。现在,把翻译后的中文整合成一段话:“Ollama 现在支持常用模型如 Llama 3.1 进行工具调用。” 这个部分已经很清晰了。接下来的翻译要准确传达工具调用带来的好处,所以我可能会这样写:“这使其成为可能,让模型能够通过它知道的工具来回答给定的问题,并允许模型执行更复杂的任务或与外界交互。”最后,整个句子应该连贯起来,确保逻辑连贯,没有遗漏任何信息。完成翻译后,再通读一遍,看看有没有不通顺或者不准确的地方。总结一下,翻译的重点是保持原文的技术意义和意图,同时用自然流畅的中文表达出来。
</think>Ollama 现在支持常用模型如 Llama 3.1 进行工具调用。这使其成为可能,让模型能够通过它知道的工具来回答给定的问题,并允许模型执行更复杂的任务或与外界交互。
可以看到结果响应分成两部分,先是<think>标签包含的内容,这是模型根据提供的提示,生成了一个思考的过程,最后才输出了翻译后的结果。
欢迎关注我的公众号:程序猿DD。第一时间了解前沿行业消息、分享深度技术干货、获取优质学习资源