引入
一个数列,单点修改(加),区间查询(和)。
上述问题有很多种解法,如树状数组、分块、平衡树等,今天的主题是著名的线段树。
正题
(不确保按难度升序排序,自己看着目录调顺序吧)
线段树基本原理
因为需要区间查询,所以我们希望有一些捷径能将部分的数的和提前算好,并能够直接上手用,这样可以节省不少的时间。
这正是线段树、树状数组、分块的主要思想。
考虑将整个序列平均分成两截,将 两部分的数提前算好,修改的时候顺手再改一下,就能省掉一部分时间。
但是这还是不够优秀。
接下来又有两条路可以走:
- 将序列拆分成的段数增加,用同样的方法维护(这就是分块的方向)。
- 将分成的两截继续分,分到每段只有一个数为止(这就是线段树和树状数组的思想),形成一个类似树的结构。
第一条的最优时间复杂度是 \(\sqrt{n}\) 级别的,但是第二条理论上是可以做到 \(\log n\) 级别的,所以我们试着走第二条路。
走第二条路得到的结构是一棵树,我们可以不用链式建树,用堆式建树即可(即父亲节点编号为 \(i\),则两个儿子的编号为 \(2i\) 和 \(2i + 1\))。
根据上文中提到的方法,我们需要将这个树形的数据结构(线段树)上的所有点都给予一个权值 \(sum\),代表该结点管辖的所有结点之和。
因为每个结点上的 \(sum\) 都需要从各自儿子结点上传过来,所以需要有一个权值上传的函数。
void pushup(int id) {sum[id] = sum[ls] + sum[rs]; // ls,rs 代表两个儿子的编号,下同
}
每一次查询 \(\left[L, R\right]\),找到所有被完全包含的加一下即可(但是一定要全取深度最浅的,这样不仅不会算重还能节省部分的时间)。
示例代码:
int query(int id, int lft, int rht, int l, int r) { // 从左到右依次是:目前找到的结点编号、结点管辖的左端点、右端点、查询的左端点、右端点if (lft > r || rht < l) return 0; // 如果不在结点的辖区内,返回 0 不考虑。if (l <= lft && rht <= r) return sum[id]; // 如果完全包含,不用往下递归,直接返回。int mid = (lft + rht) >> 1; // 因为分是对半分,所以取中点return query(ls, lft, mid, l, r) + query(rs, mid + 1, rht, l, r); // 递归返回
}
但是它若修改 \(x\),阁下又该如何应对?
其实这也不难,从根(代表 \(\left[ 1, n \right]\) 的点)开始,往下找代表 \(\left[ x, x\right]\) 的点,并将沿途的所有点都加上修改的值即可。
示例代码:
void change(int id, int lft, int rht, int x, int v) { // 从左到右依次是:目前找到的结点编号、结点管辖的左端点、右端点、修改的下标、修改的权值if (x < lft || rht < x) return; // 如果不包含在区间中,就返回if (lft == rht) return sum[id] += v, void(); // 如果恰好找到了,就修改回去int mid = (lft + rht) >> 1;change(ls, lft, mid, x, v), change(rs, mid + 1, rht, x, v); // 递归修改pushup(id); // 记得上传
}
大家可以参考图 \(1\) 配合理解上述内容。
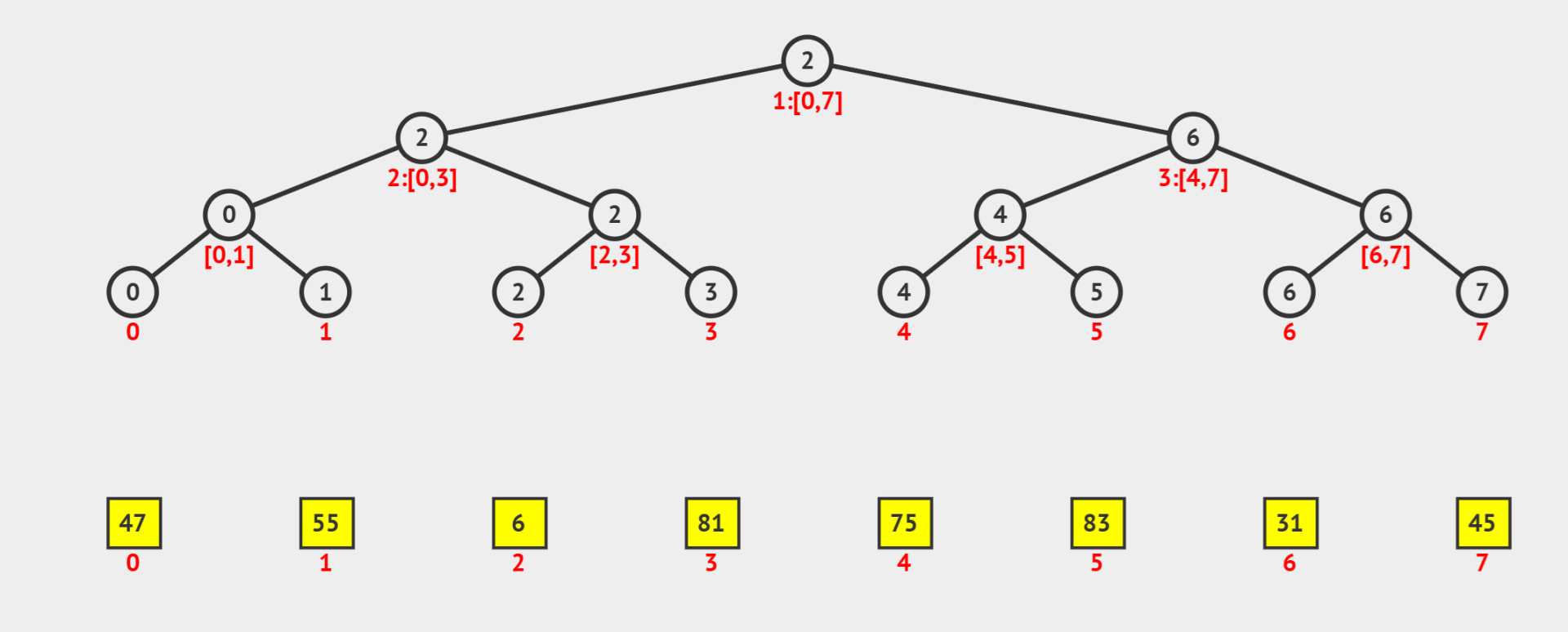
(图 \(1\),来自 visualgo.net)
时空复杂度放到后面分析。
懒标记基本原理
那如果单修换成区修呢?
显然不可能一个一个地改,那该怎么办?
先放下线段树,我们举一个形象的例子。
你是一名学生,你的老师给你们班委派了一份作业。
并且老师嘱咐她会突击检查。
你想着等老师检查再做,就开始玩florr。
突然有一天,老师要突击检查,但是没检查到你,你放心了,还是不需要做。
但是这天,老师要检查你,你只好把所有的陈年旧账翻出来做了,交给老师。
老师没检查出问题,以为你是一个按时做作业的好学生。
故事讲完了,但是线段树还没完。
我们可以将区修类比成老师布置作业,检查看作查询。
而树上的每个点都看作你不做作业的学生。
那么对于每一个树上的结点,我们再加一个变量 \(tag\),存储所有的在当前结点上做的区修值之和(因为多次区间加可以看作一次大的区间修改),先存在那,不慌下传,等查询到的时候再下传。
因为这是人类懒才制造出来的东西,所以叫“懒标记”。
示例代码:
void pushdown(int id) { // 将存储于结点 id 的懒标记下传if (tag[id]) { // 如果该结点上存有标记tag[ls] += tag[id], tag[rs] += tag[id]; // 将标记传递到两个子结点的标记sum[ls] += tag[id] * len[ls]; // 传递到两个儿子结点的 sum 信息中,但是修改是对区间中每个数的修改,所以要乘上区间长度sum[rs] += tag[id] * len[rs];tag[id] = 0; // 已经下传完,不用留着}
}
int query(int id, int lft, int rht, int l, int r) {if (lft > r || rht < l) return 0; if (l <= lft && rht <= r) return sum[id];pushdown(id); // 记得 pushdown,否则还没来得及做就被检查了int mid = (lft + rht) >> 1;return query(ls, lft, mid, l, r) + query(rs, mid + 1, rht, l, r);
}
void change(int id, int lft, int rht, int l, int r, int v) { if (lft > r || rht < l) return;if (lft == rht) return sum[id] += (rht - lft + 1) * v, tag[id] += v, void(); // 修改,记得加标记pushdown(id); // 记得 pushdownint mid = (lft + rht) >> 1;change(ls, lft, mid, l, r, v), change(rs, mid + 1, rht, l, r, v);pushup(id);
}
复杂度分析
-
时间复杂度
-
在查询中,发现每一层都至多有两个线段被选中,一共有 \(\log n\) 层,那么时间复杂度为 \(\mathcal O(\log_N)\)。
-
在单修中,只需要找到修改对应的结点的位置即可,时间复杂度 \(\mathcal O(\log n)\)。
-
在区修中,与查询大致相同,时间复杂度也为 \(\mathcal O (\log n)\)。
则总时间复杂度为 \(O(Q \log n)\)。
-
-
空间复杂度
因为我们是用堆式建树来构建二叉树的,那么整棵数一共有 \(2N + 1\) 个结点。
但是为了避免越界,我们需要开 \(2 \times (2N + 1) + 1 = 4N + 3\) 个结点。
故线段树的空间复杂度为 \(\mathcal O(4N)\),记得别开小 RE 了。
扫描线 + 线段树
看一道题:
P5490 【模板】扫描线 & 矩形面积并
假设有一条直线,初始与 \(x\) 轴平行,不断往上扫,然后在线段树上更新。
像这样:

(图 \(2\),图片来自 oi-wiki)
最后将扫过的长度乘上宽即可算出一条长方形的面积了。
代码不放了,当时写得很丑。
广义扫描线
上文解决了矩阵面积并问题,是具象的扫描线(当然也是狭义的)。
但是有一些序列问题也可以转化为扫描线。
核心思想便是枚举一维,然后考虑用某种数据结构维护另外一维。
P1908 逆序对
没错就是它,虽然并没有用线段树(也不是不行),但是它的树状数组解法运用了扫描线思想。
对于每一个数 \(p_i\),将 \((i, p_i)\) 放到坐标轴上。
像这样:
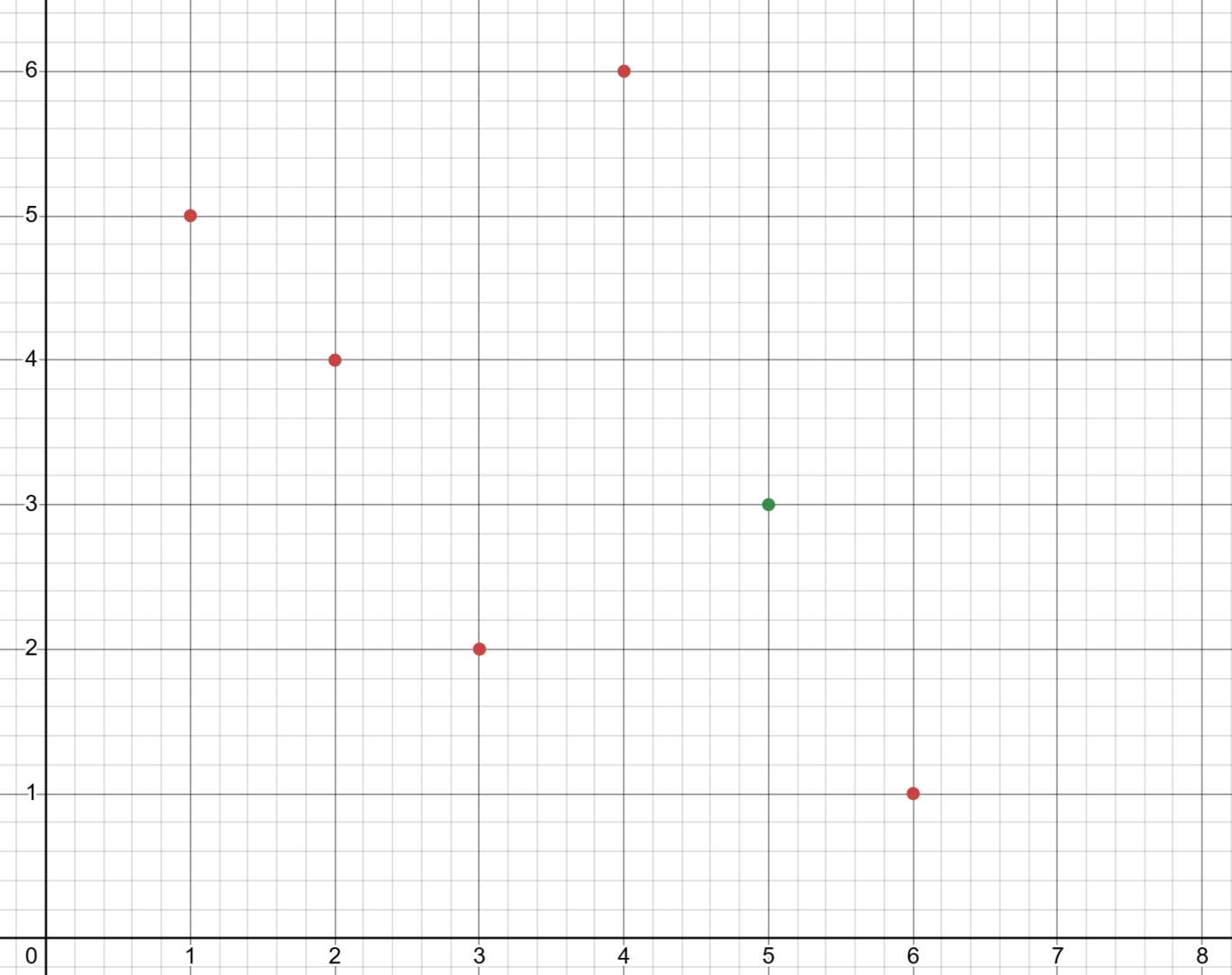
(图 \(3\),自己的,以样例为例)
而逆序对的定义是 \(i > j, p_i < p_j\),那么就相当于找所有在 \((i, p_i)\) 的左上方的点,像这样:
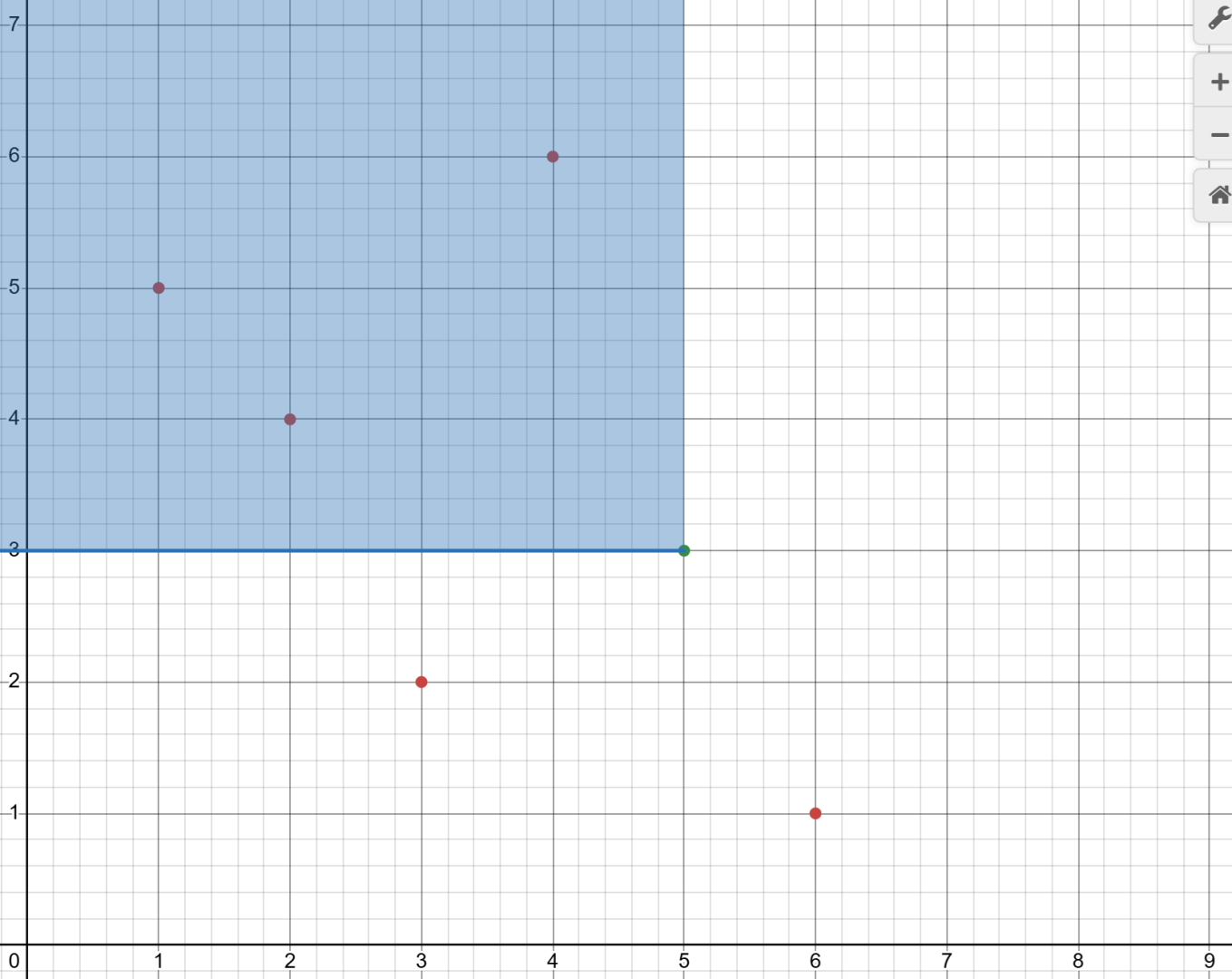
(图 \(4\))
好,你已经知道广义扫描线是什么了,我们来小试牛刀一下。
Pudding Monsters
区区紫题,何足惧哉?
因为每行每列只会有一个 Monster,所以可以将二维压缩成一维,横坐标作为下标,纵坐标作为值记为 \(a\) 数组。
不要被紫题的表象吓到,冷静分析,它求的无非是满足以下条件的 \((L, R)\) 对数:
可以来推柿子了:
仔细分析,发现:
那不好办了,直接算算上述值的最小值个数不就行了。
但是复杂度好像还是 \(n^2\log n\) 的,肯定过不了……
不过,你可别忘了,这题要用扫描线。
枚举 \(R\),利用单调队列更新 \(\max\)、\(\min\),修改以后,查询最小值个数之和即可。
小小紫题,不过如此。
#include <bits/stdc++.h>
#define int long long
#define pii pair<int, int>
#define FRE(x) freopen(x ".in", "r", stdin), freopen(x ".out", "w", stdout)
#define ALL(x) x.begin(), x.end()
using namespace std;int _test_ = 1;const int N = 3e5 + 5;int n, a[N], b[N];struct node {int v, l, r; // 存储左右端点和权值
};bool operator<(node a, node b) { return a.v < b.v; }
bool operator>(node a, node b) { return a.v > b.v; }
bool operator<(node a, int b) { return a.v < b; }
bool operator>(node a, int b) { return a.v > b; }
bool operator<(int a, node b) { return a < b.v; }
bool operator>(int a, node b) { return a > b.v; }struct segment {#define ls (id << 1)#define rs (id << 1 | 1)int mn[N << 2], cnt[N << 2], tag[N << 2]; // 最小值、最小值个数、加和懒标记void pushup(int id) {mn[id] = min(mn[ls], mn[rs]);if (mn[ls] < mn[rs]) cnt[id] = cnt[ls];if (mn[ls] > mn[rs]) cnt[id] = cnt[rs];if (mn[ls] == mn[rs]) cnt[id] = cnt[ls] + cnt[rs]; }void pushdown(int id) {if (tag[id]) {mn[ls] += tag[id], mn[rs] += tag[id];tag[ls] += tag[id], tag[rs] += tag[id];tag[id] = 0;}}void build(int id, int lft, int rht) {if (lft == rht) return mn[id] = b[lft], cnt[id] = 1, void();int mid = (lft + rht) >> 1;build(ls, lft, mid), build(rs, mid + 1, rht);pushup(id);}void change(int id, int lft, int rht, int l, int r, int v) {if (lft > r || rht < l) return;if (l <= lft && rht <= r) {mn[id] += v;tag[id] += v;return;}pushdown(id);int mid = (lft + rht) >> 1;change(ls, lft, mid, l, r, v), change(rs, mid + 1, rht, l, r, v);pushup(id);}pii query(int id, int lft, int rht, int l, int r) {if (lft > r || rht < l) return {LL\mathcal ONG_MAX, 0};if (l <= lft && rht <= r) return {mn[id], cnt[id]};int mid = (lft + rht) >> 1;pii x = query(ls, lft, mid, l, r), y = query(rs, mid + 1, rht, l, r);if (x.first < y.first) return x;if (x.first > y.first) return y;return {x.first, x.second + y.second};}
} seg;void init() {}void clear() {}void solve() {cin >> n;for (int i = 1, l; i <= n; i++) cin >> l >> a[l];for (int i = 1; i <= n; i++) b[i] = i; // 这里用了一个比较巧妙的方法,放后面说一下seg.build(1, 1, n);stack<node> mx, mn; // 两个单调栈int ans = 0;for (int i = 1; i <= n; i++) {int lft = i;while (mx.size() && a[i] > mx.top()) {lft = mx.top().l;seg.change(1, 1, n, mx.top().l, mx.top().r, -mx.top().v); // 将所有不再是最大值的合并到一起mx.pop();}seg.change(1, 1, n, lft, i, a[i]); // 同意赋值,上文中 max 部分是正的所以是 + a[i]mx.push({a[i], lft, i});lft = i;while (mn.size() && a[i] < mn.top()) {lft = mn.top().l;seg.change(1, 1, n, mn.top().l, mn.top().r, mn.top().v); // 将所有不再是最小值的合并到一起mn.pop();}seg.change(1, 1, n, lft, i, -a[i]); // 同理,为 - a[i]mn.push({a[i], lft, i});ans += seg.cnt[1]; // 加上所有的总和}cout << ans;
}signed main() {ios::sync_with_stdio(0);cin.tie(0), cout.tie(0);
// cin >> _test_;init();while (_test_--) {clear();solve();}return 0;
}
代码中的 for (int i = 1; i <= n; i++) b[i] = i; 不知道你注意到没有。
因为柿子中的 \(-len\) 不断在变,比较麻烦,将它统一加上 \(R + 1\),此时 \(-len\) 就变成了 \(L\),恰好就是 \(i\),问题就迎刃而解了。
线段树维护最大子段和及相关问题
引入
link。
我们可以分析出上题就是带修改的最大子段和。
遇到这种类型的题目应该想到用线段树。
实现
对于原数列,先建起一棵线段树,每个节点包含 最大前缀、最大后缀、最大字段和、区间和 信息。
当你明确一道题是线段树时,要先思考
pushup和pushdown怎么写,因为剩下的都是差不多的。 —— jzp.
因为本题是单查,没有 pushdown,就先考虑 pushup 怎么写:
- 最大前缀只可能是左儿子的最大前缀或是左儿子的和加上右儿子的最大前缀,即 \(maxl_i = \max\{maxl_l, sum_l + maxl_r\}\)。
- 最大后缀同理,\(maxr_i = \max\{maxr_r, sum_r, maxr_l\}\)。
- 最大子段和就是左儿子最大子段和或右儿子最大子段和或左儿子最大后缀加右儿子最大前缀,即 \(maxs_i = \max\{maxs_l, maxs_r, maxr_l + maxl_r\}\)。
- 区间和很简单,不赘述。
void pushup(int id) {sum(id) = sum(ls) + sum(rs);maxl(id) = max(maxl(ls), sum(ls) + maxl(rs));maxr(id) = max(maxr(rs), sum(rs) + maxr(ls));maxs(id) = max(max(maxs(ls), maxs(rs)), maxr(ls) + maxl(rs));
}
那么对于每一次询问,我们找到线段树上的左右端点 \(l\)、\(r\) 对应的两点 \(p_l\)、\(p_r\)。
当我们从上往下爬树爬到 \(k = LCA(p_l, p_r)\) 时,\(l\) 和 \(r\) 就会分开为两个区间。
此时答案有几种可能:
- \(l \le r \le m\),其中 \(m\) 为该区间的中间点,此时递归左侧得到答案。
- \(m \lt l \le r\),此时递归右侧得到答案。
- \(l \le m \lt r\),此时合并两次得到的答案。
以上三者取最大值返回。
这跟 cdq 分治的思想有异曲同工之妙。
当 \(l\) 与 \(r\) 并没有分叉时,就直接走下去即可。
那么此时查询也可以顺利地写出来了。
segment query(int id, int lft, int rht, int l, int r) { // 这里用 segment 作为返回值是因为每层递归都需要用到下一层递归的结果if (l <= lft && rht <= r) return seg[id];int mid = (lft + rht) >> 1;if (r <= mid) return query(ls, lft, mid, l, r);if (l > mid) return query(rs, mid + 1, rht, l, r);segment a = query(ls, lft, mid, l, r), b = query(rs, mid + 1, rht, l, r), t;t.sum = a.sum + b.sum;t.maxl = max(a.maxl, a.sum + b.maxl);t.maxr = max(b.maxr, b.sum + a.maxr);t.maxs = max(max(a.maxs, b.maxs), a.maxr + b.maxl);return t;
}
整体代码:
struct segment_tree {#define ls (id << 1)#define rs (id << 1 | 1)#define sum(id) seg[id].sum#define maxl(id) seg[id].maxl#define maxr(id) seg[id].maxr#define maxs(id) seg[id].maxsstruct segment {int maxl, maxr;int sum, maxs;} seg[N << 2];void pushup(int id) {sum(id) = sum(ls) + sum(rs);maxl(id) = max(maxl(ls), sum(ls) + maxl(rs));maxr(id) = max(maxr(rs), sum(rs) + maxr(ls));maxs(id) = max(max(maxs(ls), maxs(rs)), maxr(ls) + maxl(rs));}void build(int id, int lft, int rht) {if (lft == rht) {sum(id) = a[lft];maxl(id) = maxr(id) = maxs(id) = a[lft];return;}int mid = (lft + rht) >> 1;build(ls, lft, mid), build(rs, mid + 1, rht);pushup(id);}void change(int id, int lft, int rht, int x, int v) {
// if (lft > x || rht < x) return;if (lft == rht) {
// a[lft] = v;sum(id) = v;maxl(id) = maxr(id) = maxs(id) = v;return;}int mid = (lft + rht) >> 1;if (x <= mid) change(ls, lft, mid, x, v); else change(rs, mid + 1, rht, x, v);pushup(id);}segment query(int id, int lft, int rht, int l, int r) {
// if (lft > r || rht < l) return ;if (l <= lft && rht <= r) return seg[id];int mid = (lft + rht) >> 1;if (r <= mid) return query(ls, lft, mid, l, r);if (l > mid) return query(rs, mid + 1, rht, l, r);segment a = query(ls, lft, mid, l, r), b = query(rs, mid + 1, rht, l, r), t;t.sum = a.sum + b.sum;t.maxl = max(a.maxl, a.sum + b.maxl);t.maxr = max(b.maxr, b.sum + a.maxr);t.maxs = max(max(a.maxs, b.maxs), a.maxr + b.maxl);return t;}
} seg;
我们可以通过线段树维护最大子段和来推广到其他类似的问题。
(复制了一下之前写的)
永久化标记原理
还是线段树模板 \(1\),我们换一种打标记的方法。
将标记停留在结点上,不下传,查询的时候沿途收集标记,并加上子树内标记即为答案。
就像一个扫帚:
(图 \(5\))
void change(int id, int lft, int rht, int l, int r, int v) {val[id] += (r - l + 1) * v; // 将子树内标记提前打好if (l == lft && rht == r) return tag[id] += v, void(); // 沿途标记更新int mid = (lft + rht) >> 1;if (r <= mid) return change(ls, lft, mid, l, r, v);if (l > mid) return change(rs, mid + 1, rht, l, r, v);return change(ls, lft, mid, l, mid, v), change(rs, mid + 1, rht, mid + 1, r, v); // 继续递归子树
}
int query(int id, int lft, int rht, int l, int r, int cnt) { // cnt 为沿途标记和if (lft == l && rht == r) return val[id] + (rht - lft + 1) * cnt; // 子树内标记和加上沿途标记int mid = (lft + rht) >> 1;cnt += tag[id]; // 收集该结点标记if (r <= mid) return query(ls, lft, mid, l, r, cnt);if (l > mid) return query(rs, mid + 1, rht, l, r, cnt);return query(ls, lft, mid, l, mid, cnt) + query(rs, mid + 1, rht, mid + 1, r, cnt);
}
这个方法会使得常数变小一些,而且适用于一些懒标记无法维护的情况。
当遇到懒标记无法解决修改或解决起来很慢时可以考虑使用永久化标记。
线段树上二分技巧
当你需要对线段树做二分时,正常情况下是 \(\mathcal O(\log^2n)\) 的,某些良心出题人会将其卡掉。
这时候就要用线段树上二分了。
因为线段树本身就是一个二分的结构,所以不如干脆就顺着线段树一直往下找,找到结果就返回。
复杂度就省去了一只 \(\log\)。
动态开点技巧
当你需要建的线段树不是下标线段树而是值域线段树,就需要考虑使用动态开点。
因为值域的范围不仅仅是 \(10^6\),有可能为 \(10^9\) 乃至 \(10^{18}\)。
虽然值域很大,但是我们的操作数不可能太大(需要读入)。
故我们不需要建立所有的点,只建立所有出现过的点即可。
譬如说修改一个 \(5\):
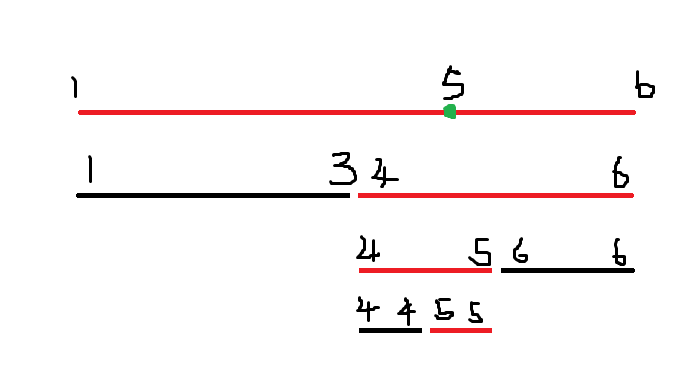
(图 \(6\),其中黑边代表不需要建立的结点,红边代表需要建立)
其他所有不包含 \(5\) 的都没有必要放进线段树中建立出来。
树链剖分
一个非常实用的维护树上路径信息的数据结构。
引入
树链剖分(Tree Line Pow Divide),一种解决树上快速路径修改查询问题的算法,一般指 重链剖分(Heavy Path Decomposition)。
思想图解
一个问题
如题,已知一棵包含 \(N\) 个结点的树(连通且无环),每个节点上包含一个数值,需要支持以下操作:
-
1 x y z,表示将树从 \(x\) 到 \(y\) 结点简单路径上所有节点的值都加上 \(z\)。 -
2 x y,表示求树从 \(x\) 到 \(y\) 结点简单路径上所有节点的值之和。
一些定义
顾名思义,重链剖分就是把”重“的链与其他的链分开,那么如何定义重呢?
我们定义一个 重儿子(Heavy Son)的概念:
以该点的儿子为根的子树中节点个数最多的儿子为重儿子
那么就可以递归定义 重链:
若节点 u 为节点 v 的重儿子,那么 v 就归入到 u 所在的链中
否则,节点 v 就单独成为一条链的链首
那么一棵树可以被剖成这个样子:
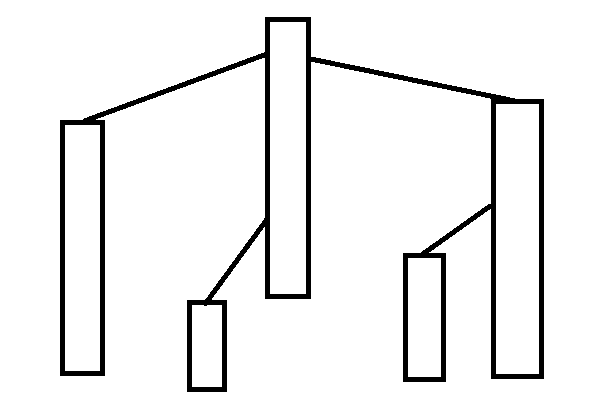
(图 \(7\))
其中一个长方形代表一条链。
接下来即可定义一个 链顶 的概念:
一条链中,深度最低的点
深度,即
根节点到该节点的距离+1
思想概述
看到类似区修区查的语言:
-
所有节点的值都加上 \(z\)。
-
所有节点的值之和。
不难想到用线段树(或树状数组等,下同);
但是难想的就是如何将一棵树剖成一个序列,从而使用线段树呢?
我们可以将树中的的节点重新编号,按照编号顺序建线段树,
其中编号序列满足以下条件(先不说为什么,待会再讲):
所有的重链的编号是连续的
是一种dfs序
这里我不想画图了,读者自己体会。
可以建树了,但是修改查询还不会。
修改
我们先考虑一种简单的情况:
情况A
修改的两个点 A,B 在同一条重链上:
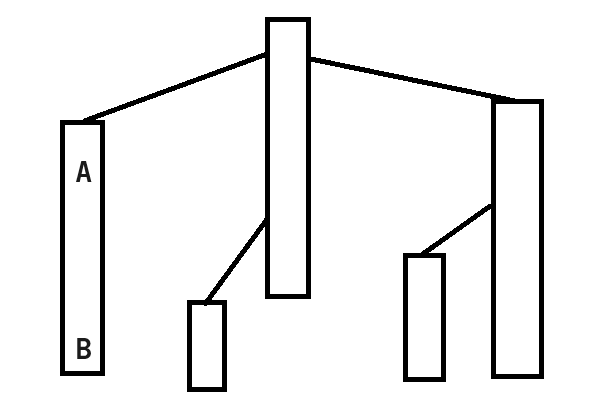
(图 \(8\))
根据我们dfs序的建立,易证 A 到 B 的路径上的节点在线段树上一定是连续的。
那么就可以通过线段树的区间修改操作实现了。
这里就可以填上我刚才挖的那个坑了。
情况B
再引入一下
一个很好理解的定理(废话):
任意一个链顶不为根的链,链顶的父亲一定是另外一条链的一部分
同样,这里我不想画图了,读者自己体会。
接下来要讨论的情况就是不在同一条链上:
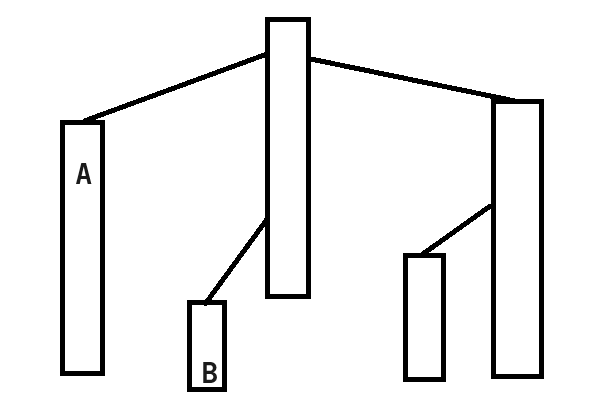
(图 \(9\))
我们可以先把链顶深度较低的 B 所在的这条链的所有点修改了,并跳到其链顶的父亲所在的链的最后一个节点上;
接着同理修改 A;
即每次将链顶深度较低的往上爬,直到 A 与 B 重合。
其实,可以将两者结合一下:
每次将链顶深度较低的往上爬,直到 A 与 B 在同一条链。
施行情况A(因为 A 与 B 在同一条链上并不意味着 A = B)
查询
与修改大同小异,只是把 \(\texttt{Change}\) 换成 \(\texttt{Query}\) 而已,这里不赘述。
代码
模板题 洛谷 P3384 【模板】重链剖分/树链剖分
int a[Maxn], tmp[Maxn];
int p;struct SegmentTree {//线段树
#define ls (id << 1)
#define rs (id << 1 | 1)struct Segment {int Left;int Right;int valMax;int tag;int valSum;} seg[Maxn << 2];il void PushUp(int id) {seg[id].valMax = max(seg[ls].valMax, seg[rs].valMax) % p;seg[id].valSum = (seg[ls].valSum + seg[rs].valSum) % p;return;}il void PushDown(int id) {if (seg[id].tag) {seg[ls].tag += seg[id].tag;seg[ls].tag %= p;seg[ls].valSum += seg[id].tag * (seg[ls].Right - seg[ls].Left + 1);seg[ls].valSum %= p;seg[rs].tag += seg[id].tag;seg[rs].tag %= p;seg[rs].valSum += seg[id].tag * (seg[rs].Right - seg[rs].Left + 1);seg[rs].valSum %= p;seg[id].tag = 0;}return;}il void Build(int id, int Left, int Right) {seg[id] = {Left, Right, 0, 0, 0};if (Left == Right) {seg[id].valMax = a[Left] % p;seg[id].valSum = a[Left] % p;return;}int mid = (Left + Right) >> 1;Build(ls, Left, mid);Build(rs, mid + 1, Right);PushUp(id);return;}il int QuerySum(int id, int Left, int Right) {PushDown(id);if (seg[id].Right < Left || seg[id].Left > Right) {return 0;}if (Left <= seg[id].Left && seg[id].Right <= Right) {return seg[id].valSum % p;}return (QuerySum(ls, Left, Right) + QuerySum(rs, Left, Right)) % p;}il void Change(int id, int Left, int Right, int val) {PushDown(id);if (seg[id].Right < Left || seg[id].Left > Right) {return;}if (seg[id].Left >= Left && Right >= seg[id].Right) {seg[id].tag += val;seg[id].tag %= p;seg[id].valSum += val * (seg[id].Right - seg[id].Left + 1) % p;seg[id].valSum %= p;return;}Change(ls, Left, Right, val);Change(rs, Left, Right, val);PushUp(id);return;}
};//以上内容不做解释vector<int> G[Maxn];//邻接表
int n, m, root;struct Qtree {//重链剖分struct treeNode {int fa;//该节点的父亲int son;//重儿子int dep;//深度int size;//字数节点个数int top;//该点所在链的链顶int tid;//重新编号的序号} tn[Maxn];SegmentTree SEG;int tot = 0;void dfs1(int step, int fa) {//初始化fa、dep、size、sontn[step].fa = fa;tn[step].dep = tn[fa].dep + 1;tn[step].size = 1;int Max = 0;for (auto x : G[step]) {if (x == fa) {continue;}dfs1(x, step);tn[step].size += tn[x].size;if (tn[x].size > Max) {//判重儿子Max = tn[x].size;tn[step].son = x;}}return;}void dfs2(int step, int top) {//初始化top、tidtn[step].top = top;tn[step].tid = ++tot;//有没有像Tarjan的dfn?a[tot] = tmp[step];//重新将点权赋值if (tn[step].son)//避免死循环dfs2(tn[step].son, top);//重儿子for (auto x : G[step]) {if (x == tn[step].fa || x == tn[step].son) {//排除重儿子continue;}dfs2(x, x);//因为x不是重儿子,所以x所在链的链首为自己}}void Build() {//建立dfs1(root, 0);//以root为根dfsdfs2(root, root);SEG.Build(1, 1, n);//以a数组建立线段树return;}void Change(int u, int v, int w) {while (tn[u].top != tn[v].top) {//u,v不在同一条链上if (tn[tn[u].top].dep < tn[tn[v].top].dep) {//简洁写法,即把链顶深度较低的点放到uswap(u, v);}SEG.Change(1, tn[tn[u].top].tid, tn[u].tid, w % p);//修改u = tn[tn[u].top].fa;//往上爬}if (tn[u].tid > tn[v].tid) {//最后执行情况Aswap(u, v);}SEG.Change(1, tn[u].tid, tn[v].tid, w % p);return;}int QuerySum(int u, int v) {//同理int Max = 0;while (tn[u].top != tn[v].top) {if (tn[tn[u].top].dep < tn[tn[v].top].dep) {swap(u, v);}Max += SEG.QuerySum(1, tn[tn[u].top].tid, tn[u].tid);Max %= p;u = tn[tn[u].top].fa;}if (tn[u].tid > tn[v].tid) {swap(u, v);}return Max + SEG.QuerySum(1, tn[u].tid, tn[v].tid);}
} Qt;
最后读者可以自行思考一下如何将边权转成点权,洛谷 P4114 Qtree1。
(很久之前写的,比较丑陋)