字符
使用.表示任意(除了换行符以外)字符
使用[ce]代表c或者e任意一个字符的字符集合
可以使用
-表示范围, 比如[A-Z]
在[]里面可以使用^表示取反, 针对整个[]范围内部的全部取反
- 不在
[]中的^代表限定在开头
常用字符
\d 代表digit, \D 代表非数字部分的内容
\w 代表数字或者字母或者下划线
\s 代表空白字符
位置匹配
^ 代表开头
$ 代表结尾
\b 代表边界border, \B 代表不是边界
量词
? 代表可能出现一次, 也可能不出现
+ 代表出现至少一次
* 代表任意多次
{} 代表精确的出现次数的匹配
{3}代表出现了三次
{3,}代表了出现了至少三次
- 使用
?跟在花括号后面, 代表不要贪婪匹配
分组(整体化)
使用 () 打包处理, 比如 (at){2} 代表atat
捕获分组
通过使用 () 创建的不同分组实现针对具体内容的提取
在编程的时候, 设置自己需要提取的分组可以提升开发的效率
非捕获分组
使用 (?: ) 来定义一个不被捕获的分组, 在需要使用分组但是不想捕获的时候有用
引用分组
使用 \1 来引用第一个可以被捕获的分组
前瞻
使用分组的时候, 使用 (?= ) 表示分组内部的内容不会在最后被匹配到的内容里面
使用
(?! )对条件取反!
后顾
使用 (?<= ) 可以检查后面的内容
TIP
\ 作为转义字符
| 代表或者字符
默认是贪婪匹配
参考
B站geekhour教程




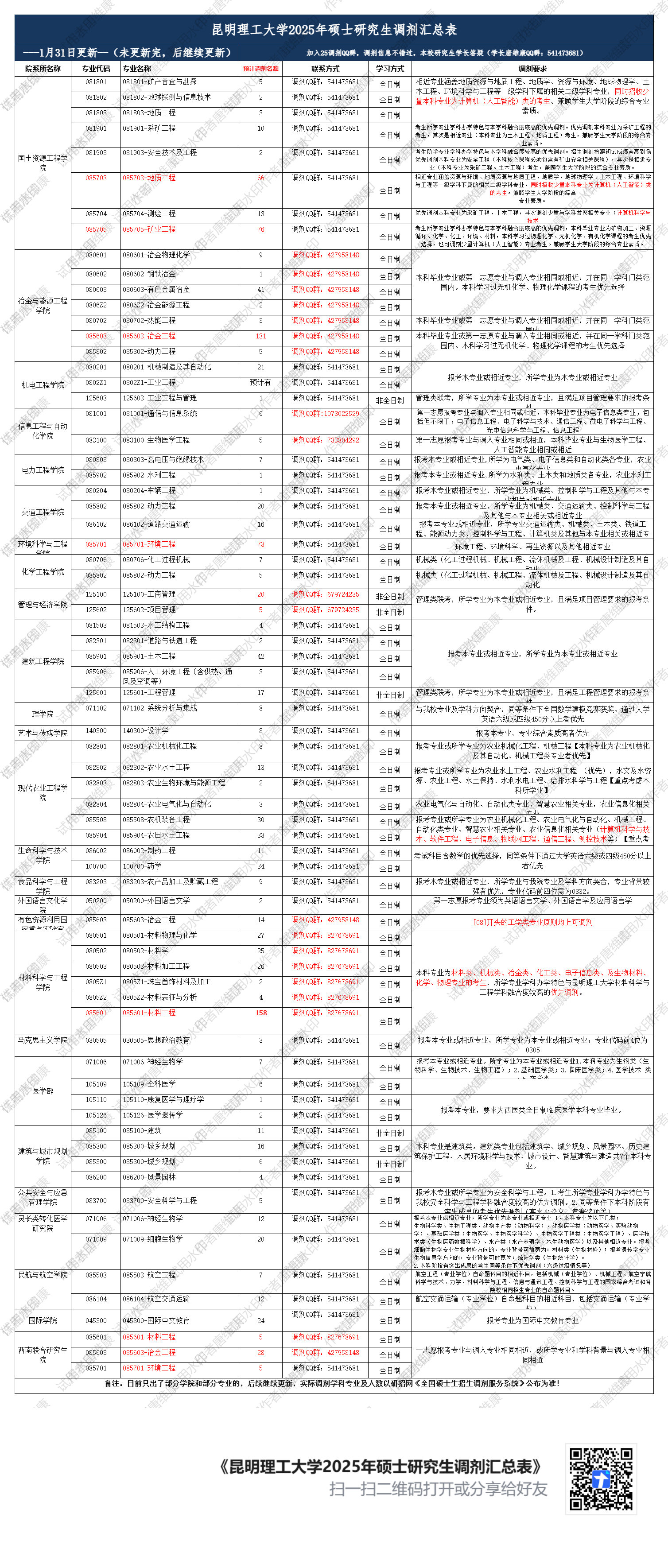
![[Tools] 发布代码](https://resource.duyiedu.com/xiejie/2023-06-07-075420.png)