随机种子固定随机结果,方便复现
def seed_everything(seed):torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed)torch.backends.cudnn.benchmark = Falsetorch.backends.cudnn.deterministic = Truerandom.seed(seed)np.random.seed(seed)os.environ['PYTHONHASHSEED'] = str(seed)
def read_file(self, path):if self.mode == "semi":file_list = os.listdir(path)xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8) #len(file_list)表示图像数量 dtype读成整型 RGB全为整数# 列出文件夹下所有文件名字for j, img_name in enumerate(file_list):img_path = os.path.join(path, img_name) #合并两个路径img = Image.open(img_path)img = img.resize((HW, HW))xi[j, ...] = imgprint("读到了%d个数据" % len(xi))return xielse:for i in tqdm(range(11)):file_dir = path + "/%02d" % ifile_list = os.listdir(file_dir)xi = np.zeros((len(file_list), HW, HW, 3), dtype=np.uint8)#读成整型yi = np.zeros(len(file_list), dtype=np.uint8)# 列出文件夹下所有文件名字for j, img_name in enumerate(file_list): #enumerate读下标和下标工具img_path = os.path.join(file_dir, img_name)img = Image.open(img_path)img = img.resize((HW, HW))xi[j, ...] = imgyi[j] = iif i == 0:X = xiY = yielse:X = np.concatenate((X, xi), axis=0)#将数组 X 和数组 xi 沿着第 0 个轴(通常代表样本数量这个维度)进行拼接Y = np.concatenate((Y, yi), axis=0)print("读到了%d个数据" % len(Y))return X, Y
tqdm显示循环进度条

train_transform = transforms.Compose([transforms.ToPILImage(), #224, 224, 3模型 :3, 224, 224transforms.RandomResizedCrop(224), #随机放大然后裁切transforms.RandomRotation(50), #旋转transforms.ToTensor() #模型用张量运行]
)
class food_Dataset(Dataset):def __init__(self, path, mode="train"):self.mode = modeif mode == "semi":self.X = self.read_file(path)else:self.X, self.Y = self.read_file(path)self.Y = torch.LongTensor(self.Y) #标签转为长整形if mode == "train":#规定train和val不同的transform模式self.transform = train_transformelse:self.transform = val_transformdef __getitem__(self, item):if self.mode == "semi":return self.transform(self.X[item]), self.X[item]# 进行模型检测和加入数据集else:return self.transform(self.X[item]), self.Y[item]def __len__(self):return len(s

lr动态调整
W:权重衰减,让曲线更平滑
模型
class MyModel(nn.Module): #自己的模型def __init__(self,numclass = 2):super(MyModel, self).__init__()self.layer0 = nn.Sequential(nn.Conv2d(in_channels=3,out_channels=64,kernel_size=3,stride=1,padding=1,bias=True),nn.BatchNorm2d(64),nn.ReLU(inplace=True),nn.MaxPool2d(2)) #112*112self.layer1 = nn.Sequential(nn.Conv2d(in_channels=64,out_channels=128,kernel_size=3,stride=1,padding=1,bias=True),nn.BatchNorm2d(128),nn.ReLU(inplace=True),nn.MaxPool2d(2)) #56*56self.layer2 = nn.Sequential(nn.Conv2d(in_channels=128,out_channels=256,kernel_size=3,stride=1,padding=1,bias=True),nn.BatchNorm2d(256),nn.ReLU(inplace=True),nn.MaxPool2d(2)) #28*28self.layer3 = nn.Sequential(nn.Conv2d(in_channels=256,out_channels=512,kernel_size=3,stride=1,padding=1,bias=True),nn.BatchNorm2d(512),nn.ReLU(inplace=True),nn.MaxPool2d(2)) #14*14self.pool1 = nn.MaxPool2d(2)#7*7self.fc = nn.Linear(25088, 512)# self.drop = nn.Dropout(0.5)self.relu1 = nn.ReLU(inplace=True)self.fc2 = nn.Linear(512, numclass)def forward(self,x):x = self.layer0(x)x = self.layer1(x)x = self.layer2(x)x = self.layer3(x)x = self.pool1(x)x = x.view(x.size()[0],-1) #view 类似于reshape 这里指定了第一维度为batch大小,第二维度为适应的,即剩多少, 就是多少维。# 这里就是将特征展平。 展为 B*N ,N为特征维度。4*512*512 ->4*25088x = self.fc(x)# x = self.drop(x)x = self.relu1(x)x = self.fc2(x)return x
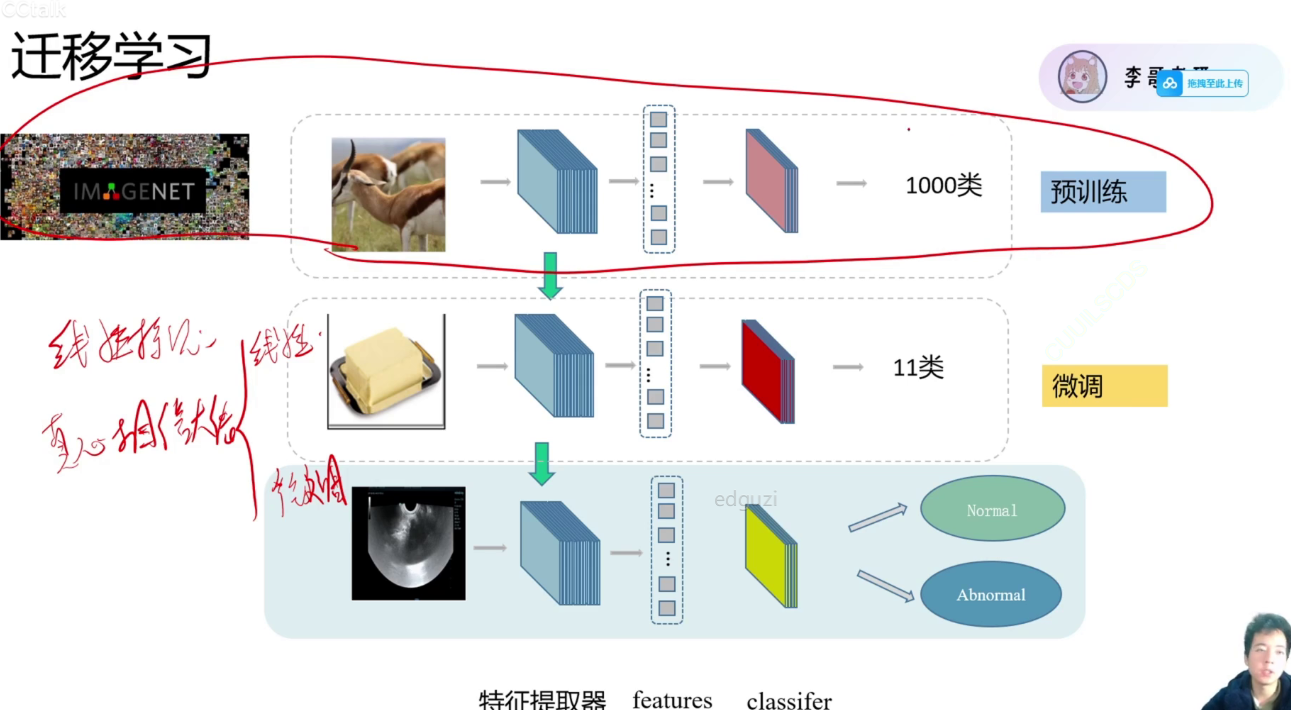
model_name == "resnet18":""" Resnet18"""model_ft = models.resnet18(pretrained=use_pretrained) # 从网络下载模型 pretrain true 使用参数和架构, false 仅使用架构。set_parameter_requires_grad(model_ft, linear_prob) # 是否为线性探测,线性探测: 固定特征提取器不训练。num_ftrs = model_ft.fc.in_features #分类头的输入维度model_ft.fc = nn.Linear(num_ftrs, num_classes) # 删掉原来分类头, 更改最后一层为想要的分类数的分类头。input_size = 224