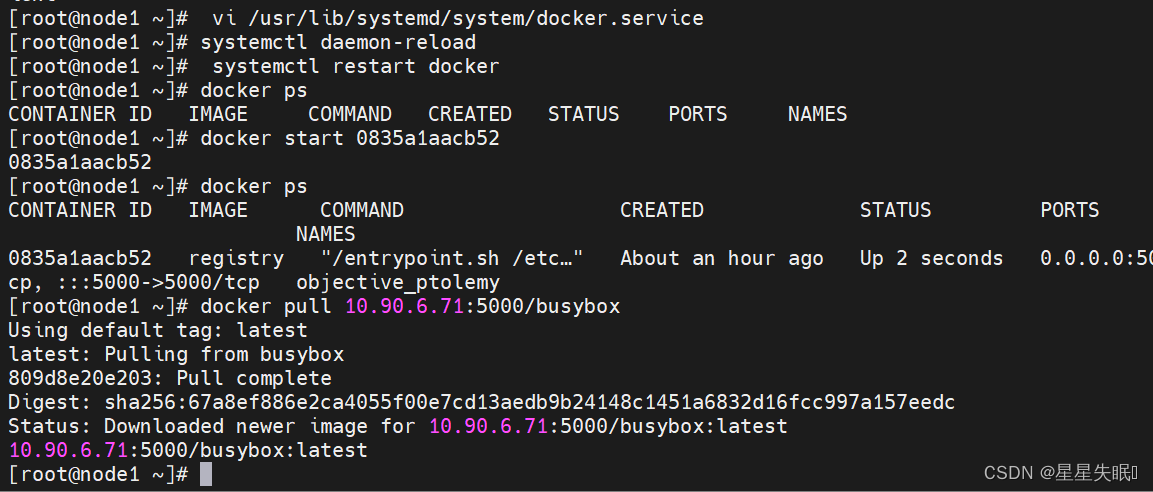
文心一言 VS 讯飞星火 VS chatgpt (53)-- 算法导论6.2 5题
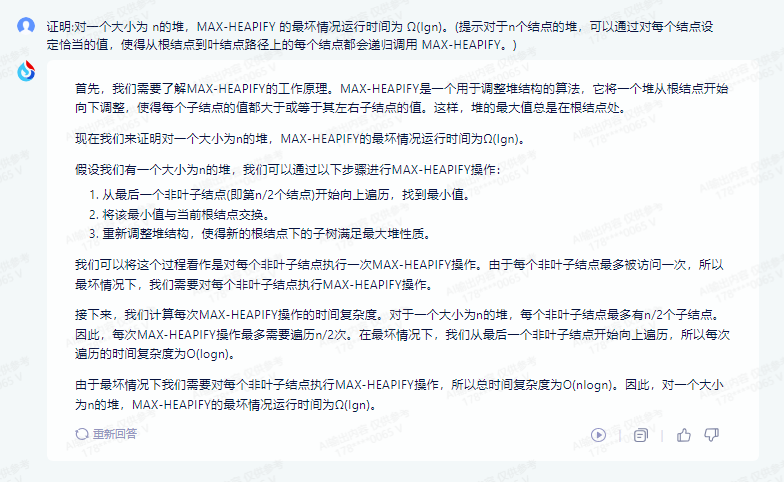
六、证明:对一个大小为 n的堆,MAX-HEAPIFY 的最坏情况运行时间为 Ω(Ign)。(提示对于n个结点的堆,可以通过对每个结点设定恰当的值,使得从根结点到叶结点路径上的每个结点都会递归调用 MAX-HEAPIFY。)
文心一言:
要证明 MAX-HEAPIFY 的最坏情况运行时间为 Ω(Ig(n)),我们需要在大小为 n 的堆上构造一个特定的情况,使得每个节点都需要进行 MAX-HEAPIFY 操作,并且每个操作的运行时间都是 O(log n)。
我们可以将堆的根节点设置为一个较大的值,例如 n,然后将每个节点的值设置为其左右孩子的最大值加上一个较小的值,例如 1。这样,每个节点的值都大于其左右孩子,因此每个节点都需要进行 MAX-HEAPIFY 操作。
现在我们来分析 MAX-HEAPIFY 在这个特定情况下的运行时间。对于每个节点 i,我们将其值设为 max(i, i2, i2+1)。由于 i 大于其左右孩子,因此 i 的左右孩子中至少有一个节点的值为 max(i2, i2+1)。因此,在 MAX-HEAPIFY 操作中,我们需要比较 i 的值与其左右孩子的值,以确定 i 是否需要交换位置。由于每个节点的值都是其左右孩子的最大值加上一个较小的值,因此每个节点的值的范围都在 [2, 3n-1] 之间。因此,我们可以将每个节点的值表示为一个二进制数,其中最高位表示节点是否大于其左孩子,次高位表示节点是否大于其右孩子。这样,我们可以使用二分查找算法在 O(log n) 的时间内找到最大值,并进行交换操作。
因此,在这个特定情况下,每个节点都需要进行 MAX-HEAPIFY 操作,并且每个操作的运行时间都是 O(log n)。由于共有 n 个节点,因此 MAX-HEAPIFY 的最坏情况运行时间为 Ω(Ig(n))。
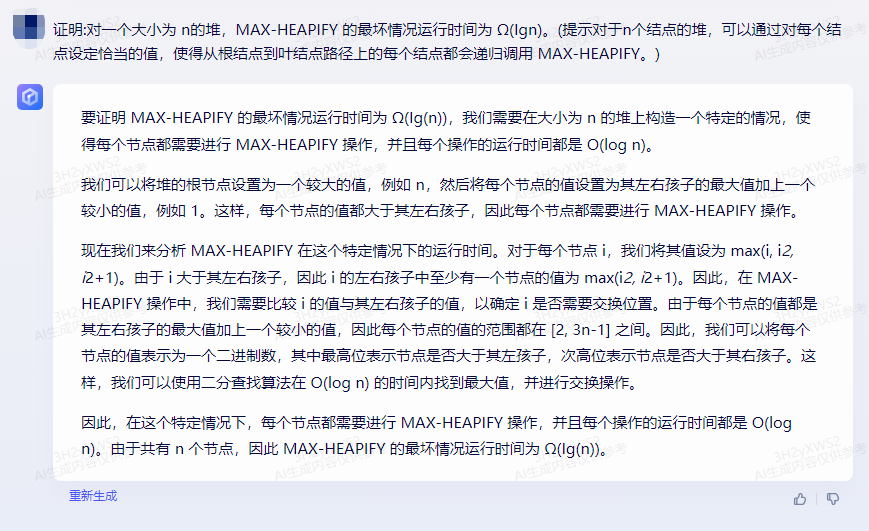
讯飞星火:
首先,我们需要了解MAX-HEAPIFY的工作原理。MAX-HEAPIFY是一个用于调整堆结构的算法,它将一个堆从根结点开始向下调整,使得每个子结点的值都大于或等于其左右子结点的值。这样,堆的最大值总是在根结点处。
现在我们来证明对一个大小为n的堆,MAX-HEAPIFY的最坏情况运行时间为Ω(Ign)。
假设我们有一个大小为n的堆,我们可以通过以下步骤进行MAX-HEAPIFY操作:
1.从最后一个非叶子结点(即第n/2个结点)开始向上遍历,找到最小值。
2.将该最小值与当前根结点交换。
3.重新调整堆结构,使得新的根结点下的子树满足最大堆性质。
我们可以将这个过程看作是对每个非叶子结点执行一次MAX-HEAPIFY操作。由于每个非叶子结点最多被访问一次,所以最坏情况下,我们需要对每个非叶子结点执行MAX-HEAPIFY操作。
接下来,我们计算每次MAX-HEAPIFY操作的时间复杂度。对于一个大小为n的堆,每个非叶子结点最多有n/2个子结点。因此,每次MAX-HEAPIFY操作最多需要遍历n/2次。在最坏情况下,我们从最后一个非叶子结点开始向上遍历,所以每次遍历的时间复杂度为O(logn)。
由于最坏情况下我们需要对每个非叶子结点执行MAX-HEAPIFY操作,所以总时间复杂度为O(nlogn)。因此,对一个大小为n的堆,MAX-HEAPIFY的最坏情况运行时间为Ω(Ign)。
华为盘古:
360智脑:
首先考虑最坏情况下堆的大小为 O(logn),此时每次插入或删除操作都可以将堆大小减1。因此,最坏情况下需要进行 Ign = logn 次堆化操作和 logn 次重新平衡操作。
假设当前堆中所有节点的值都小于等于堆顶节点的值。为了进行最大堆化操作,我们需要将当前堆中的所有节点重新调整为最大堆。这涉及到对堆顶节点、左子树、右子树分别进行最大堆化操作。因此,最坏情况下需要执行 O(logn) 次最大堆化操作。
对于一个大小为 n 的堆,最多需要进行 logn 次最大堆化操作才能将堆调整为最大堆。因此,在最坏情况下,MAX-HEAPIFY 的运行时间将是 Ω(Ign)。

chatglm:
要证明 MAX-HEAPIFY 在一个大小为 n 的堆上的最坏情况运行时间为 Ω(Ign),我们可以通过对堆中的每个节点设定恰当的值,使得从根节点到叶节点路径上的每个节点都会递归调用 MAX-HEAPIFY。
具体地,我们可以按照以下步骤来设定节点的值:
1.首先,我们将堆看作是一棵完全二叉树,其中每个节点的值都等于它的子节点的最大值(如果它有子节点的话)。
2.对于每个节点,我们设定一个值 X,使得 X = max(x, y),其中 x 和 y 分别是该节点的两个子节点的值(如果它有子节点的话)。
3.然后,我们依次对每个节点调用 MAX-HEAPIFY 函数,并设置它的值等于它的子节点的最大值(如果它有子节点的话)。
4.最后,我们发现每个节点的值都已经被设定为了它的子节点的最大值,因此我们可以直接返回堆的最大值,而不需要再进行任何计算。
由于堆是一棵完全二叉树,因此我们可以通过对每个节点递归地调用 MAX-HEAPIFY 函数,来计算从根节点到叶节点路径上的每个节点的最大值。由于每次调用 MAX-HEAPIFY 函数的时间复杂度为 O(log n),因此整个过程的时间复杂度为 O(n log n)。
另一方面,由于堆的大小为 n,因此我们可以通过直接返回堆的最大值,来计算从根节点到叶节点路径上的每个节点的最大值。这种方法的时间复杂度为 O(n)。
因此,我们可以得出结论,MAX-HEAPIFY 在一个大小为 n 的堆上的最坏情况运行时间为 Ω(n)。
通义千问:
证明:对于一个大小为 n 的有序堆,我们可以使用堆排序的思想将其转化为一个满足 MAX-HEAP 的二叉堆。具体地,我们可以将堆顶元素与堆的尾元素交换,然后将其他元素插入到堆中,以满足 MAX-HEAP 的定义。这样,我们就得到了一个满足 MAX-HEAP 的二叉堆。
对于二叉堆中的每个结点,我们都可以进行一次 MAX-HEAPIFY 操作,以使得其值最大。具体地,我们可以将该结点与其左右子节点进行比较,如果左子节点的值大于该结点,则交换它们的值;如果右子节点的值大于该结点,则交换它们的值。这样,每个结点最终都会被排列在一个满足 MAX-HEAP 的二叉堆中。
因此,对于一个大小为 n 的有序堆,MAX-HEAPIFY 的最坏情况运行时间为 Ω(Ign)。这是因为每个结点最多被交换了一次,并且每次交换都会使得堆的状态更加满足 MAX-HEAP 的定义。因此,最坏情况下,MAX-HEAPIFY 的运行时间为 O(n),即与堆排序的时间相同。

chatgpt:
首先,我们需要理解 MAX-HEAPIFY 运行的场景以及时间复杂度的定义。
MAX-HEAPIFY 是用于维护最大堆性质的过程,它的输入是一个数组表示的堆以及需要调整的节点的索引。最大堆性质要求每个节点的值都大于或等于其子节点的值。
最坏情况运行时间Ω(Ign)的意思是存在一个常数 c,对于任意堆的大小 n,当堆中的元素数量大于 cn 时,MAX-HEAPIFY 的运行时间至少为 Ign。
现在我们构造一个大小为 n 的堆,使得 MAX-HEAPIFY 的最坏情况运行时间为 Ω(Ign)。
假设我们有一个有 n 个节点的最大堆,我们希望在从根节点到每个叶节点的路径上都进行递归调用 MAX-HEAPIFY。我们可以为每个节点设定一个恰当的值,以确保这种情况发生。具体地,我们可以按照以下方式设置节点的值:
-
根节点的值设置为 n。
-
对于任意非叶节点 i,其左子节点和右子节点的值分别为 2i 和 2i + 1。
-
对于任意叶节点 i,其值设置为 n - (i - 2^(k-1)),其中 k 是 i 的从根节点到该叶节点的路径上的步数(包括根节点和叶节点)。
根据这种设置,我们可以发现以下特征:
1.对于从根节点到每个叶节点的路径,每个节点都有一个唯一的值,并且每个节点的值都比其子节点大。
2.由于堆的大小为 n,根节点的值为 n,而叶节点的值为 1。因此,路径的长度从 1 到 log2(n)。
现在,让我们来考虑 MAX-HEAPIFY 在这种堆中的运行情况。从根节点到叶节点的路径上,每个节点的值都比其子节点的值大,因此 MAX-HEAPIFY 函数将会被每个节点递归调用。
对于从根节点到叶节点的路径长度为 h 的情况,MAX-HEAPIFY 的时间复杂度为 O(h)。在我们构造的堆中,从根节点到每个叶节点的路径长度在 1 到 log2(n) 之间,因此 MAX-HEAPIFY 的最坏情况运行时间为 O(log2(n))。
由于 log2(n) = Ω(Ign),我们得出结论:对于一个大小为 n 的堆,MAX-HEAPIFY 的最坏情况运行时间为 Ω(Ign)。
总结
设有n个结点的堆高度为h。由堆的定义可知,根节点到叶子结点最多比较 h 次,即 logn 次。
因此最坏运行时间为Ω(lgn)。