问题描述
永辉自建ES集群CVM 出现IO Hang的情况,子机无法登陆,进程也无法kill掉,需要进行节点重启切换来恢复业务。
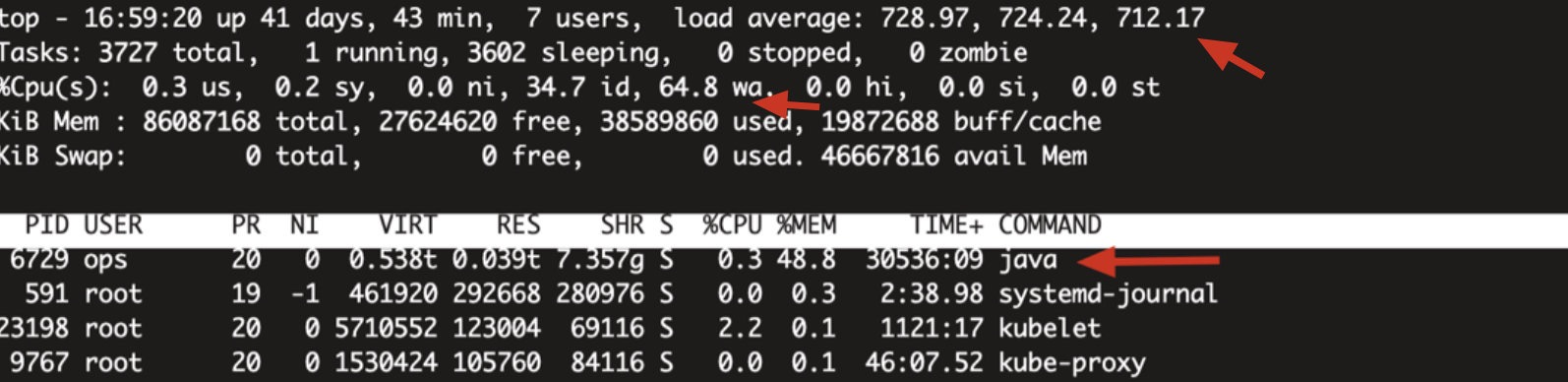
问题背景:2021-05-31日客户侧TKE三台子机的io Await很高,使用的都是本地nvme盘子机,这边登陆了一台机器上面检查发现cpu使用率和io的等待时间都很大,检查进程发现有一个java程序占用了大半(ES的程序),起初步定论就是因为这个ES,把磁盘写死了,cpu负载和io等待时间一直下不去,最终导致磁盘hang死。
问题难点:客户侧那边已经将其ES容器副本关闭,但事实上该容器依然在node节点上正常运行,并且无法正常删除退出,后续在宿主机上找到对应的容器任务kill -9 杀掉之后,但该进程又自动拉起,且成为了僵尸进程,这边最初给客户的建议是重启node节点,彻底关闭ES的容器进程,在观察该node节点还会不会io hang,但客户还是不同意重启,想要先查清楚原因,到底是客户侧自身pod程序问题,还是我方的母机nvme本地盘问题(形成了我方怀疑客户侧代码程序有问题,客户方怀疑是我方产品或机器硬件问题的形式~~)。


后面又检查了磁盘io的情况发现await也并不高,但就是会直接导致系统hang死,继续进一步的调查。

后面又和腾讯的TKE研发协助进行检查syslog是昨天 2021-05-3 07:48 的时候es落下的数据太大,引起xfs_buf崩掉,导致io hang死,所以这边觉得应该是文件系统的问题,这边是打算推荐让客户用ext4试试的,但后面据了解,客户这个集群有15个节点,配置和这三个节点都是一样的xfs,也都是nvme盘,但实际上却只有这三台节点io出了问题,另外12台机器现在也是正常的,所以客户不认同。而且现在的io 等待时间依然很大,es也停不掉。

由于业务一直受到影响,这边也不好再跟客户继续扯皮,直接更换排查思路:开启kdump,当节点hang 死之后让其重启生成 vmcore 内核事件进行分析。
1.安装相应依赖 sudo apt-get install linux-crashdump
2.这个文件里面将 /etc/default/kdump-tools 将USE_KDUMP=1
3. /etc/init.d/kdump-tools start
4.kdump-config load
5.重启节点生效配置 init 6
6.检查是否生效 kdump-config show
7.sysctl -w kernel.hung_task_panic=1
8.sysctl -p
问题过程及原因分析
1) 宕机的原因:
crash> bt
PID: 134 TASK: ffff92baa433da00 CPU: 12 COMMAND: "khungtaskd"
#0 [ffffbbbf06783d00] machine_kexec at ffffffffa2263f53
#1 [ffffbbbf06783d60] __crash_kexec at ffffffffa232bff9
#2 [ffffbbbf06783e28] panic at ffffffffa228e070
#3 [ffffbbbf06783eb0] watchdog at ffffffffa235e4ce
#4 [ffffbbbf06783f08] kthread at ffffffffa22afe81
#5 [ffffbbbf06783f50] ret_from_fork at ffffffffa2c00205
进程长时间处于 D 状态
2)通过分析Kdump日志,系统有大量 hung task,都集中在 xfs 文件系统(其它 hung task 是由 xfs hung task 引起的连锁反应),具体信息如下:
#3911 进程尝试获取 mutex,产生 hungtask
PID: 3911 TASK: ffff92ba6ecd0000 CPU: 5 COMMAND: "nginx-ingress-c"
#0 [ffffbbbf08a1b350] __schedule at ffffffffa2b9c201
#1 [ffffbbbf08a1b3e8] schedule at ffffffffa2b9c83c
#2 [ffffbbbf08a1b3f8] schedule_preempt_disabled at ffffffffa2b9cb1e
#3 [ffffbbbf08a1b408] __mutex_lock at ffffffffa2b9e1dc
#4 [ffffbbbf08a1b498] __mutex_lock_slowpath at ffffffffa2b9e533
#5 [ffffbbbf08a1b4b8] mutex_lock at ffffffffa2b9e56f //slab 回收路径上尝试获取 mutex
#6 [ffffbbbf08a1b4d0] xfs_reclaim_inodes_ag at ffffffffc07567ca [xfs]
#7 [ffffbbbf08a1b658] xfs_reclaim_inodes_nr at ffffffffc07578d3 [xfs]
#8 [ffffbbbf08a1b678] xfs_fs_free_cached_objects at ffffffffc076a7b9 [xfs]
#9 [ffffbbbf08a1b688] super_cache_scan at ffffffffa247d005
#10 [ffffbbbf08a1b6e0] shrink_slab at ffffffffa23e9107
#11 [ffffbbbf08a1b7a0] shrink_slab at ffffffffa23e9389
#12 [ffffbbbf08a1b7b0] shrink_node at ffffffffa23ee33e
#13 [ffffbbbf08a1b838] do_try_to_free_pages at ffffffffa23ee5e9
#14 [ffffbbbf08a1b890] try_to_free_mem_cgroup_pages at ffffffffa23eeafa
#15 [ffffbbbf08a1b910] try_charge at ffffffffa2462a51
#16 [ffffbbbf08a1b9a8] mem_cgroup_try_charge at ffffffffa2467883
#17 [ffffbbbf08a1b9e8] __add_to_page_cache_locked at ffffffffa23d0a28
#18 [ffffbbbf08a1ba40] add_to_page_cache_lru at ffffffffa23d0c5e
#19 [ffffbbbf08a1ba78] ext4_mpage_readpages at ffffffffa2549606
#20 [ffffbbbf08a1bb68] ext4_readpages at ffffffffa25282f3
#21 [ffffbbbf08a1bb78] __do_page_cache_readahead at ffffffffa23e2cc9
#22 [ffffbbbf08a1bc48] filemap_fault at ffffffffa23d249d
#23 [ffffbbbf08a1bd10] ext4_filemap_fault at ffffffffa25330e1
#24 [ffffbbbf08a1bd30] __do_fault at ffffffffa240d564
#25 [ffffbbbf08a1bd58] handle_pte_fault at ffffffffa241262a
#26 [ffffbbbf08a1bdb0] __handle_mm_fault at ffffffffa2413178
#27 [ffffbbbf08a1be58] handle_mm_fault at ffffffffa2413371
#28 [ffffbbbf08a1be90] __do_page_fault at ffffffffa2275aa0
#29 [ffffbbbf08a1bf08] do_page_fault at ffffffffa2275d4e
#30 [ffffbbbf08a1bf38] do_async_page_fault at ffffffffa226c4d1
#31 [ffffbbbf08a1bf50] async_page_fault at ffffffffa2c01635
#3911 进程等待的锁,被 13528 持有, 13528 一直未唤醒
PID: 13528 TASK: ffff92a6cbb35a00 CPU: 3 COMMAND: "elasticsearch[s"
#0 [ffffbbbf10c07330] __schedule at ffffffffa2b9c201
#1 [ffffbbbf10c073c8] schedule at ffffffffa2b9c83c
#2 [ffffbbbf10c073d8] schedule_timeout at ffffffffa2ba07af
#3 [ffffbbbf10c07458] wait_for_completion at ffffffffa2b9d3aa
#4 [ffffbbbf10c074b0] flush_work at ffffffffa22a9ae6 //提交工作队列, 等待完成
#5 [ffffbbbf10c07530] xlog_cil_force_lsn at ffffffffc077593b [xfs]
#6 [ffffbbbf10c075c8] _xfs_log_force_lsn at ffffffffc0773b64 [xfs]
#7 [ffffbbbf10c07648] xfs_log_force_lsn at ffffffffc0773e54 [xfs]
#8 [ffffbbbf10c07680] __xfs_iunpin_wait at ffffffffc075f7f2 [xfs]
#9 [ffffbbbf10c076f8] xfs_iunpin_wait at ffffffffc07629aa [xfs]
#10 [ffffbbbf10c07708] xfs_reclaim_inode at ffffffffc0756212 [xfs]
#11 [ffffbbbf10c07758] xfs_reclaim_inodes_ag at ffffffffc07566e6 [xfs]
#12 [ffffbbbf10c078e0] xfs_reclaim_inodes_nr at ffffffffc07578d3 [xfs]
#13 [ffffbbbf10c07900] xfs_fs_free_cached_objects at ffffffffc076a7b9 [xfs]
#14 [ffffbbbf10c07910] super_cache_scan at ffffffffa247d005
#15 [ffffbbbf10c07968] shrink_slab at ffffffffa23e9107
#16 [ffffbbbf10c07a28] shrink_slab at ffffffffa23e9389
#17 [ffffbbbf10c07a38] shrink_node at ffffffffa23ee33e
#18 [ffffbbbf10c07ac0] do_try_to_free_pages at ffffffffa23ee5e9
#19 [ffffbbbf10c07b18] try_to_free_mem_cgroup_pages at ffffffffa23eeafa
#20 [ffffbbbf10c07b98] try_charge at ffffffffa2462a51
#21 [ffffbbbf10c07c30] memcg_kmem_charge_memcg at ffffffffa2466fec
#22 [ffffbbbf10c07c70] memcg_kmem_charge at ffffffffa24670de
#23 [ffffbbbf10c07ca8] __alloc_pages_nodemask at ffffffffa23dcd5b
#24 [ffffbbbf10c07d10] alloc_pages_current at ffffffffa243b26a
#25 [ffffbbbf10c07d40] pte_alloc_one at ffffffffa227bc97
#26 [ffffbbbf10c07d58] handle_pte_fault at ffffffffa24129d1
#27 [ffffbbbf10c07db0] __handle_mm_fault at ffffffffa2413178
#28 [ffffbbbf10c07e58] handle_mm_fault at ffffffffa2413371
#29 [ffffbbbf10c07e90] __do_page_fault at ffffffffa2275aa0
#30 [ffffbbbf10c07f08] do_page_fault at ffffffffa2275d4e
#31 [ffffbbbf10c07f38] do_async_page_fault at ffffffffa226c4d1
#32 [ffffbbbf10c07f50] async_page_fault at ffffffffa2c01635
PID: 13197 TASK: ffff92ba97878000 CPU: 14 COMMAND: "kworker/14:1"
#0 [ffffbbbf16157900] __schedule at ffffffffa2b9c201
#1 [ffffbbbf16157998] schedule at ffffffffa2b9c83c
#2 [ffffbbbf161579a8] io_schedule at ffffffffa22bd566
#3 [ffffbbbf161579c0] wbt_wait at ffffffffa268c3f7 //IO 卡在 wbt_wait 长时间不完成
#4 [ffffbbbf16157a50] blk_mq_make_request at ffffffffa26644d0
#5 [ffffbbbf16157ad8] generic_make_request at ffffffffa2657714
#6 [ffffbbbf16157b38] submit_bio at ffffffffa2657963
#7 [ffffbbbf16157b88] _xfs_buf_ioapply at ffffffffc0749eee [xfs]
#8 [ffffbbbf16157c48] xfs_buf_submit at ffffffffc074ba85 [xfs]
#9 [ffffbbbf16157c88] xlog_bdstrat at ffffffffc07709bb [xfs]
#10 [ffffbbbf16157ca8] xlog_sync at ffffffffc07726b1 [xfs]
#11 [ffffbbbf16157cf0] xlog_state_release_iclog at ffffffffc077280c [xfs]
#12 [ffffbbbf16157d18] xlog_write at ffffffffc07732f5 [xfs]
#13 [ffffbbbf16157db0] xlog_cil_push at ffffffffc0774f97 [xfs]
#14 [ffffbbbf16157e70] xlog_cil_push_work at ffffffffc0775115 [xfs]
#15 [ffffbbbf16157e80] process_one_work at ffffffffa22a901e
#16 [ffffbbbf16157ec8] worker_thread at ffffffffa22a9282
#17 [ffffbbbf16157f08] kthread at ffffffffa22afe81
#18 [ffffbbbf16157f50] ret_from_fork at ffffffffa2c00205
PID: 12130 TASK: ffff92ba96d0bc00 CPU: 13 COMMAND: "kworker/u40:4"
#0 [ffffbbbf0f22b630] __schedule at ffffffffa2b9c201
#1 [ffffbbbf0f22b6c8] schedule at ffffffffa2b9c83c
#2 [ffffbbbf0f22b6d8] io_schedule at ffffffffa22bd566
#3 [ffffbbbf0f22b6f0] wbt_wait at ffffffffa268c3f7
#4 [ffffbbbf0f22b780] blk_mq_make_request at ffffffffa26644d0
#5 [ffffbbbf0f22b808] generic_make_request at ffffffffa2657714
#6 [ffffbbbf0f22b868] submit_bio at ffffffffa2657963
#7 [ffffbbbf0f22b8c0] xfs_add_to_ioend at ffffffffc0743b17 [xfs]
#8 [ffffbbbf0f22b900] xfs_do_writepage at ffffffffc07443e6 [xfs]
#9 [ffffbbbf0f22b9a8] write_cache_pages at ffffffffa23e147c
#10 [ffffbbbf0f22bac0] xfs_vm_writepages at ffffffffc07440be [xfs]
#11 [ffffbbbf0f22bb38] do_writepages at ffffffffa23e22ab
#12 [ffffbbbf0f22bbb8] __writeback_single_inode at ffffffffa24ac315
#13 [ffffbbbf0f22bc18] writeback_sb_inodes at ffffffffa24acaa1
#14 [ffffbbbf0f22bcf0] __writeback_inodes_wb at ffffffffa24ace37
#15 [ffffbbbf0f22bd38] wb_writeback at ffffffffa24ad1d1
#16 [ffffbbbf0f22bdd8] wb_workfn at ffffffffa24ad96b
#17 [ffffbbbf0f22be80] process_one_work at ffffffffa22a901e
#18 [ffffbbbf0f22bec8] worker_thread at ffffffffa22a9282
#19 [ffffbbbf0f22bf08] kthread at ffffffffa22afe81
从系统 dump 日志看, Linux 内核内部 bug 导致 IO 无法下发,引起 hung task
3)同时发现linux社区中也有类似的bug报告:
Kernel Bug 报告
blk-wbt: fix IO hang in wbt_wait() - Patchwork
https://marc.info/?l=linux-block&m=153221542021033&w=2
Ubuntu 报告
Bug #1805693 “User reports a hang on 18.04 LTS(4.15.18) under a ...” : Bugs : linux package : Ubuntu
社区在 4.15 内核后续也修复了多个 wbt 的缺陷, 可通过 git log block/blk-wbt.c 查看。
4)与永辉团队确认,之前ucloud上面使用的是4.19版本,而当前容器化部署的使用的是4.15内核版本,其中4.19内核修复了wbt的bug:

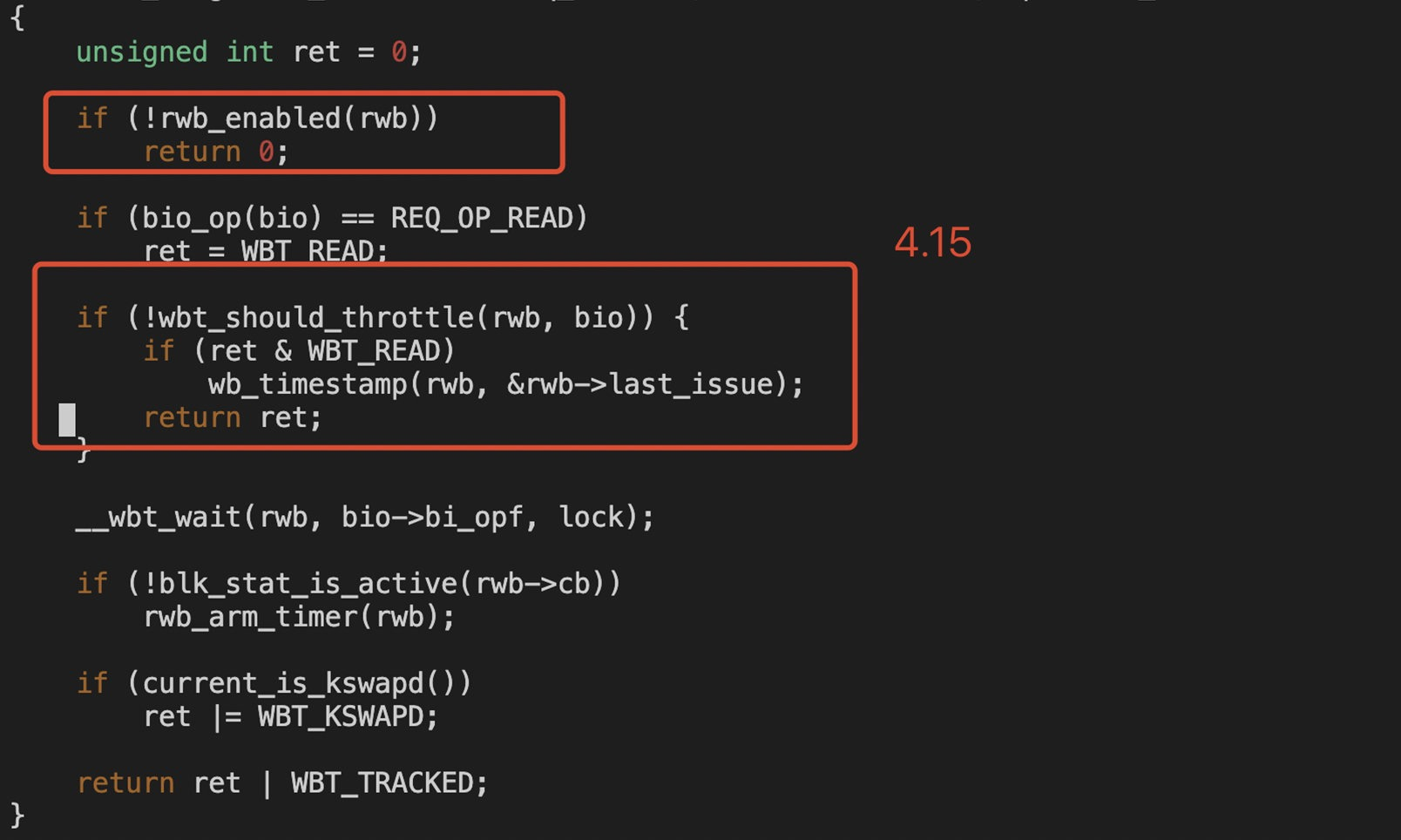
问题原因
Linux 内核 bug 导致 IO 无法下发,引起 hung task
规避建议
建议使用之前业务已经大量使用的稳定版本内核,或最新的 ubuntu 内核
第一步:检查安装的内核版本
要发现当前系统安装的版本
$ uname -sr第二步:升级ubuntu内核
打开 http://kernel.ubuntu.com/~kernel-ppa/mainline/ 并选择列表中需要的版本,根据系统架构下载 .deb 文件:
对于 64 位系统:
$ wget http://kernel.ubuntu.com/~kernel-ppa/mainline/xxxx
$ wget http://kernel.ubuntu.com/~kernel-ppa/mainline/xxxx
$ wget http://kernel.ubuntu.com/~kernel-ppa/mainline/xxxx下载完成这些所有内核文件后,如下安装:$ sudo dpkg -i *.deb
安装完成后,重启并验证新的内核是否已经被使用:$uname-sr