一、DeepSeek概述
2025年1月20日,DeepSeek正式发布 DeepSeek-R1 模型,并同步开源模型权重。DeepSeek-R1在后训练阶段大规模使用了强化学习技术,在仅有极少标注数据的情况下,极大提升了模型推理能力。 DeepSeek-V3和DeepSeek-R1两款大模型,成本价格低廉,性能与OpenAI相当,让硅谷震惊,甚至引发了Meta内部的恐慌,工程师们开始连夜尝试复制DeepSeek的成果。
华为云与硅基流动联合推出了基于昇腾云服务的 DeepSeek R1/V3 推理服务。该服务通过自研推理加速引擎,使 DeepSeek 模型在昇腾云服务上的性能达到了与高端 GPU 部署模型相当的效果。
在DeepSeek没有出现之前,AI模型需要依赖英伟达高端显卡才能运行,企业维护成本很高。但是在DeepSeek出现之后,极大的降低了显卡成本,使用低端的显卡也可以运行AI模型,性能也不差。
二、DeepSeek 蒸馏模型
蒸馏模型的核心优势
-
高效推理:蒸馏模型比原始 DeepSeek-R1 更小,计算效率更高,适合在资源受限的环境中部署。
-
推理能力:尽管规模较小,但蒸馏模型仍保留了强大的推理能力,性能在多个基准测试中优于其他开源模型。
-
开源可用性:蒸馏模型是开源的,允许研究人员和开发人员在各种应用中使用和构建。
蒸馏模型的变体
-
DeepSeek-R1-Distill-Qwen-1.5B
-
DeepSeek-R1-Distill-Qwen-7B
-
DeepSeek-R1-Distill-Qwen-14B
-
DeepSeek-R1-Distill-Qwen-32B
-
DeepSeek-R1-Distill-Llama-8B
-
DeepSeek-R1-Distill-Llama-70B
蒸馏模型的性能表现
-
DeepSeek-R1-Distill-Qwen-7B 在 AIME 2024 上实现了 55.5% Pass@1,超越了 QwQ-32B-Preview。
-
DeepSeek-R1-Distill-Qwen-32B 在 AIME 2024 上实现了 72.6% Pass@1,在 MATH-500 上实现了 94.3% Pass@1。
-
DeepSeek-R1-Distill-Llama-70B 在 AIME 2024 上实现了 70.0% Pass@1,在 MATH-500 上实现了 94.5% Pass@1。
蒸馏模型的应用场景
-
移动设备与边缘计算:适合在移动设备和边缘设备上运行,提供低延迟的实时推理。
-
在线推理服务:如电商推荐和智能问答系统,通过蒸馏技术提高响应速度。
-
成本优化:减少对高性能服务器的依赖,降低云服务提供商的运营成本。
蒸馏模型的部署
-
腾讯云 TI 平台:支持 DeepSeek 系列模型的一键部署,并限时开放了 R1 模型的免费在线体验。
-
华为云昇腾云服务:联合推出基于昇腾云的 DeepSeek R1 & V3 推理服务,提供稳定的生产级推理服务。
接下来,我们主要使用DeepSeek-R1-Distill-Llama-70B蒸馏模型,使用OpenRouter
三、OpenRouter简介
主要功能和特点
-
统一接口:提供标准化的 API,简化了模型的集成和部署过程。
-
多模型支持:支持多种预训练模型,如 OpenAI 的 GPT-4、Claude、Gemini 等。
-
无需 GPU 服务器:通过调用预训练模型的 API,用户无需自建 GPU 服务器。
-
成本优化:提供透明的定价机制,帮助用户在性能和成本之间找到最佳平衡点。
-
易于集成:便于与现有系统集成,适合各种应用场景。
-
免费模型:提供部分免费开源模型,用户可以按需选择。
-
API Key 管理:用户可以创建和管理自己的 API Key,为每个 Key 设置使用额度。
使用场景
-
研究和开发:快速试验和集成不同的大模型 API,进行机器学习、自然语言处理等领域的研究和开发。
-
企业应用:企业通过 OpenRouter 集成多个大模型 API,为应用提供智能化支持,如客服机器人、智能推荐系统等。
-
教育和培训:教育机构和培训机构基于 OpenRouter 的资源,开展 AI 相关的教学和培训活动。
-
内容创作:作家、编辑和内容创作者基于 OpenRouter 接入的模型来辅助写作、编辑和语言润色。
-
语言翻译和本地化:基于支持多语言的模型 API,进行高效的语言翻译和内容本地化。
限制
-
费用:除了标识为“free”的免费模型外,其他模型的调用均会产生费用。
-
支付方式:目前不支持微信、支付宝等支付方式。
-
API Key 限制:API Key 创建后需妥善保管,后续无法查看。
官网和资源
-
官网地址:https://openrouter.ai。
-
文档地址:https://openrouter.ai/docs/quick-start。
我有几台云服务,没有配置GPU显卡,想尝试部署DeepSeek,结果发现下载DeepSeek模型后,大概20GB左右,尝试运行,发现cpu使用率直接到了300%以上,服务器直接卡死了,索性放弃了。
目前能免费使用DeepSeek-R1-Distill-Llama-70B蒸馏模型,主要有2个,OpenRouter,Groq。但是Groq有IP限制,必须是国外ip才能使用。OpenRouter没有IP限制,全球所有国家都可以使用。
使用
登录官网地址:https://openrouter.ai,使用谷歌账户登录,点击搜索框

点击搜索框,下拉列表就会显示模型列表,这里会显示比较热门的几个模型,每月都会有更新的。注意带free的,就是可以免费使用的,其他的是要支付美元使用的。
我们找到1月的DeepSeek: R1 Distill Llama 70B(free)
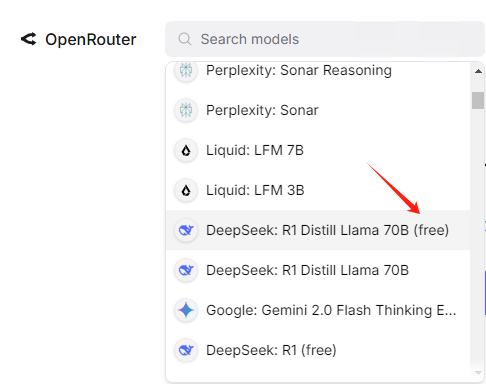
点击API,创建API
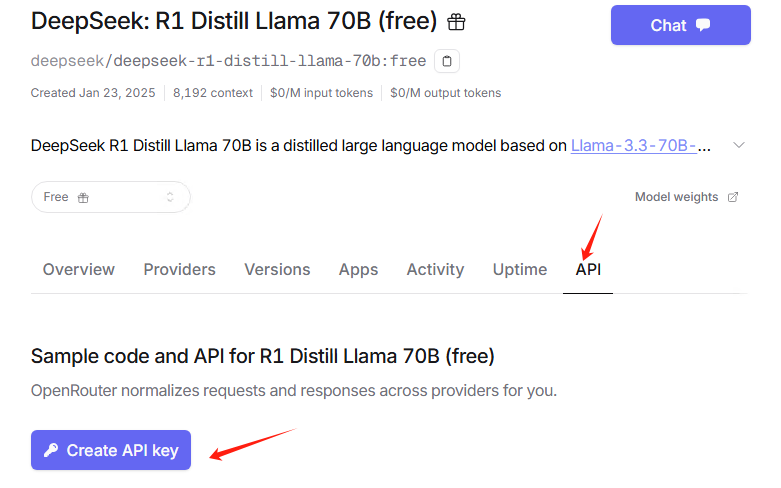
点击创建
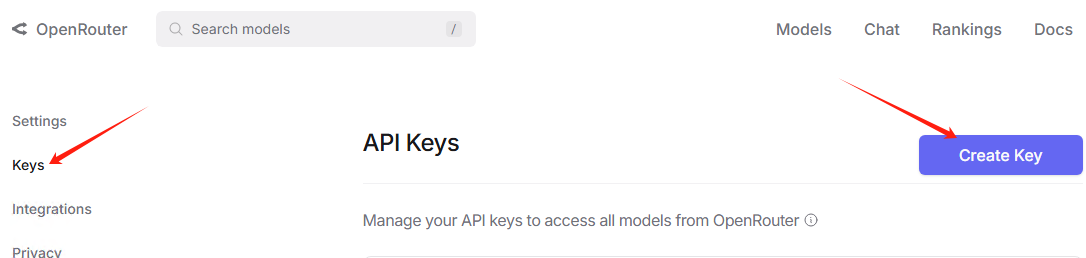
然后输入名字deepseek,名字可以随意。注意credit limit不要填写,表示无限制使用。
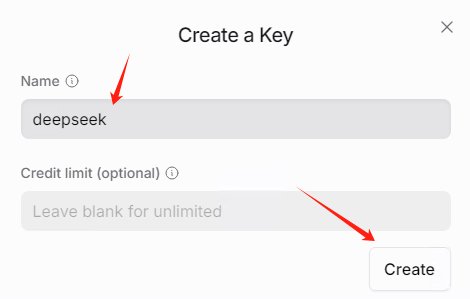
创建之后,会生成一个key,注意自己保存一下。注意:这个key只会显示一次,再次进入就看不到了。
四、Cherry Studio简介
主要功能
-
多模型支持:
-
支持主流云服务(如 OpenAI、Gemini、Anthropic 等)。
-
支持本地模型部署(通过 Ollama)。
-
可同时与多个模型对话,方便比较不同模型的输出。
-
-
AI 助手与对话:
-
内置 300 多个预配置的 AI 助手,涵盖写作、编程、设计等多个领域。
-
支持自定义助手的角色、语气和功能。
-
对话记录可保存,方便随时查阅。
-
-
文档与数据处理:
-
支持文本、图像、PDF、Office 文档等多种文件格式。
-
支持 WebDAV 文件管理与数据备份。
-
支持 Mermaid 图表可视化。
-
-
实用工具集成:
-
全局搜索功能。
-
AI 驱动的翻译功能。
-
代码高亮显示。
-
-
用户体验:
-
跨平台支持(Windows、macOS、Linux)。
-
开箱即用,无需配置环境。
-
支持明暗主题与透明窗口。
-
应用场景
-
文本创作:作家和内容创作者可以快速构思故事、撰写文章。
-
代码生成与调试:开发者可以生成代码片段、进行代码审查。
-
数据分析:研究人员可以进行复杂的数据分析。
-
文献处理:支持多种文件格式,快速提取关键信息。
官网与下载
-
官网地址:https://cherry-ai.com。
-
GitHub 仓库:https://github.com/CherryHQ/cherry-studio。
安装
打开下载页面:https://cherry-ai.com/download.html,下载最新版本安装即可,步骤都是下一步,很简单的。
添加OpenRouter
点击设置按钮,找到OpenRouter,输入API密钥
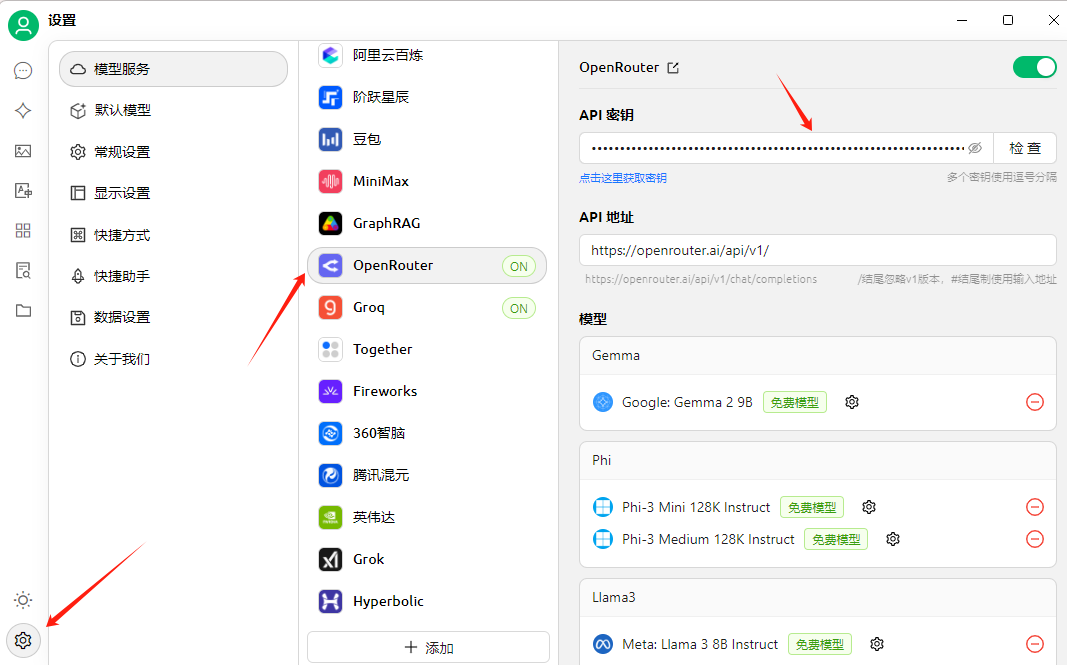
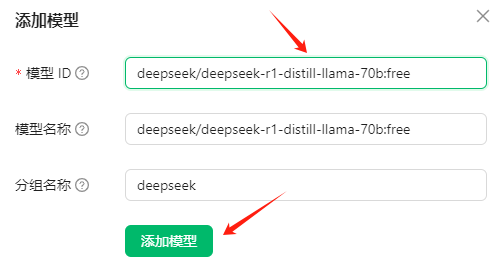
点击添加模型

输入deepseek/deepseek-r1-distill-llama-70b:free
添加完成之后,这里会显示
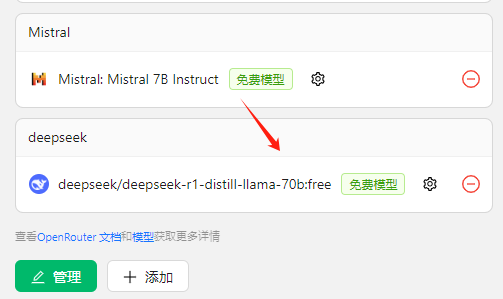
然后点击聊天,选择模型deepseek/deepseek-r1-distill-llama-70b:free,在下面的输入框中,输入:你好,你是谁,等待几秒,就会得到答案。

注意:由于我是国内网络访问的,所以响应速度会有点慢,但是不影响正常使用。某些情况下,会出现以下提示:
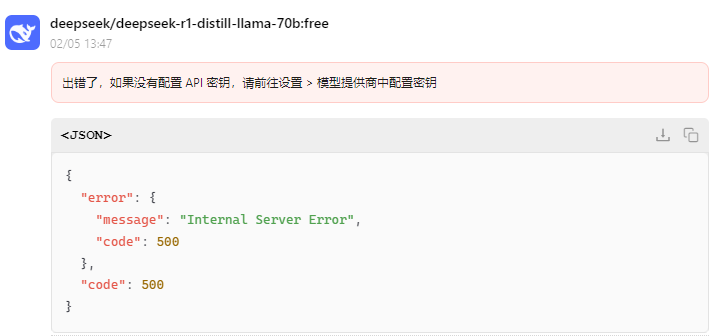
这里可以直接忽略,再重新尝试几次,就恢复正常了。
五、dify接入OpenRouter
我用的是最新dify,版本为:0.15.2
添加OpenRouter,输入api key会提示错误:Credentials validation failed with status code 402
为什么会这样,是因为我用OpenRouter,没有充钱。
查看额度:https://openrouter.ai/credits
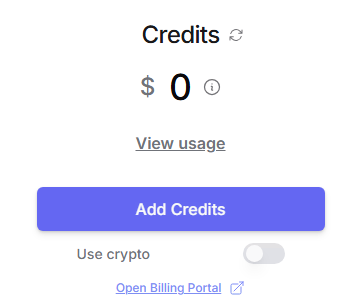
提示0美元,怎么解决呢?其实也简单。
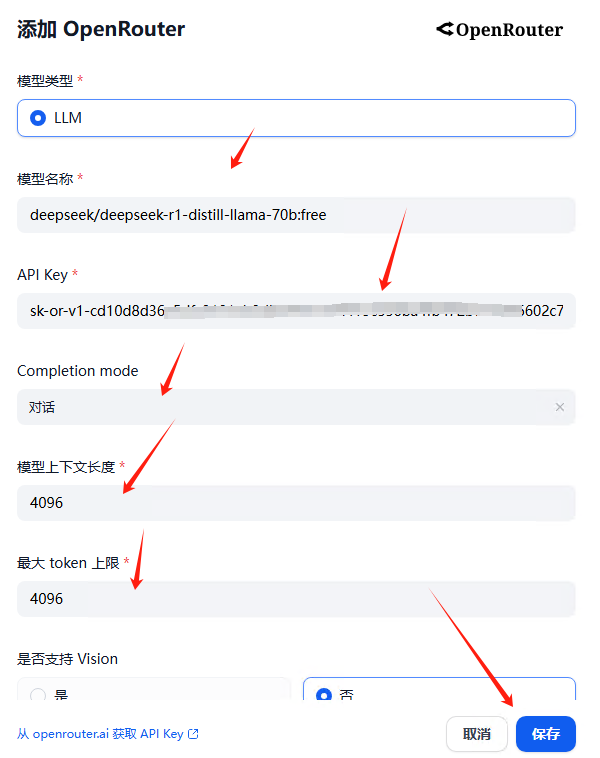
在dify添加模型页面,找到OpenRouter,点击右边的添加模型
输入模型名称:deepseek/deepseek-r1-distill-llama-70b:free
api key等相关信息,注意下面的保存按钮。如果是灰色,就更改一下模型上下文长度等几个参数,直到保存按钮是蓝色时,再把参数改回为正确的。
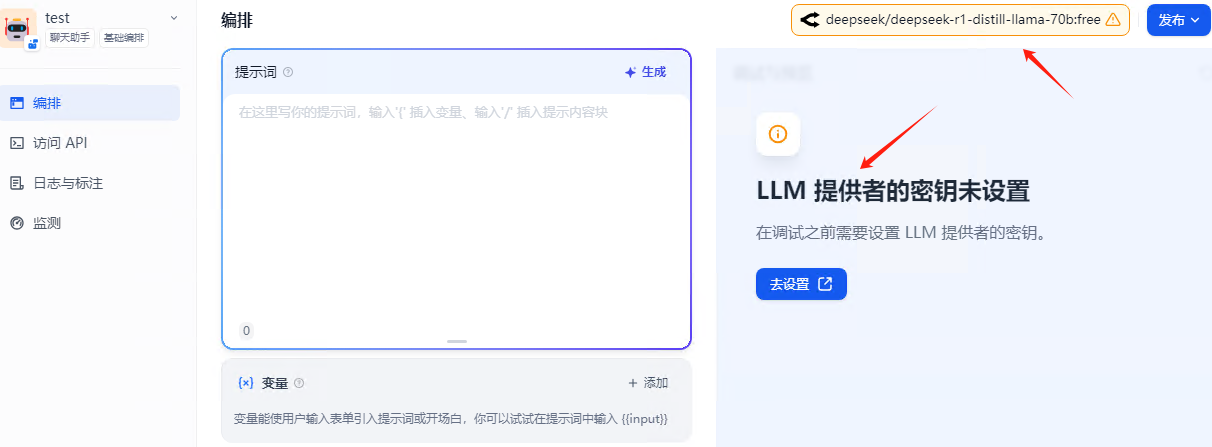
然后点击创建的应用,这里会提示,没有设置密钥,不用管他。
直接运行会话,如果能正常回复,就说明正常了

再问一个问题
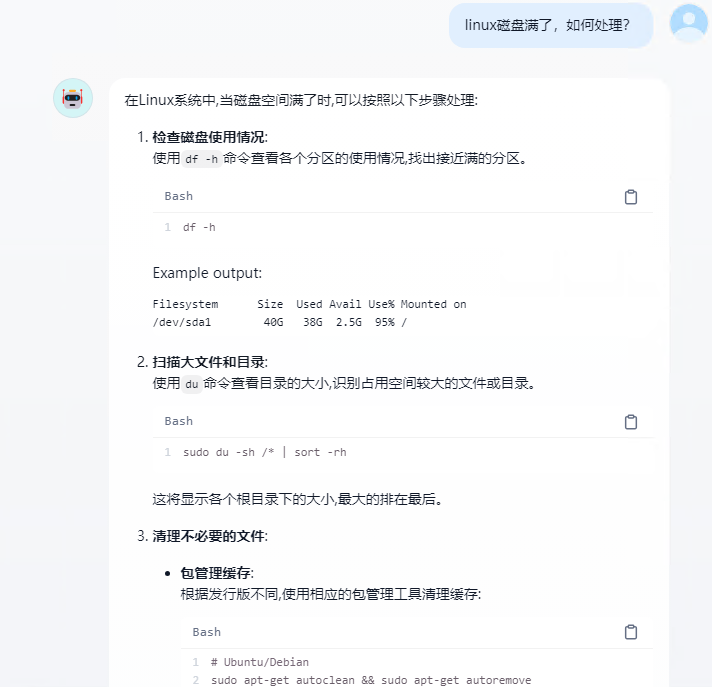
回复比较慢,可能是免费模型用的人太多了,10秒内,就会有回应了。