一、什么是正则表达式
正则表达式(regular expression)又称 规则表达式,是一种文本模式(pattern)。正则表达式使用一个字符串来描述、匹配具有相同规格的字符串,通常被用来检索、替换那些符合某个模式(规则)的文本。正则表达式的核心功能就是处理文本。正则表达式并不仅限于某一种语言,但是在每种语言中有细微的差别。
二、基础语法
2.1、转义字符
使用正则表达式去检索某些特殊字符的时候,需要用到转义字符,否则检索不到结果,甚至会报错;在 Shell 中,$ 具有取变量值的作用,如果我们要在普通字符串中使用 $,需要使用 \ 进行转义。由于在 Shell 字符串字面量中反斜杠是一个转义字符,所以在构建模式串时,你需要使用两个反斜杠来表示一个反斜杠。
echo "abc\$def(123\(456))" | grep "\\\(456"
echo "abc\$def(123\(456))" | grep "\$def"

在 Shell 字符串字面量中,反斜杠本身也是一个转义字符,所以我们需要使用两个反斜杠
\\来表示一个真正的反斜杠\。
2.2、字符匹配符
| 字符匹配符 | 含义 | 实例 | 解释 |
|---|---|---|---|
[] |
可接收的字符列表 | [abc] | a、b、c 中的任意 1 个字符 |
[^] |
不可接收的字符列表 | [^abc] | 除 a、b、c 之外的任意 1 个字符 包括数字和特殊符号 |
- |
连字符 | a-z | 任意一个小写字母 |
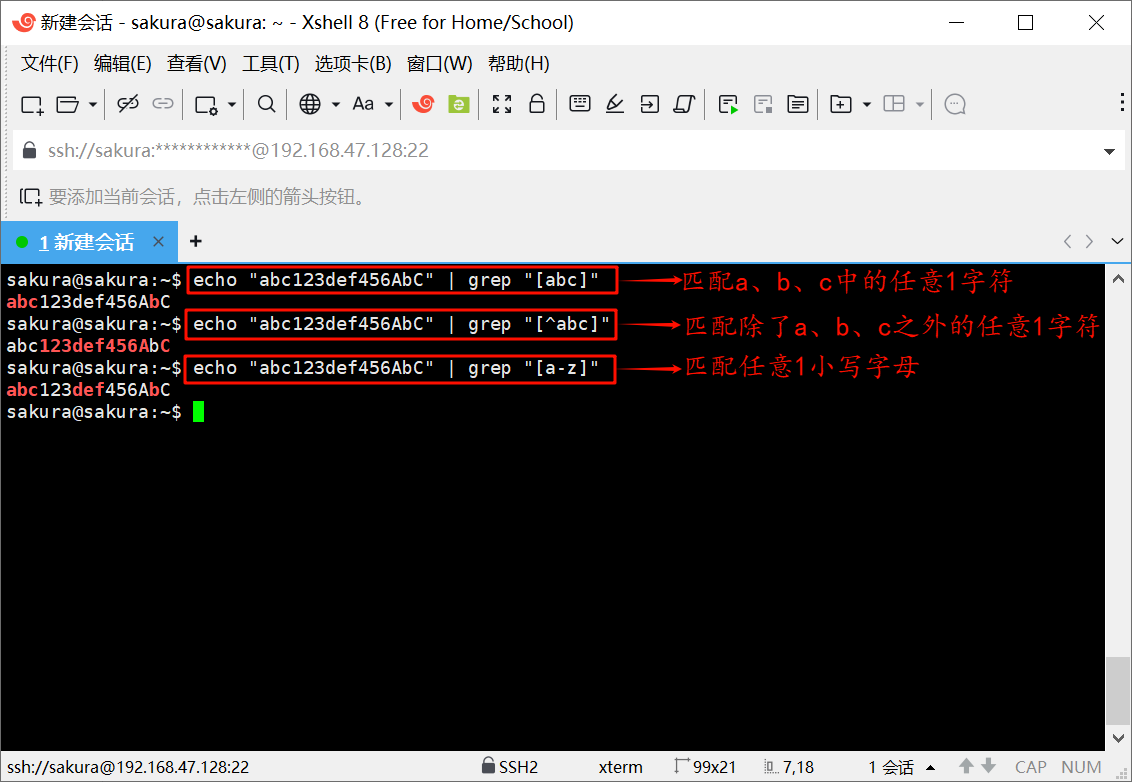
echo "abc123def456AbC" | grep "[abc]"
echo "abc123def456AbC" | grep "[^abc]"
echo "abc123def456AbC" | grep "[a-z]"
2.3、元字符
| 元字符 | 含义 |
|---|---|
. |
匹配单个除换行符以外的任意字符 |
\d |
匹配 0~9 任意一个数字 |
\D |
匹配单个任意非数字字符 |
\s |
匹配任意空白字符 |
\S |
匹配任意不是空白符的字符 |
\w |
匹配字母或数字或下划线的任意字符 |
\W |
匹配任意不是字母、数字、下划线的字符 |
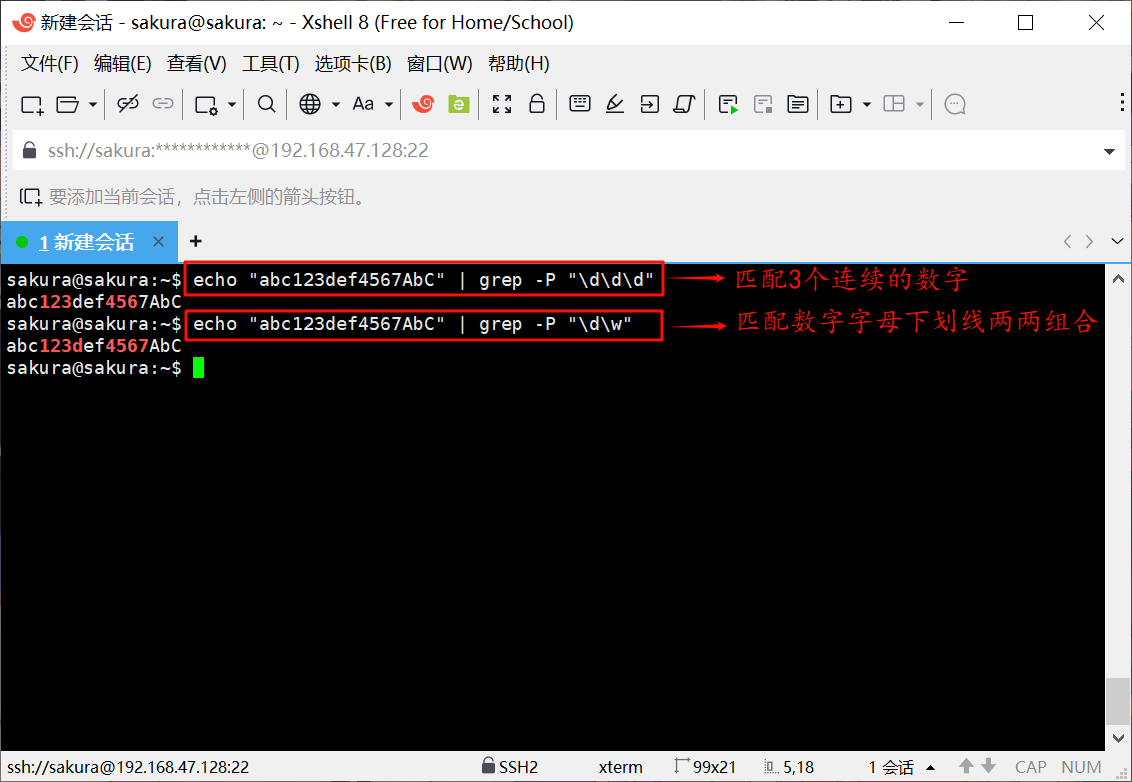
echo "abc123def4567AbC" | grep -P "\d\d\d"
echo "abc123def4567AbC" | grep -P "\d\w"
元字符的大写表示不匹配;
2.4、重复限定符
重复限定符用于指定其前面的字符和组合项连续出现多少次。
| 重复限定符 | 意义 |
|---|---|
? |
0 次 或 1 次 |
* |
0 次 或 多次 |
+ |
1 次 或 多次 |
{n} |
正好出现 n 次 |
{n,} |
至少出现 n 次 |
{n,m} |
出现 n 次 至 m 次 |
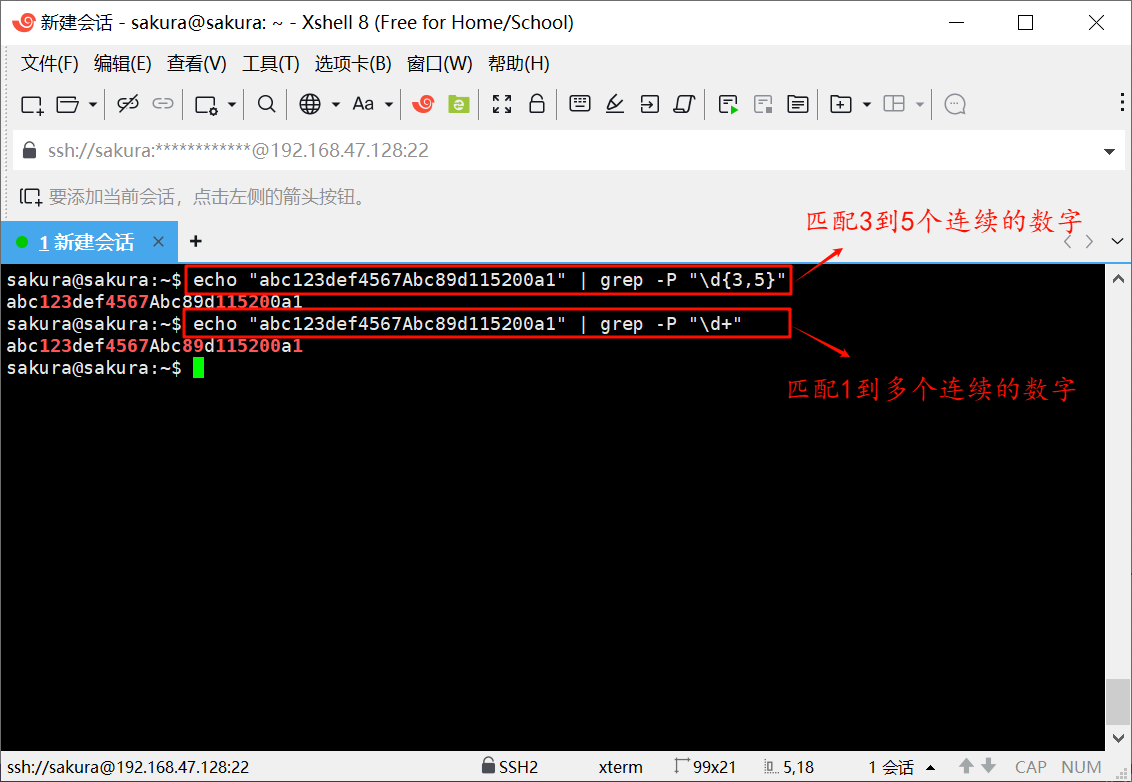
echo "abc123def4567Abc89d115200a1" | grep -P "\d{3,5}"
echo "abc123def4567Abc89d115200a1" | grep -P "\d+"
2.5、定位符
定位符,用来指定要匹配的字符串出现的位置。
| 定位符 | 含义 |
|---|---|
| ^ | 指定起始字符 |
| $ | 指定结束字符 |
| \b | 匹配目标字符串的边界, 边界指的是字串间有空格,或者目标字符串的结束位置 |
| \B | 匹配非单词边界 |
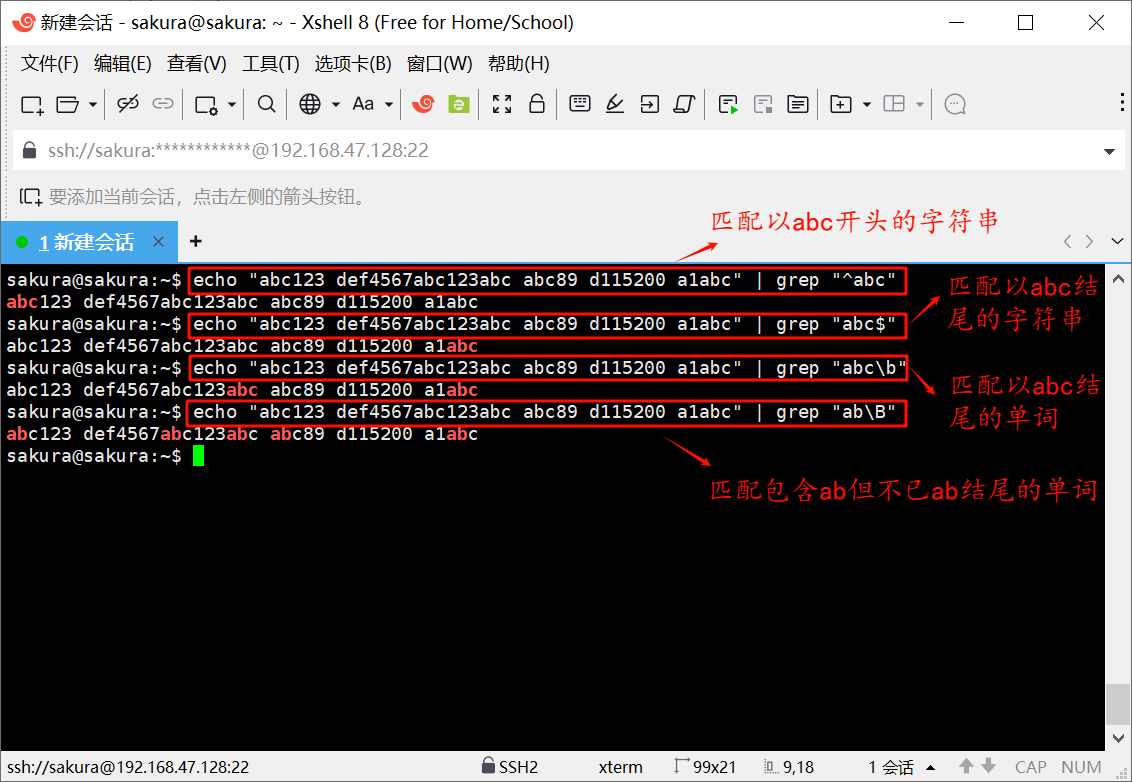
echo "abc123 def4567abc123abc abc89 d115200 a1abc" | grep "^abc"
echo "abc123 def4567abc123abc abc89 d115200 a1abc" | grep "abc$"
echo "abc123 def4567abc123abc abc89 d115200 a1abc" | grep "abc\b"
echo "abc123 def4567abc123abc abc89 d115200 a1abc" | grep "ab\B"
2.6、选择匹配符
正则表达式用符号 | 来表示或,也叫做分支条件,当满足正则表达里的分支条件的任何一种条件时,都会当成匹配成功。
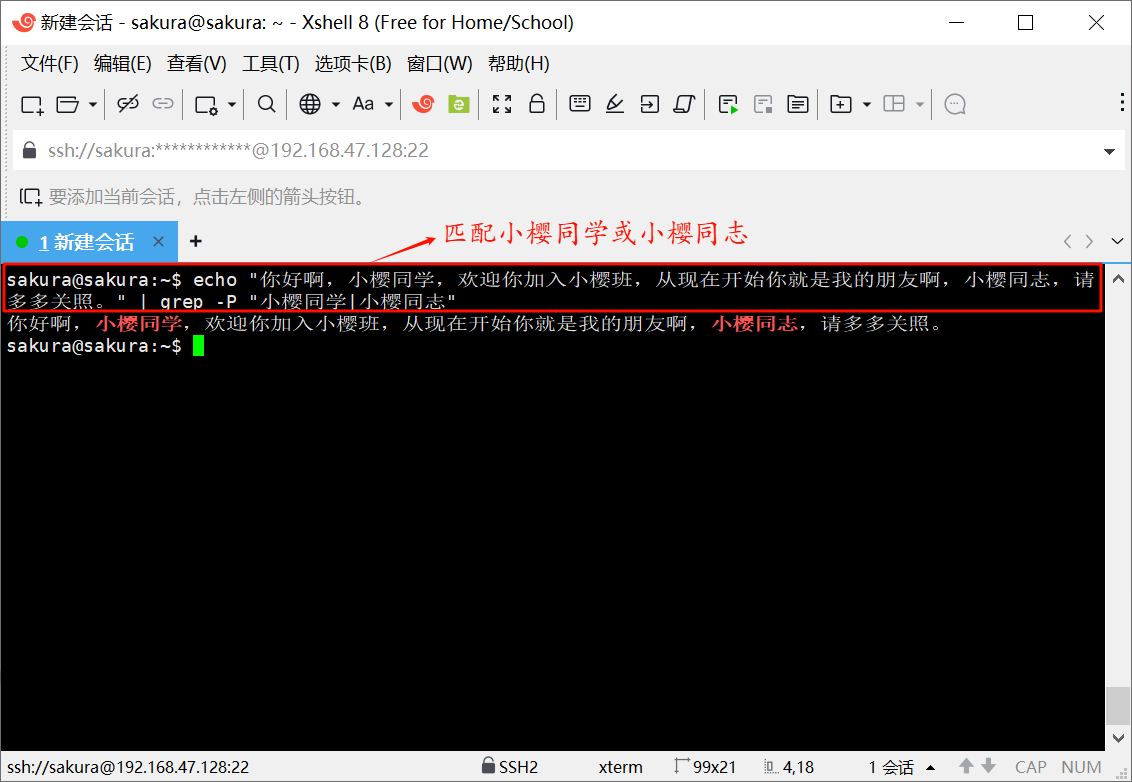
echo "你好啊,小樱同学,欢迎你加入小樱班,从现在开始你就是我的朋友啊,小樱同志,请多多关照。" | grep -P "小樱同学|小樱同志"
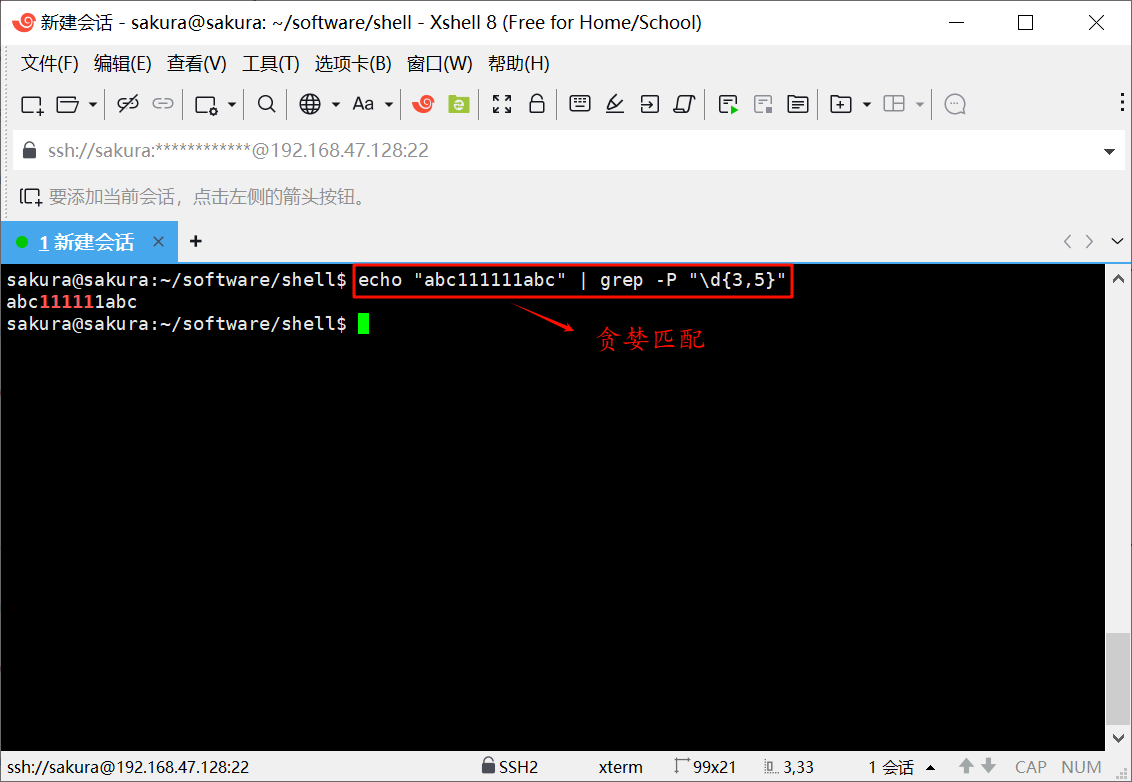
2.7、贪婪匹配
当 ? 元字符紧随任何其它限定符 (*、+、?、{n}、{n,}、{n,m})之后,匹配模式是 “贪婪匹配”。贪婪匹配搜索到、尽可能长的字符串。
echo "abc111111abc" | grep -P "\d{3,5}"

![[Python] 依赖注入的使用,多模块任务隔离](https://img2024.cnblogs.com/blog/2097170/202502/2097170-20250205182505628-1395481090.png)