- 使用 Torch 训练模型
- 定义神经网络
- 加载数据集
- 创建网络模型
- 定义损失函数
- 训练
- 识别手写图像
教程名称:使用 C# 入门深度学习
作者:痴者工良
教程地址:https://torch.whuanle.cn
电子书仓库:https://github.com/whuanle/cs_pytorch
Maomi.Torch 项目仓库:https://github.com/whuanle/Maomi.Torch
使用 Torch 训练模型
本章主要参考《破解深度学习》的第四章,在本章将会实现一个数字分类器,主要包括数据加载和处理、模型训练和保存、预训练模型加载,但是内容跟 开始使用 Torch 一章差不多,只是数据集和网络定义不一样,通过本章的案例帮助读者进一步了解 TorchSharp 以及掌握模型训练的步骤和基础。
本章代码请参考 example2.3。
搭建神经网络的一般步骤:

在上一篇中我们通过示例已经学习到相关的过程,所以本章会在之前的基础上继续讲解一些细节和步骤。
在上一章中,我们学习了如何下载和加载数据集,如果将数据集里面的图片导出,我们可以发现里面都是单个数字。
你可以使用 Maomi.Torch 包中的扩展方法将数据集转存到本地目录中。
for (int i = 0; i < training_data.Count; i++)
{var dic = training_data.GetTensor(i);var img = dic["data"];var label = dic["label"];img.SaveJpeg("imgs/{i}.jpg");
}
如图所示:
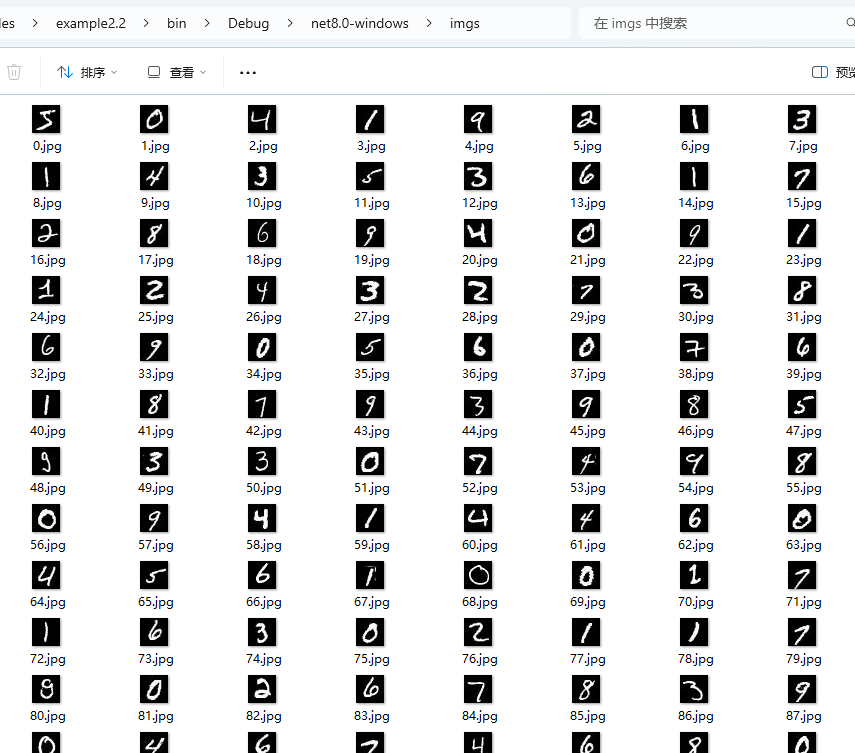
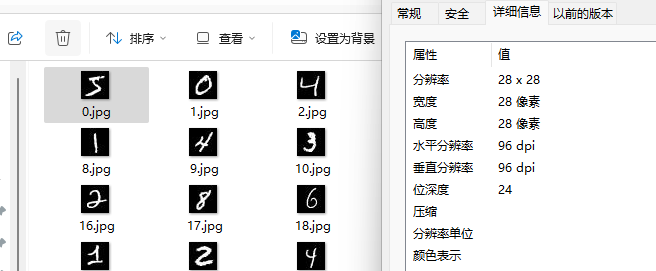
每个图片的大小是 28*28=784,所以神经网络的输入层的大小是 784。
我们直接知道,由于数据集的图片都是 0-9 的数字,都是灰度图像(没有彩色),因此模型训练结果的输出应该是 10 个,也就是神经网络的输出层神经元个数是 10。
神经网络的输入层是要固定大小是,表示神经元的个数输入是固定的,不是随时可以扩充的,也就是一个神经网络不能输入任意大小的图像,这些图像都要经过一定的算法出来,生成与神经网络输入层对应大小的图像。
定义神经网络
第一步,定义我们的网络模型,这是一个全连接网络,由激活函数和三个线性层组成。
该网络模型没有指定输入层和输出层的大小,这样该模型可以适配不同的图像分类任务,开发者在训练和加载模式时,指定输入层和输出层大小即可。
代码如下所示:
using TorchSharp;
using static TorchSharp.torch;using nn = TorchSharp.torch.nn;public class MLP : nn.Module<Tensor, Tensor>, IDisposable
{private readonly int _inputSize;private readonly int _hiddenSize;private readonly int _numClasses;private TorchSharp.Modules.Linear fc1;private TorchSharp.Modules.ReLU relu;private TorchSharp.Modules.Linear fc2;private TorchSharp.Modules.Linear fc3;/// <summary></summary>/// <param name="inputSize">输入层大小,图片的宽*高.</param>/// <param name="hiddenSize">隐藏层大小.</param>/// <param name="outputSize">输出层大小,例如有多少个分类.</param>/// <param name="device"></param>public MLP(int inputSize, int hiddenSize, int outputSize) : base(nameof(MLP)){_inputSize = inputSize;_hiddenSize = hiddenSize;_numClasses = outputSize;// 定义激活函数和线性层relu = nn.ReLU();fc1 = nn.Linear(inputSize, hiddenSize);fc2 = nn.Linear(hiddenSize, hiddenSize);fc3 = nn.Linear(hiddenSize, outputSize);RegisterComponents();}public override torch.Tensor forward(torch.Tensor input){// 一层一层传递// 第一层读取输入,然后传递给激活函数,// 第二层读取第一层的输出,然后传递给激活函数,// 第三层读取第二层的输出,然后生成输出结果var @out = fc1.call(input);@out = relu.call(@out);@out = fc2.call(@out);@out = relu.call(@out);@out = fc3.call(@out);return @out;}protected override void Dispose(bool disposing){base.Dispose(disposing);fc1.Dispose();relu.Dispose();fc2.Dispose();fc3.Dispose();}
}
首先 fc1 作为第一层网络,输入的图像需要转换为一维结构,主要用于接收数据、数据预处理。由于绘图太麻烦了,这里用文字简单说明一下,例如图像是 28*28,也就是每行有 28 个像素,一共 28 行,那么使用一个 784 大小的数组可以将图像的每一行首尾连在一起,放到一个一维数组中。
由于图像都是灰度图像,一个黑白像素值在 0-255 之间(byte 类型),如果使用 [0.0,1.0] 之间表示黑白(float32 类型),那么输入像素表示为灰度,值为 0.0 表示白色,值为 1.0 表示黑色,中间数值表示灰度。
大多数情况下,或者说在本教程中,图像的像素都是使用 float32 类型表示,即 torch.Tensor 存储的图像信息都是 float32 类型表示一个像素。
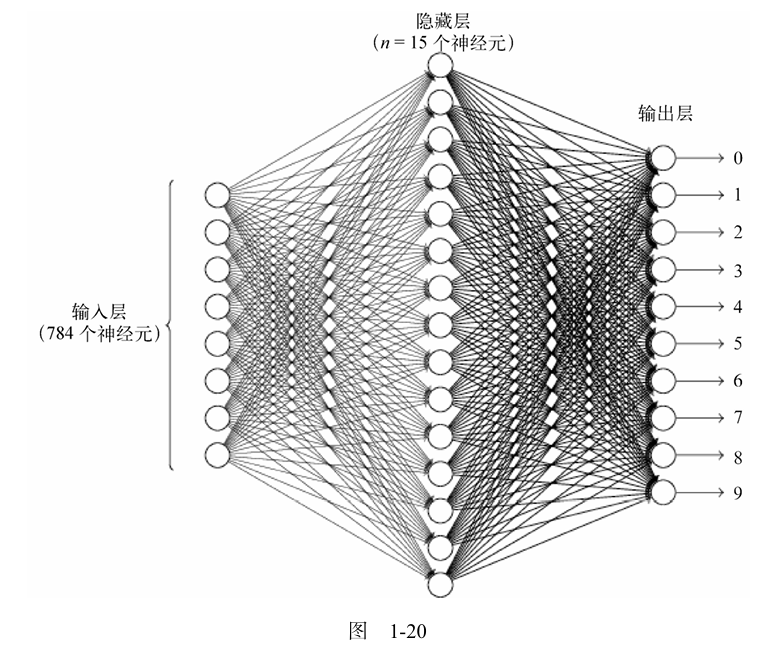
图来自《深入浅出神经网络与深度学习》。
fc2 是隐藏层,在本章示范的网络模型中,隐藏层只有一层,大小是 15 个神经元,承担者特征提取、非线性变换等职责,隐藏层的神经元数量是不定的,主要是根据经验来设置,然后根据训练的模型性能来调整。
fc3 是输出层,根据提取的特征将输出推送到 10 个神经元中,每个神经元表示一个数值,每个神经元都会接收到消息,但是因为不同数字的特征和权重值不一样,所以每个神经元的值都不一样,接收到的值就是表示当前数字的可能性概率。
加载数据集
加载数据集的代码示例如下,由于上一章已经讲解过,因此这里就不再赘述。
// 1. 加载数据集// 从 MNIST 数据集下载数据或者加载已经下载的数据
using var train_data = datasets.MNIST("./mnist/data", train: true, download: true, target_transform: transforms.ConvertImageDtype(ScalarType.Float32));
using var test_data = datasets.MNIST("./mnist/data", train: false, download: true, target_transform: transforms.ConvertImageDtype(ScalarType.Float32));Console.WriteLine("Train data size: " + train_data.Count);
Console.WriteLine("Test data size: " + test_data.Count);var batch_size = 100;
// 分批加载图像,打乱顺序
var train_loader = torch.utils.data.DataLoader(train_data, batchSize: batch_size, shuffle: true, defaultDevice);// 分批加载图像,不打乱顺序
var test_loader = torch.utils.data.DataLoader(test_data, batchSize: batch_size, shuffle: false, defaultDevice);
创建网络模型
由于 MNIST 数据集的图像都是 28*28 的,因此我们创建网络模型实例时,定义输入层为 784 大小。
// 输入层大小,按图片的宽高计算
var input_size = 28 * 28;// 隐藏层大小,大小不固定,可以自己调整
var hidden_size = 15;// 手动配置分类结果个数
var num_classes = 10;var model = new MLP(input_size, hidden_size, num_classes);
model.to(defaultDevice);
定义损失函数
创建损失函数和优化器,这个学习率的大小也是依据经验和性能进行设置,没有什么规律,学习率的作用可以参考梯度下降算法中的知识。
// 创建损失函数
var criterion = nn.CrossEntropyLoss();// 学习率
var learning_rate = 0.001;// 优化器
var optimizer = optim.Adam(model.parameters(), lr: learning_rate);
训练
开始训练模型,对数据集进行 10 轮训练,每轮训练都输出训练结果,这里不使用一张张图片测试准确率,而是一次性识别所有图片(一万张),然后计算平均准确率。
foreach (var epoch in Enumerable.Range(0, num_epochs))
{model.train();int i = 0;foreach (var item in train_loader){var images = item["data"];var lables = item["label"];images = images.reshape(-1, 28 * 28);var outputs = model.call(images);var loss = criterion.call(outputs, lables);optimizer.zero_grad();loss.backward();optimizer.step();i++;if ((i + 1) % 300 == 0){Console.WriteLine("Epoch [{(epoch + 1)}/{num_epochs}], Step [{(i + 1)}/{train_data.Count / batch_size}], Loss: {loss.ToSingle():F4}");}}model.eval();using (torch.no_grad()){long correct = 0;long total = 0;foreach (var item in test_loader){var images = item["data"];var labels = item["label"];images = images.reshape(-1, 28 * 28);var outputs = model.call(images);var (_, predicted) = torch.max(outputs, 1);total += labels.size(0);correct += (predicted == labels).sum().item<long>();}Console.WriteLine("Accuracy of the network on the 10000 test images: {100 * correct / total} %");}
}
保存训练后的模型:
model.save("mnist_mlp_model.dat");
训练信息:
识别手写图像
如下示例图像所示,是一个手写数字。

重新加载模型:
model.save("mnist_mlp_model.dat");
model.load("mnist_mlp_model.dat");// 把模型转为评估模式
model.eval();
使用 Maomi.Torch 导入图片并转为 Tensor,然后将 28*28 转换为以为的 784。
由于加载图像的时候默认是彩色的,所以需要将其转换为灰度图像,即
channels=1。
// 加载图片为张量
var image = MM.LoadImage("5.jpg", channels: 1);
image = image.to(defaultDevice);
image = image.reshape(-1, 28 * 28);
识别图像并输出结果:
using (torch.no_grad())
{var oputput = model.call(image);var prediction = oputput.argmax(dim: 1, keepdim: true);Console.WriteLine("Predicted Digit: " + prediction.item<long>().ToString());
}
当然,对应彩色的图像,也可以这样通过灰度转换处理,再进行层归一化,即可获得对应结构的 torch.Tensor。
image = image.reshape(-1, 28 * 28);var transform = transforms.ConvertImageDtype(ScalarType.Float32);
var img = transform.call(image).unsqueeze(0);
再如下图所示,随便搞了个数字,图像是 212*212,图像格式是 jpg。
注意,由于数据集的图片都是 jpg 格式,因此要识别的图像,也需要使用 jpg 格式。

如下代码所示,首先使用 Maomi.Torch 加载图片,然后调整图像大小为 28*28,以区配网络模型的输入层大小。
// 加载图片为张量
image = MM.LoadImage("6.jpg", channels: 1);
image = image.to(defaultDevice);// 将图像转换为 28*28 大小
image = transforms.Resize(28, 28).call(image);
image = image.reshape(-1, 28 * 28);using (torch.no_grad())
{var oputput = model.call(image);var prediction = oputput.argmax(dim: 1, keepdim: true);Console.WriteLine("Predicted Digit: " + prediction.item<long>().ToString());
}