DeepSeek R1 的推理过程可以类比为人类团队接受和处理任务的方式,尤其是通过 MoE(Mixture of Experts,混合专家系统)和多头注意力(Multi-Head Attention,MLA)等技术和创新。下面我们将逐步解释这些技术的创新点,并对比之前的大模型处理方式和类比的人类模式。
1. MoE(混合专家系统)
人类团队模式:在人类团队中,不同的成员有不同的专长。例如,一个项目团队可能包括项目经理、工程师、设计师和市场专家。每个成员根据自己的专长负责不同的任务,团队通过协作完成复杂的项目。
DeepSeek R1 的 MoE:MoE 架构将模型分成多个“专家”,每个专家负责处理特定类型的输入或任务。在推理过程中,模型会根据输入动态选择最相关的专家来处理任务。这种机制类似于人类团队中根据任务需求分配给最合适的成员来完成。
创新点:
动态路由机制:DeepSeek R1 的 MoE 通过动态路由机制,从多个专家中选择最相关的专家来处理输入。这类似于团队中的项目经理根据任务需求分配给最合适的成员。
专家共享机制:部分专家在不同任务或层间共享参数,提高了资源利用率。这类似于团队中的某些成员在多个项目中发挥作用,共享知识和技能。
对比传统大模型:传统大模型通常使用单一的神经网络处理所有任务,缺乏任务特定的优化。DeepSeek R1 的 MoE 通过专家分工和动态路由,显著提高了任务处理的效率和准确性。
2. 多头注意力(MLA)
人类团队模式:在人类团队中,成员之间通过沟通和协作来完成任务。例如,一个项目团队中的成员会通过会议、邮件等方式交流信息,确保每个人都了解项目的进展和需求。
DeepSeek R1 的 MLA:MLA 机制通过引入潜在向量中介层,将传统的键值(Key-Value)缓存拆解为两步:潜向量生成和差异化重构。这使得模型在处理长文本时,能够更高效地管理和利用上下文信息。
创新点:
低秩压缩:MLA 通过低秩矩阵压缩原始特征,显著减少了推理时的显存占用。这类似于团队成员通过精简的沟通方式,快速传递关键信息。
动态适配:各注意力头基于共享的潜向量进行个性化权重调整,保留了多头注意力的差异性。这类似于团队成员在共享信息的基础上,根据自己的专长进行个性化处理。
对比传统大模型:传统大模型在处理长文本时,需要缓存大量的键值向量,导致显存占用高。MLA 通过低秩压缩和动态适配,显著降低了显存占用,提高了推理效率。
3. RMSNorm 归一化
人类团队模式:在人类团队中,成员需要保持一致的标准和规范,以确保团队的高效运作。例如,一个项目团队中的成员会遵循统一的项目管理流程和质量标准。
DeepSeek R1 的 RMSNorm:RMSNorm 通过均方根统计进行输入缩放,简化了归一化过程,减少了计算量,同时提升了训练稳定性。
创新点:
简化设计:RMSNorm 仅使用均方根统计进行输入缩放,减少了计算量。这类似于团队成员遵循简化的标准和规范,提高了工作效率。
提升稳定性:RMSNorm 通过简化设计,提升了训练的稳定性,确保模型在不同任务上的表现一致。
对比传统大模型:传统大模型通常使用 LayerNorm 进行归一化,计算量较大。RMSNorm 通过简化设计,显著减少了计算量,提高了训练效率。
4. 多令牌预测机制
人类团队模式:在人类团队中,成员会通过预测和规划来提前准备和应对未来的任务。例如,一个项目团队会提前预测项目的需求和风险,制定相应的计划。
DeepSeek R1 的多令牌预测机制:通过多令牌预测训练目标,提高了数据效率和模型表现。这使得模型在处理长文本时,能够更高效地生成和预测内容。
创新点:
提高数据效率:多令牌预测机制通过预测多个令牌,提高了数据的利用率。这类似于团队成员通过提前预测和规划,提高了工作效率。
提升模型表现:多令牌预测机制通过更丰富的训练目标,提升了模型在各种任务上的表现。
对比传统大模型:传统大模型通常使用单令牌预测机制,数据利用率较低。多令牌预测机制通过预测多个令牌,显著提高了数据效率和模型表现。
总结
DeepSeek R1 的推理过程通过 MoE、MLA 和 RMSNorm 等技术和创新,显著提高了模型的效率和性能。这些技术可以类比为人类团队中的分工协作、信息传递和标准规范,使得模型在处理复杂任务时更加高效和准确。与传统大模型相比,DeepSeek R1 通过这些创新点,实现了性能与成本的跨代平衡,重新定义了行业基准。 收起
DeepSeek R1 的推理过程与人类团队处理任务的类比
QQ:273352165
evlon#126.com
转载请注明出处。
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.hqwc.cn/news/880723.html
如若内容造成侵权/违法违规/事实不符,请联系编程知识网进行投诉反馈email:809451989@qq.com,一经查实,立即删除!相关文章
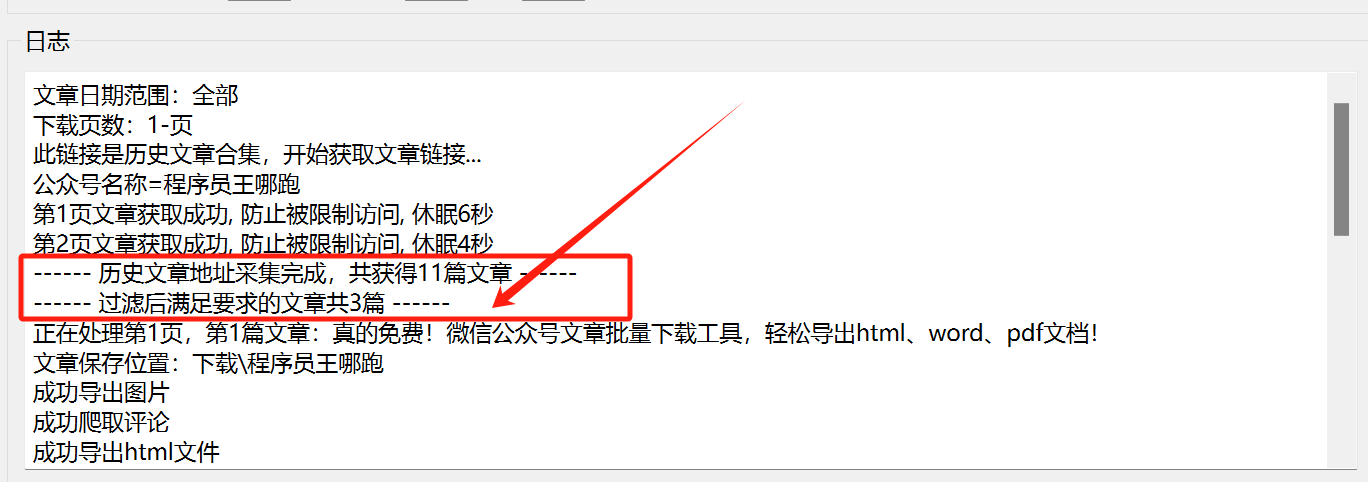
真的不错!微信公众号文章批量下载工具3.0版,支持评论、图片、word文件导出!
一、前言
之前发布的旧版本的说明,可以看下之前发布的这3篇文章:
真的免费!微信公众号文章批量下载工具,轻松导出html、word、pdf文档!
微信公众号文章批量下载工具1.2版本更新,轻松导出html、word、pdf文档!
重磅更新!微信公众号文章批量下载工具2.0版,轻松导出html、…

十二. Redis 集群操作配置(超详细配图,配截图详细说明)
十二. Redis 集群操作配置(超详细配图,配截图详细说明)
@目录十二. Redis 集群操作配置(超详细配图,配截图详细说明)1. 为什么需要集群-高可用性2. 集群概述(及其搭建)3. Redis 集群的使用4. Redis 集群故障恢复5. Redis 集群的 Jedis 开发(使用Java程序连接 Redis 同时开启集…

Docker:Docker搭建Jenkins并共用宿主机Docker部署服务(六)跨服务器远程部署前端服务
前言
继续完成跨服务器远程部署前端服务,Jenkins的搭建与插件安装可以观看上一篇文章:https://www.cnblogs.com/nhdlb/p/18561435
配置SSH远程服务器连接
这里需要安装 SSH 连接的插件,可以观看上一篇文章进行安装。开始配置SSH连接保存!!
新建视图
方便将整个项目的前端和…

一文详解文件摆渡系统是什么?企业需要什么样的文件摆渡产品?
文件摆渡系统是一种旨在实现企业内不同网络、安全域、网段之间的文件传输、同步、共享、管理与处理的工具或平台。文件摆渡系统的主要作用是确保文件能够在不同的存储环境、操作系统、应用程序或部门之间有效传递,同时保障文件的安全性、完整性和合规性。一、文件摆渡系统的核…

IvorySQL 升级指南:从 3.x 到 4.0 的平滑过渡
日前,IvorySQL 4.0 重磅发布,全面支持 PostgreSQL 17,并且增强了对 Oracle 的兼容性。关于 IvorySQL 4.0 的介绍,各位小伙伴可以通过这篇文章回顾:IvorySQL 4.0 发布:全面支持 PostgreSQL 17.
在 IvorySQL 4.0 发布后,有小伙伴私下询问升级方法,那么本篇文章就来详细描…


Ftrans数据跨境传输方案,推动数据跨境安全有序自由流动!
在全球数字经济快速发展的今天,数据跨境传输流动已成为企业国际化不可回避的重要议题。根据权威机构数据,全球跨境数据流量每年增长超过30%,企业数据出境已从简单的信息传输,演变为复杂的合规性管理。
目前,我国数据跨境传输安全管理体系已经初步构建形成。《网络安全法》…

如何打造高效、统一的供应商协同平台?
供应商协同,简单说就是把供需双方的各种“需求”找到对应的“供应”来匹配。这种“需求”和“供应”更多的不是实物,而是资讯、方法和活动。各企业需要一个供应商协同平台实现协同管理,供应链节点各企业形成共同的彼此认同的价值取向和文化理念,建立全面的战略合作伙伴关系…
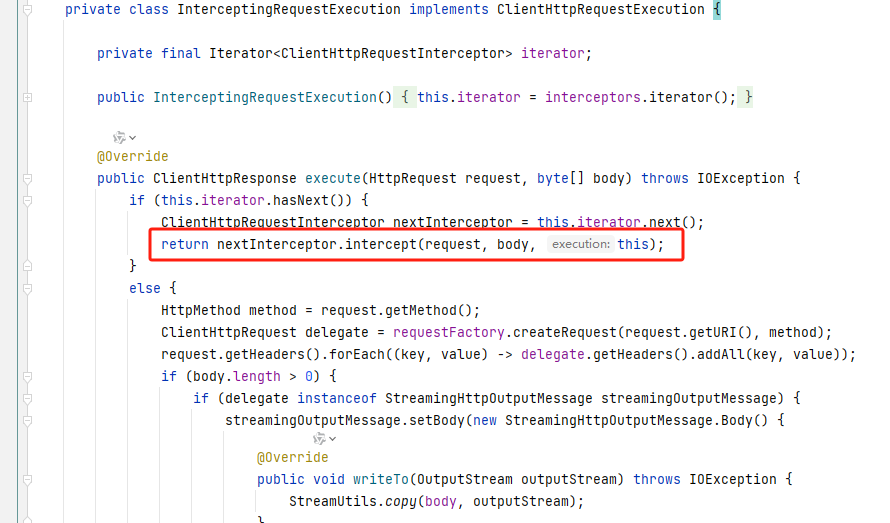
RestClient 通过拦截器实现请求加密
今天我发现了一个关于请求加密的有效写法,特此分享给大家。如果你的加密需求是将请求参数也包含在内,通常情况下,我们需要先将请求体转换成 JSON 格式或其他对象类型,再使用字符串的形式进行加密操作。以下是伪代码示例,展示了这一过程的实现方法:
String payloadString …

读算法简史:从美索不达米亚到人工智能时代10纠错和加密
通信系统需纠错,汉明码优化校验和;互联网设计缺安全,公钥加密RSA成基石,保障数据传输安全,现广泛用于万维网SSL。1. 纠错
1.1. 像互联网这样的通信系统,被设计成将信息的精确副本从发送方传输到接收方
1.2. 通常,接收到的信号会受到电子噪声的污染1.2.1. 噪声是任何会破…