自然语言处理与词嵌入
-
传统的词汇使用词汇表(Vocabulary)来存储,并用one-hot向量表示,向量长度等于词汇表大小,每个单词对应一个独特的索引,只有索引处的值为1,其余全部为0。如果 “max” 在词汇表里的索引是5391,那么对应的one-hot向量为 \(O_{5391}\)。
但是这种表示方法,词汇之间没有任何联系,所有词的内积都是0,不能捕捉词语之间的语义相似性,对模型的泛化能力不强,难以预测相关词的共现关系。
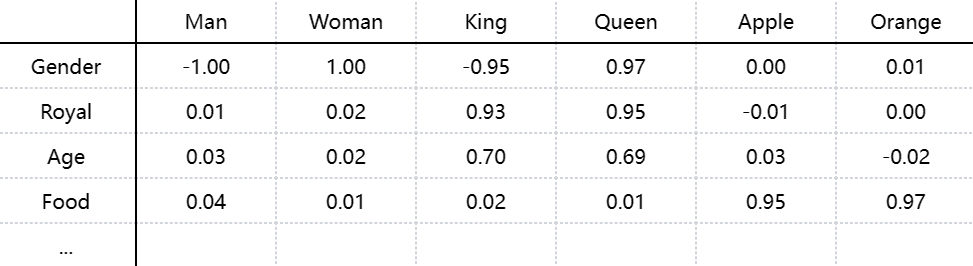
可以使用词嵌入(Word Embeddings),将每个单词表示为高维特征向量。词汇的特征向量通过数据学习得到,向量的不同维度捕捉了语义信息,使得相似的词具有相似的嵌入表示。例如,man的Gender维度为-1,woman的Gender维度为+1,apple的Gender维度为0。这些特征并不是人为设定的,而是通过深度学习模型自动学习得到的。”max” 可以表示为 \(e_{5391}\) 或者 \(e_{max}\) 。
使用词嵌入,可以令相似词的表示更接近。如 apple 和 orange 的嵌入向量会比 king 和 orange 更相似,这使得模型可以更好地泛化,当学习到 “I want a glass of orange juice” 后,模型也能推测出 “I want a glass of apple juice” 是合理的。
词嵌入会学习到 “man 与 woman” 的关系类似于 “king 与 queen” 的关系,这种语义关系可以通过向量计算实现,\(\text{king} - \text{man} + \text{woman} \approx \text{queen}\) 。
-
命名实体识别(Named Entity Recognition, NER)任务的目标是识别文本中的专有名词,例如人名、公司名、地名等。
词嵌入的核心优势是能让算法识别出相似的单词。例如训练数据包含 "Sally Johnson is an orange farmer.",测试数据是 "Robert Lin is an apple farmer.",由于 apple 和 orange 具有相似的嵌入表示,模型可以推断Robert Lin 也很可能是一个人名。进一步泛化到不常见的词,如 "Robert Lin is a durian cultivator.” 。词嵌入可以从大规模语料中学到durian和orange之间,cultivator和farmer之间的关系,这样即使训练集中没有出现过,模型仍然能识别Robert Lin 为人名。
-
NLP任务也可以进行迁移学习。首先,使用 10 亿甚至 100 亿单词的无监督文本数据进行训练,从大规模语料中可以预训练词嵌入。然后将预训练词嵌入应用到下游任务,如命名实体识别,文本摘要,指代消解中。这样即使训练数据很少,模型仍然可以泛化到未见的单词。
在具体训练时,可以选择固定词嵌入,即不更新,更适用于小数据集。也可以选择微调词嵌入,即继续训练词嵌入,更适用于不如预训练语料大的大数据集。大多数情况下,固定词嵌入已足够提供良好的效果!
-
词嵌入是一种高维的向量,可以有效捕捉单词的语义信息。如果想要找到一个单词 \(w\) ,使得:
\[e_{\text{man}} - e_{\text{woman}} \approx e_{\text{king}} - e_w \]变换方程:
\[ e_w = e_{\text{king}} - e_{\text{man}} + e_{\text{woman}} \]这意味着可以用简单的向量运算来推理出单词的类比关系。为了找到最合适的单词 \(w\) ,我们需要计算向量的相似度,可以用余弦相似度来衡量两个向量的夹角:
\[\text{sim}(u, v) = \frac{u \cdot v}{||u||_2 ||v||_2} = \cos(\theta) \]其中, \(u \cdot v\) 是点积, \(||u||_2\) 和 \(||v||_2\) 是L2范数, \(\theta\) 是两个向量之间的夹角。余弦相似度为1表示两个向量完全相同,余弦相似度为0表示两个向量正交,余弦相似度为-1表示两个向量完全相反。
那么在类比推理中,我们希望找到使相似度更高的单位 \(w\) ,从而找到与目标向量最接近的单词。
\[\arg\max_w \text{sim}(e_w, e_{\text{king}} - e_{\text{man}} + e_{\text{woman}}) \]还可以采用t-SNE将高维词嵌入映射到低维,便于可视化,但是t-SNE是非线性映射,可能会破坏原始向量的平行四边形关系。
但是基于词嵌入的类比推理准确率有限,不是所有类比都能正确推理,语义向量受到语料库质量和训练方法的影响。而且未必能处理多义词,bank可以是银行或河岸,向量可能会混淆。也会学习到社会偏见,让 ”doctor” 更接近 ”male”,而 ”nurse” 更接近 ”female”。
-
学习词嵌入的核心目标就是训练一个嵌入矩阵 \(E\) ,用于将单词映射到一个低维向量空间,从而能够捕捉单词之间的语义关系。
假如词汇表包含 \(k\) 个单词,词嵌入是一个 \(m\) 维的向量,那么嵌入矩阵的维度为 \((m,k)\)。假设单词 orange 在词汇表中的索引为 6527,那么one-hot向量为 \(O_{6527}\) ,词嵌入为:
\[e_{orange}=EO_{6527} \]可以理解为矩阵 \(E\) 存储了所有单词的嵌入,乘以 one-hot 向量,相当于索引查询,找到某个单词的词向量。但是在实际应用中,通常直接从 \(E\) 中查找某一列,而不是执行矩阵乘法。
-
语言模型的目标是根据上下文预测下一个单词。通过训练语言模型,我们可以学到单词的语义关系,从而得到高质量的词嵌入向量。
核心思想:如果两个单词在相似的上下文中出现,它们的嵌入向量应该相似。
首先随机初始化嵌入矩阵 \(E\)。语言模型将前面输入的词转换为词嵌入,送入隐藏层,通过 softmax 预测目标词(10000维的概率分布)。训练时使用交叉熵损失来优化,并通过梯度下降更新嵌入矩阵和神经网络参数。
-
不同的上下文选择方法对学习词嵌入的效果有很大影响。最传统的是通过前 \(n\) 个词汇来预测下一个词。
可以使用固定的窗口大小,只看前4个单词来预测下一个单词。维度固定,便于计算,但可能会丢失较长距离的上下文信息。
可以结合左边和右边的词,选取目标词左右各4个词作为上下文,考虑了双向上下文,更适合句子理解。
可以只使用前一个词作为上下文,预测下一个词,计算更简单,但对长距离依赖的学习能力较弱。
可以使用Skip-gram模型,选择目标词的邻近词作为上下文,而不是固定的前 4 个词。该方法计算高效,能够学习到更丰富的词关系。
在选择上下文词的时候,有两种策略:
- 均匀随机采样:直接随机选取语料库中的单词,但是高频词(the、of、to)出现过多,会影响学习效果。
- 平衡采样:减少高频词的采样概率,增加低频词的采样,可以更好地学习罕见词嵌入。
-
除了语言模型外,Word2Vec也可以高效学习词嵌入。主要思想是基于上下文关系来训练单词的嵌入,使得相似单词的向量更接近。
两种主流的方法分别是 Skip-Gram 方法和 CBOW 方法。CBOW 适用于小型数据集,计算更快,但效果略差。Skip-Gram 适用于大规模数据,能学到更好的词嵌入,但计算成本更高。
Skip-Gram 模型首先选择一个上下文词 \(c\) ,如 orange,从上下文词的上下文窗口中随机采样一个词 \(t\) 作为目标词,形成监督学习的训练样本,如
orange - jucie、orange - glass等。通过监督学习任务,可以训练一个模型,使得给定 orange ,能够让正确预测 juice 的概率最大化。但是这个任务本身并不重要,它的目的不是预测,而是帮助学习到更好的词嵌入向量。
在神经网络中,输入上下文词 \(c\) 的 one-hot 向量,通过嵌入层提取词嵌入 ****\(e_c\) ,送入Softmax 层计算目标单词的概率:
\[p(t | c) = \frac{e^{\theta_t^T e_c}}{\sum_{j=1}^{V} e^{\theta_j^T e_c}} \]其中 \(\theta_t\) 是目标词 \(t\) 的参数向量,分母是对整个词汇表求和,计算成本高。
损失函数采用交叉熵损失:
\[L = - \sum_{i=1}^{V} y_i \log \hat{y}_i \]其中 \(y\) 是 one-hot 目标词(例如 juice 对应位置为 1), \(\hat{y}\) 是 softmax 预测概率分布(10,000 维),目标是最小化损失,优化嵌入矩阵 \(E\) 和 softmax 参数 \(\theta\) 。
但是这种方法的 softmax 分母每次都要对整个词汇表求和,计算成本很高,可以通过二叉树分级 softmax 来优化,计算复杂度从 \(O(V)\) 降低到 \(O(\log V)\) 。
- 构建分类树:
- 顶层:先判断单词属于前 5000 个还是后 5000 个。
- 继续分裂:前 5000 个词分成2500 + 2500,直到找到目标词。
- 常见单词放在靠上的节点,罕见单词放在深处:
- 例如 the、of 等高频词可以快速检索。
- durian(榴莲) 之类的罕见词放在深层。
- 构建分类树:
-
可以通过负采样(Negative ampling)的方式,大幅度降低计算成本,并保持高质量的词嵌入学习效果。
在负采样中,将词对分类转换为一个二分类问题,正样本表示真实的
上下文词-目标词词对,负样本表示人为制造的随机词对,即上下文词与随机选取的词的配对。正样本的选取方式与Skip-Gram相同,可以构造为
(orange - juice, 1)。负样本在词汇表中随机选取 \(K\) 个单词,可以构造为(orange - book, 0),有时可能会选到实际语料中出现的单词(比如 "of" 可能本来就在 "orange" 附近),但一般来说这种情况比较少,不会影响训练效果。负采样的监督学习任务为输入词对,输出是否为真实的上下文-目标词对,让模型能够区分真实的正样本词对和随机生成的负样本词对。
在网络中输入上下文词的one-hot向量,送入嵌入层得到词嵌入向量 \(e_c\) ,对于每个目标词(包括正样本和负样本)计算:
\[P(y=1 | c, t) = \sigma(\theta_t^T e_c) \]其中 \(\theta_t\) 是目标词的参数向量, \(e_c\) 是上下文词的嵌入向量。训练的目标是让
orange → juice的概率接近 1,而orange → king****、orange → book这些随机对的概率接近 0。负采样只计算\(1\)个正样本和\(K\)个负样本,计算复杂度大大降低。一般来说,小数据集\(K\)选择5到20,大数据集\(K\)选择2到5。
负样本的选择会影响训练效果:
-
均匀随机采样(不好):
\[P(w) = \frac{1}{|V|} \]- 每个单词被选中的概率相同,但这样不符合自然语言的词频分布。
-
按实际词频采样(不好):
- 直接按照语料库中的出现频率选取负样本。
- 高频词(如 "the"、"of")会被选太多次,影响学习。
-
经验公式(推荐):
\[P(w) = \frac{f(w)^{3/4}}{\sum_{j=1}^{V} f(w_j)^{3/4}} \]- 其中 \(f(w)\) 是单词 \(w\) 在语料中的词频。
- 经验表明 3/4 次方变换可以取得较好的平衡。
-
-
Word2Vec ****主要依赖局部上下文窗口来学习词向量,而 GloVe 采取全局统计方法,利用单词在整个语料库中的共现信息来学习词嵌入。
Glove 核心思想是如果两个单词 \(i\) 和 \(j\) 频繁一起出现,它们应该有相似的向量表示。共现矩阵 \(X_{ij}\) 代表单词 \(j\) 在单词 \(i\) 上下文中出现的次数,反映了单词之间的共现关系。Glove 训练模型,使得单词向量 \(e_i\) 和 \(\theta_j\) 能够准确预测 ****\(X_{ij}\) ****。
GloVe 通过最小化一个二次损失函数,以学习词嵌入:
\[\min \sum_{i=1}^{V} \sum_{j=1}^{V} f(X_{ij}) \left( \theta_{i}^{T} e_{j} + b_i + b_j' - \log X_{ij} \right)^2 \]其中, \(X_{ij}\) 表示单词 \(i\) 和 \(j\) 在语料库中一起出现的次数, \(e_i, \theta_j\) 分别是单词 \(i\) 和单词 \(j\) 的嵌入向量。 \(b_i, b_j'\) 是单词 \(i\) 和 \(j\) 的偏置项, \(f(X_{ij})\) 是权重函数,控制着不同词对的影响,用于避免低频单词对训练的影响过大。
一般情况下,GloVe 采用左右 10 词作为上下文窗口,保证共现矩阵是对称的( \(X_{ij} = X_{ji}\) )。
Glove 希望 \(\theta_i^T e_j\) (即两个单词向量的内积)能够近似 \(\log X_{ij}\) 。如果两个单词共现频率高,内积就要更大。如果共现频率低,内积就要更小。
GloVe Word2Vec 核心方法 基于全局共现矩阵 基于局部上下文窗口 训练方式 通过最小化 \(\log X_{ij}\) 误差 通过预测目标词或上下文 计算方式 矩阵分解方法,优化二次误差 神经网络,优化 softmax 适用场景 适用于小数据集,计算速度快 适用于大数据集,效果更好 计算成本 高效,但需要先计算共现矩阵 计算量大,需要负采样优化 词嵌入向量的不同维度并不一定具有可解释性。在 Word2Vec 中,我们可以通过线性变换来观察特定维度的含义(如性别、职业)。在 GloVe 中,由于全局优化的特性,每个维度可能是多个特征的组合。
-
情感分类(Sentiment Classification)输入一段文本,如 "The dessert is excellent.",输出情感类别(正面、中立、负面)。但是训练数据可能较少,且需要考虑词序。
一种较为简单的方式是基于词嵌入的简单分类器。将句子中的每个单词转换为 one-hot 向量,用预训练的嵌入矩阵映射为词嵌入向量,计算所有单词嵌入的均值,送入softmax分类器,预测情感类别。这种计算适用于不同长度的文本,最终都是固定维度的向量。并且可以使用大规模语料库训练的词向量,提高泛化能力。但是无法考虑次序,"lacking in good taste" 可能被误判为正面评价。
由于简单分类器无法捕捉句子结构和词序,可以使用RNN进行建模。仍然使用 one-hot 向量和嵌入矩阵将单词映射到词向量,依次输入RNN单元,每个时间步更新隐藏状态。
\[h_t = f(W h_{t-1} + U e_t) \]最后一个隐藏状态 \(h_T\) 作为整个句子的表示,再送入softmax分类器,预测情感类别。
这种方法充分考虑词序,能够区分 "not good" 和 "good",能捕捉长距离依赖,比如 "not very delicious",能够理解 "not" 的否定作用。也更适用于长文本,比简单求平均的方法更强大。
-
无论是简单的词向量求均值,还是RNN处理文本,预训练的词嵌入都可以提升分类器的效果。
预训练的词嵌入学习了大量无标签文本的统计信息。即使情感分类的标注数据集很小,也能用大规模语料学到的语义信息来泛化到新数据。例如训练集没有 "absent",但如果 "absent" 在大规模词嵌入训练中学到了 "lacking" 相关的信息,模型仍然可以正确分类 "Completely absent of good service"。
如果只有 10000 训练样本,从头训练词向量可能会过拟合,无法泛化到新单词。将在大规模语料(亿级单词)上预训练的词向量迁移到情感分类任务,即使某些单词未在标注训练集中出现,也可以从语义相似性推断正确类别。
-
模型可能会继承数据中的偏见(bias),甚至强化社会歧视,如性别、种族、性取向、社会经济状态等方面的偏见。Word2Vec 和 GloVe 等词嵌入算法能自动学习单词之间的关系,如:
\[\text{man} : \text{woman} \quad \text{king} : \text{queen} \]但如果类比推理:
\[\text{man} : \text{computer programmer} \quad \Rightarrow \quad \text{woman} : ? \]可能的输出是 "homemaker"(家庭主妇) 而不是 "computer programmer",这反映了模型在学习时继承了社会偏见。
由于词嵌入来自大量文本数据(如网络文章、书籍、社交媒体),这些数据反映了人类社会中的偏见。词嵌入模型通过统计方法自动推断单词关系,但并不理解单词的实际意义。它可能错误地强化数据中的偏见,即使文本数据中的偏见很微弱。
如何判断哪些词需要去偏?可以训练一个分类器来识别哪些词是性别相关的(如 "he-she"、"mother-father")。绝大多数词(如 "doctor")应该是性别中立的,而极少数词(如 "grandmother")应该保持性别区分。
词嵌入去偏流程:
-
识别偏见方向。计算具有性别区分性的词向量差,如:
\[e_{\text{he}} - e_{\text{she}}, \quad e_{\text{male}} - e_{\text{female}} \]取平均值,得到偏见方向(bias subspace)。这个偏见方向可以看作一个1 维子空间(如果只考虑性别)。其他词的偏见分量都投影在这个方向上,我们可以用奇异值分解的方法消除这个分量。
-
中和偏见。目的是让性别不应影响的词(如 "doctor"、"babysitter")在性别方向上的分量变成 0,使其保持性别中立。
计算 "doctor" 在偏见方向上的投影:
\[e_{\text{doctor, bias}} = \text{Proj}{\text{bias}}(e{\text{doctor}}) \]从 "doctor" 的词向量中减去这个投影:
\[e_{\text{doctor}} = e_{\text{doctor}} - e_{\text{doctor, bias}} \]这样,"doctor" 在性别方向上的偏见成分被消除。
-
均衡步骤。对于一组性别相关的单词(如 "grandmother-grandfather"、"niece-nephew"),它们应该等距于所有性别中立的词(如 "babysitter"),这样可以避免性别偏见影响词的语义关系。
计算 "grandmother" 和 "grandfather" 的中心点:
\[e_{\text{center}} = \frac{e_{\text{grandmother}} + e_{\text{grandfather}}}{2} \]将 "grandmother" 和 "grandfather" 调整到等距于这个中心点:
\[e_{\text{grandmother}} = e_{\text{center}} + \alpha \cdot v \\ e_{\text{grandfather}} = e_{\text{center}} - \alpha \cdot v \]这样,它们不会影响 "babysitter" 这样的性别中立词的关联性。
-
![[20052006-ptz] Decoding Martian Messages](https://s21.ax1x.com/2025/02/09/pEmxYes.png)






![[PyTorch] DDP源码阅读](https://img2024.cnblogs.com/blog/1077980/202502/1077980-20250209154436183-2053702575.png)

![P2024 [NOI2001] 食物链(带权并查集)](https://img2024.cnblogs.com/blog/3599636/202502/3599636-20250209153500389-919040341.png)
